 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Variable Impedance Control via Inverse Reinforcement Learning for Force-Related Tasks
Paper and Code
Feb 13, 2021
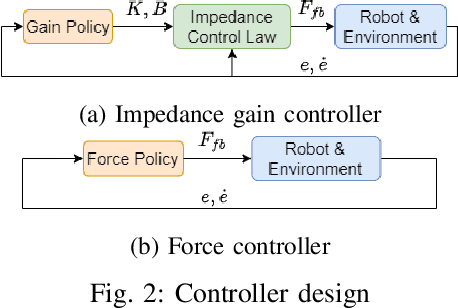
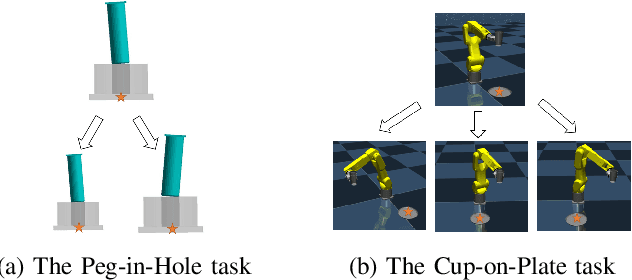
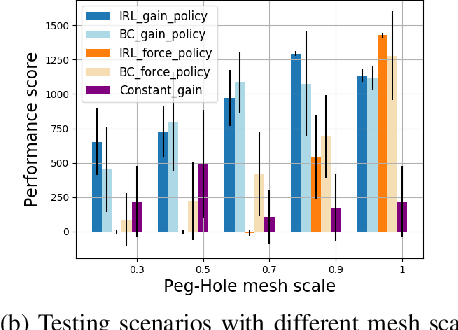
Many manipulation tasks require robots to interact with unknown environments. In such applications, the ability to adapt the impedance according to different task phases and environment constraints is crucial for safety and performance. Although many approaches based on deep reinforcement learning (RL) and learning from demonstration (LfD) have been proposed to obtain variable impedance skills on contact-rich manipulation tasks, these skills are typically task-specific and could be sensitive to changes in task settings. This paper proposes an inverse reinforcement learning (IRL) based approach to recover both the variable impedance policy and reward function from expert demonstrations. We explore different action space of the reward functions to achieve a more general representation of expert variable impedance skills. Experiments on two variable impedance tasks (Peg-in-Hole and Cup-on-Plate) were conducted in both simulations and on a real FANUC LR Mate 200iD/7L industrial robot. The comparison results with behavior cloning and force-based IRL proved that the learned reward function in the gain action space has better transferability than in the force space. Experiment videos are available at https://msc.berkeley.edu/research/impedance-irl.html.