 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoM2P: Egocentric Multimodal Multitask Pretraining
Jun 09, 2025

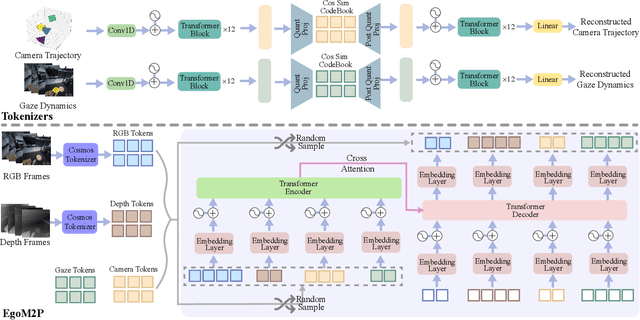
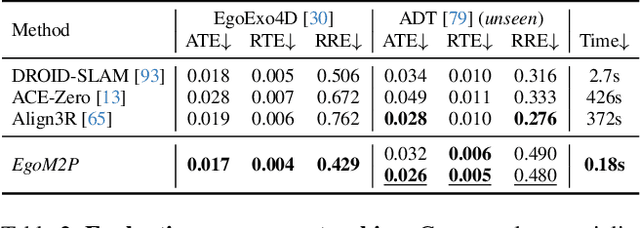
Understanding multimodal signals in egocentric vision, such as RGB video, depth, camera poses, and gaze, is essential for applications in augmented reality, robotics, and human-computer interaction. These capabilities enable systems to better interpret the camera wearer's actions, intentions, and surrounding environment. However, building large-scale egocentric multimodal and multitask models presents unique challenges. Egocentric data are inherently heterogeneous, with large variations in modality coverage across devices and settings. Generating pseudo-labels for missing modalities, such as gaze or head-mounted camera trajectories, is often infeasible, making standard supervised learning approaches difficult to scale. Furthermore, dynamic camera motion and the complex temporal and spatial structure of first-person video pose additional challenges for the direct application of existing multimodal foundation models. To address these challenges, we introduce a set of efficient temporal tokenizers and propose EgoM2P, a masked modeling framework that learns from temporally aware multimodal tokens to train a large, general-purpose model for egocentric 4D understanding. This unified design supports multitasking across diverse egocentric perception and synthesis tasks, including gaze prediction, egocentric camera tracking, and monocular depth estimation from egocentric video. EgoM2P also serves as a generative model for conditional egocentric video synthesis. Across these tasks, EgoM2P matches or outperforms specialist models while being an order of magnitude faster. We will fully open-source EgoM2P to support the community and advance egocentric vision research. Project page: https://egom2p.github.io/
Object-X: Learning to Reconstruct Multi-Modal 3D Object Representations
Jun 05, 2025Learning effective multi-modal 3D representations of objects is essential for numerous applications, such as augmented reality and robotics. Existing methods often rely on task-specific embeddings that are tailored either for semantic understanding or geometric reconstruction. As a result, these embeddings typically cannot be decoded into explicit geometry and simultaneously reused across tasks. In this paper, we propose Object-X, a versatile multi-modal object representation framework capable of encoding rich object embeddings (e.g. images, point cloud, text) and decoding them back into detailed geometric and visual reconstructions. Object-X operates by geometrically grounding the captured modalities in a 3D voxel grid and learning an unstructured embedding fusing the information from the voxels with the object attributes. The learned embedding enables 3D Gaussian Splatting-based object reconstruction, while also supporting a range of downstream tasks, including scene alignment, single-image 3D object reconstruction, and localization. Evaluations on two challenging real-world datasets demonstrate that Object-X produces high-fidelity novel-view synthesis comparable to standard 3D Gaussian Splatting, while significantly improving geometric accuracy. Moreover, Object-X achieves competitive performance with specialized methods in scene alignment and localization. Critically, our object-centric descriptors require 3-4 orders of magnitude less storage compared to traditional image- or point cloud-based approaches, establishing Object-X as a scalable and highly practical solution for multi-modal 3D scene representation.
Spot-On: A Mixed Reality Interface for Multi-Robot Cooperation
May 28, 2025



Recent progress in mixed reality (MR) and robotics is enabling increasingly sophisticated forms of human-robot collaboration. Building on these developments, we introduce a novel MR framework that allows multiple quadruped robots to operate in semantically diverse environments via a MR interface. Our system supports collaborative tasks involving drawers, swing doors, and higher-level infrastructure such as light switches. A comprehensive user study verifies both the design and usability of our app, with participants giving a "good" or "very good" rating in almost all cases. Overall, our approach provides an effective and intuitive framework for MR-based multi-robot collaboration in complex, real-world scenarios.
MP-SfM: Monocular Surface Priors for Robust Structure-from-Motion
Apr 28, 2025While Structure-from-Motion (SfM) has seen much progress over the years, state-of-the-art systems are prone to failure when facing extreme viewpoint changes in low-overlap, low-parallax or high-symmetry scenarios. Because capturing images that avoid these pitfalls is challenging, this severely limits the wider use of SfM, especially by non-expert users. We overcome these limitations by augmenting the classical SfM paradigm with monocular depth and normal priors inferred by deep neural networks. Thanks to a tight integration of monocular and multi-view constraints, our approach significantly outperforms existing ones under extreme viewpoint changes, while maintaining strong performance in standard conditions. We also show that monocular priors can help reject faulty associations due to symmetries, which is a long-standing problem for SfM. This makes our approach the first capable of reliably reconstructing challenging indoor environments from few images. Through principled uncertainty propagation, it is robust to errors in the priors, can handle priors inferred by different models with little tuning, and will thus easily benefit from future progress in monocular depth and normal estimation. Our code is publicly available at https://github.com/cvg/mpsfm.
ForesightNav: Learning Scene Imagination for Efficient Exploration
Apr 22, 2025Understanding how humans leverage prior knowledge to navigate unseen environments while making exploratory decisions is essential for developing autonomous robots with similar abilities. In this work, we propose ForesightNav, a novel exploration strategy inspired by human imagination and reasoning. Our approach equips robotic agents with the capability to predict contextual information, such as occupancy and semantic details, for unexplored regions. These predictions enable the robot to efficiently select meaningful long-term navigation goals, significantly enhancing exploration in unseen environments. We validate our imagination-based approach using the Structured3D dataset, demonstrating accurate occupancy prediction and superior performance in anticipating unseen scene geometry. Our experiments show that the imagination module improves exploration efficiency in unseen environments, achieving a 100% completion rate for PointNav and an SPL of 67% for ObjectNav on the Structured3D Validation split. These contributions demonstrate the power of imagination-driven reasoning for autonomous systems to enhance generalizable and efficient exploration.
Compile Scene Graphs with Reinforcement Learning
Apr 18, 2025Next token prediction is the fundamental principle for training large language models (LLMs), and reinforcement learning (RL) further enhances their reasoning performance. As an effective way to model language, image, video, and other modalities, the use of LLMs for end-to-end extraction of structured visual representations, such as scene graphs, remains underexplored. It requires the model to accurately produce a set of objects and relationship triplets, rather than generating text token by token. To achieve this, we introduce R1-SGG, a multimodal LLM (M-LLM) initially trained via supervised fine-tuning (SFT) on the scene graph dataset and subsequently refined using reinforcement learning to enhance its ability to generate scene graphs in an end-to-end manner. The SFT follows a conventional prompt-response paradigm, while RL requires the design of effective reward signals. Given the structured nature of scene graphs, we design a graph-centric reward function that integrates node-level rewards, edge-level rewards, and a format consistency reward. Our experiments demonstrate that rule-based RL substantially enhances model performance in the SGG task, achieving a zero failure rate--unlike supervised fine-tuning (SFT), which struggles to generalize effectively. Our code is available at https://github.com/gpt4vision/R1-SGG.
MAPLE: Encoding Dexterous Robotic Manipulation Priors Learned From Egocentric Videos
Apr 08, 2025



Large-scale egocentric video datasets capture diverse human activities across a wide range of scenarios, offering rich and detailed insights into how humans interact with objects, especially those that require fine-grained dexterous control. Such complex, dexterous skills with precise controls are crucial for many robotic manipulation tasks, yet are often insufficiently addressed by traditional data-driven approaches to robotic manipulation. To address this gap, we leverage manipulation priors learned from large-scale egocentric video datasets to improve policy learning for dexterous robotic manipulation tasks. We present MAPLE, a novel method for dexterous robotic manipulation that exploits rich manipulation priors to enable efficient policy learning and better performance on diverse, complex manipulation tasks. Specifically, we predict hand-object contact points and detailed hand poses at the moment of hand-object contact and use the learned features to train policies for downstream manipulation tasks. Experimental results demonstrate the effectiveness of MAPLE across existing simulation benchmarks, as well as a newly designed set of challenging simulation tasks, which require fine-grained object control and complex dexterous skills. The benefits of MAPLE are further highlighted in real-world experiments using a dexterous robotic hand, whereas simultaneous evaluation across both simulation and real-world experiments has remained underexplored in prior work.
Robust Human Registration with Body Part Segmentation on Noisy Point Clouds
Apr 04, 2025



Registering human meshes to 3D point clouds is essential for applications such as augmented reality and human-robot interaction but often yields imprecise results due to noise and background clutter in real-world data. We introduce a hybrid approach that incorporates body-part segmentation into the mesh fitting process, enhancing both human pose estimation and segmentation accuracy. Our method first assigns body part labels to individual points, which then guide a two-step SMPL-X fitting: initial pose and orientation estimation using body part centroids, followed by global refinement of the point cloud alignment. Additionally, we demonstrate that the fitted human mesh can refine body part labels, leading to improved segmentation. Evaluations on the cluttered and noisy real-world datasets InterCap, EgoBody, and BEHAVE show that our approach significantly outperforms prior methods in both pose estimation and segmentation accuracy. Code and results are available on our project website: https://segfit.github.io
WildGS-SLAM: Monocular Gaussian Splatting SLAM in Dynamic Environments
Apr 04, 2025We present WildGS-SLAM, a robust and efficient monocular RGB SLAM system designed to handle dynamic environments by leveraging uncertainty-aware geometric mapping. Unlike traditional SLAM systems, which assume static scenes, our approach integrates depth and uncertainty information to enhance tracking, mapping, and rendering performance in the presence of moving objects. We introduce an uncertainty map, predicted by a shallow multi-layer perceptron and DINOv2 features, to guide dynamic object removal during both tracking and mapping. This uncertainty map enhances dense bundle adjustment and Gaussian map optimization, improving reconstruction accuracy. Our system is evaluated on multiple datasets and demonstrates artifact-free view synthesis. Results showcase WildGS-SLAM's superior performance in dynamic environments compared to state-of-the-art methods.
FlowR: Flowing from Sparse to Dense 3D Reconstructions
Apr 02, 2025



3D Gaussian splatting enables high-quality novel view synthesis (NVS) at real-time frame rates. However, its quality drops sharply as we depart from the training views. Thus, dense captures are needed to match the high-quality expectations of some applications, e.g. Virtual Reality (VR). However, such dense captures are very laborious and expensive to obtain. Existing works have explored using 2D generative models to alleviate this requirement by distillation or generating additional training views. These methods are often conditioned only on a handful of reference input views and thus do not fully exploit the available 3D information, leading to inconsistent generation results and reconstruction artifacts. To tackle this problem, we propose a multi-view, flow matching model that learns a flow to connect novel view renderings from possibly sparse reconstructions to renderings that we expect from dense reconstructions. This enables augmenting scene captures with novel, generated views to improve reconstruction quality. Our model is trained on a novel dataset of 3.6M image pairs and can process up to 45 views at 540x960 resolution (91K tokens) on one H100 GPU in a single forward pass. Our pipeline consistently improves NVS in sparse- and dense-view scenarios, leading to higher-quality reconstructions than prior works across multiple, widely-used NVS benchmarks.