 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUI-KOBE: Knowledge-Oriented Behavior Exploration for Lightweight Graph-Guided GUI Agents
May 28, 2026Recent advances in mobile GUI agents have shown strong potential for automating mobile tasks, but most effective systems still depend on large vision-language models for screenshot understanding and long-horizon planning. Small GUI agents that can be deployed directly on mobile devices are more attractive for practical use, offering lower inference cost and better protection of sensitive on-device information. However, due to limited model capacity, such lightweight agents remain unreliable when planning and executing GUI tasks end-to-end from screenshots alone. We propose Knowledge-Oriented Behavior Exploration (\textbf{UI-KOBE}), a framework that improves lightweight mobile GUI agents with reusable app-specific graph knowledge. UI-KOBE first autonomously explores a mobile application and constructs an app knowledge graph, where nodes represent distinct UI states and edges represent executable transitions. At runtime, a lightweight GUI agent uses the graph as external guidance: given a user task and the current screenshot, it identifies the current graph node and selects among self-loop actions, neighboring transitions, task completion, or fallback free actions associated with that node. By supporting runtime decisions with app-specific graph guidance, UI-KOBE reduces the burden of end-to-end GUI planning and helps lightweight models perform mobile GUI tasks more effectively, offering a practical step toward efficient, interpretable, and privacy-conscious on-device GUI agents.
PIRA-Bench: A Transition from Reactive GUI Agents to GUI-based Proactive Intent Recommendation Agents
Mar 09, 2026Current Graphical User Interface (GUI) agents operate primarily under a reactive paradigm: a user must provide an explicit instruction for the agent to execute a task. However, an intelligent AI assistant should be proactive, which is capable of anticipating user intentions directly from continuous visual inputs, such as mobile or desktop screenshots, and offering timely recommendations without explicit user prompting. Transitioning to this proactive paradigm presents significant challenges. Real-world screen activity is rarely linear; it consists of long-horizon trajectories fraught with noisy browsing, meaningless actions, and multithreaded task-switching. To address this gap, we introduce PIRA-Bench (Proactive Intent Recommendation Agent Benchmark), a novel benchmark for evaluating multimodal large language models (MLLMs) on continuous, weakly-supervised visual inputs. Unlike reactive datasets, PIRA-Bench features complex trajectories with multiple interleaved intents and noisy segments with various user profile contexts, challenging agents to detect actionable events while fitting to user preferences. Furthermore, we propose the PIRF baseline, a memory-aware, state-tracking framework that empowers general MLLMs to manage multiple task threads and handle misleading visual inputs. PIRA-Bench serves as an initial step toward robust and proactive GUI-based personal assistants.
UI-Mem: Self-Evolving Experience Memory for Online Reinforcement Learning in Mobile GUI Agents
Feb 05, 2026Online Reinforcement Learning (RL) offers a promising paradigm for enhancing GUI agents through direct environment interaction. However, its effectiveness is severely hindered by inefficient credit assignment in long-horizon tasks and repetitive errors across tasks due to the lack of experience transfer. To address these challenges, we propose UI-Mem, a novel framework that enhances GUI online RL with a Hierarchical Experience Memory. Unlike traditional replay buffers, our memory accumulates structured knowledge, including high-level workflows, subtask skills, and failure patterns. These experiences are stored as parameterized templates that enable cross-task and cross-application transfer. To effectively integrate memory guidance into online RL, we introduce Stratified Group Sampling, which injects varying levels of guidance across trajectories within each rollout group to maintain outcome diversity, driving the unguided policy toward internalizing guided behaviors. Furthermore, a Self-Evolving Loop continuously abstracts novel strategies and errors to keep the memory aligned with the agent's evolving policy. Experiments on online GUI benchmarks demonstrate that UI-Mem significantly outperforms traditional RL baselines and static reuse strategies, with strong generalization to unseen applications. Project page: https://ui-mem.github.io
UI-Genie: A Self-Improving Approach for Iteratively Boosting MLLM-based Mobile GUI Agents
May 27, 2025In this paper, we introduce UI-Genie, a self-improving framework addressing two key challenges in GUI agents: verification of trajectory outcome is challenging and high-quality training data are not scalable. These challenges are addressed by a reward model and a self-improving pipeline, respectively. The reward model, UI-Genie-RM, features an image-text interleaved architecture that efficiently pro- cesses historical context and unifies action-level and task-level rewards. To sup- port the training of UI-Genie-RM, we develop deliberately-designed data genera- tion strategies including rule-based verification, controlled trajectory corruption, and hard negative mining. To address the second challenge, a self-improvement pipeline progressively expands solvable complex GUI tasks by enhancing both the agent and reward models through reward-guided exploration and outcome verification in dynamic environments. For training the model, we generate UI- Genie-RM-517k and UI-Genie-Agent-16k, establishing the first reward-specific dataset for GUI agents while demonstrating high-quality synthetic trajectory gen- eration without manual annotation. Experimental results show that UI-Genie achieves state-of-the-art performance across multiple GUI agent benchmarks with three generations of data-model self-improvement. We open-source our complete framework implementation and generated datasets to facilitate further research in https://github.com/Euphoria16/UI-Genie.
UI-R1: Enhancing Action Prediction of GUI Agents by Reinforcement Learning
Mar 27, 2025



The recent DeepSeek-R1 has showcased the emergence of reasoning capabilities in LLMs through reinforcement learning (RL) with rule-based rewards. Building on this idea, we are the first to explore how rule-based RL can enhance the reasoning capabilities of multimodal large language models (MLLMs) for graphic user interface (GUI) action prediction tasks. To this end, we curate a small yet high-quality dataset of 136 challenging tasks, encompassing five common action types on mobile devices. We also introduce a unified rule-based action reward, enabling model optimization via policy-based algorithms such as Group Relative Policy Optimization (GRPO). Experimental results demonstrate that our proposed data-efficient model, UI-R1-3B, achieves substantial improvements on both in-domain (ID) and out-of-domain (OOD) tasks. Specifically, on the ID benchmark AndroidControl, the action type accuracy improves by 15%, while grounding accuracy increases by 10.3%, compared with the base model (i.e. Qwen2.5-VL-3B). On the OOD GUI grounding benchmark ScreenSpot-Pro, our model surpasses the base model by 6.0% and achieves competitive performance with larger models (e.g., OS-Atlas-7B), which are trained via supervised fine-tuning (SFT) on 76K data. These results underscore the potential of rule-based reinforcement learning to advance GUI understanding and control, paving the way for future research in this domain.
A3: Android Agent Arena for Mobile GUI Agents
Jan 02, 2025



AI agents have become increasingly prevalent in recent years, driven by significant advancements in the field of large language models (LLMs). Mobile GUI agents, a subset of AI agents, are designed to autonomously perform tasks on mobile devices. While numerous studies have introduced agents, datasets, and benchmarks to advance mobile GUI agent research, many existing datasets focus on static frame evaluations and fail to provide a comprehensive platform for assessing performance on real-world, in-the-wild tasks. To address this gap, we present Android Agent Arena (A3), a novel evaluation platform. Unlike existing in-the-wild systems, A3 offers: (1) meaningful and practical tasks, such as real-time online information retrieval and operational instructions; (2) a larger, more flexible action space, enabling compatibility with agents trained on any dataset; and (3) automated business-level LLM-based evaluation process. A3 includes 21 widely used general third-party apps and 201 tasks representative of common user scenarios, providing a robust foundation for evaluating mobile GUI agents in real-world situations and a new autonomous evaluation process for less human labor and coding expertise. The project is available at \url{https://yuxiangchai.github.io/Android-Agent-Arena/}.
NYU-VPR: Long-Term Visual Place Recognition Benchmark with View Direction and Data Anonymization Influences
Oct 18, 2021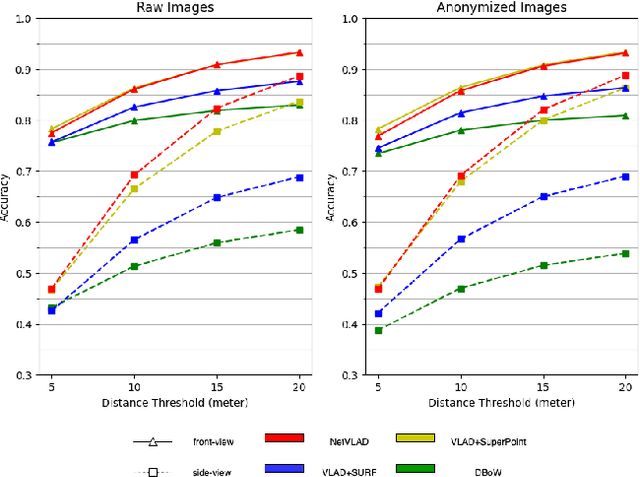
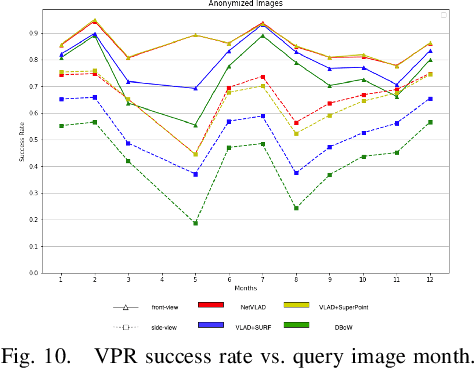
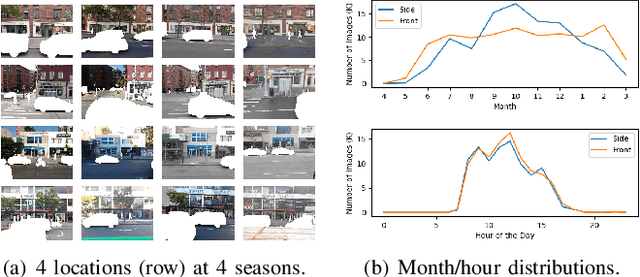

Visual place recognition (VPR) is critical in not only localization and mapping for autonomous driving vehicles, but also assistive navigation for the visually impaired population. To enable a long-term VPR system on a large scale, several challenges need to be addressed. First, different applications could require different image view directions, such as front views for self-driving cars while side views for the low vision people. Second, VPR in metropolitan scenes can often cause privacy concerns due to the imaging of pedestrian and vehicle identity information, calling for the need for data anonymization before VPR queries and database construction. Both factors could lead to VPR performance variations that are not well understood yet. To study their influences, we present the NYU-VPR dataset that contains more than 200,000 images over a 2km by 2km area near the New York University campus, taken within the whole year of 2016. We present benchmark results on several popular VPR algorithms showing that side views are significantly more challenging for current VPR methods while the influence of data anonymization is almost negligible, together with our hypothetical explanations and in-depth analysis.