 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIMO-DBnet: Multi-channel Input and Multiple Outputs DOA-aware Beamforming Network for Speech Separation
Dec 07, 2022Recently, many deep learning based beamformers have been proposed for multi-channel speech separation. Nevertheless, most of them rely on extra cues known in advance, such as speaker feature, face image or directional information. In this paper, we propose an end-to-end beamforming network for direction guided speech separation given merely the mixture signal, namely MIMO-DBnet. Specifically, we design a multi-channel input and multiple outputs architecture to predict the direction-of-arrival based embeddings and beamforming weights for each source. The precisely estimated directional embedding provides quite effective spatial discrimination guidance for the neural beamformer to offset the effect of phase wrapping, thus allowing more accurate reconstruction of two sources' speech signals. Experiments show that our proposed MIMO-DBnet not only achieves a comprehensive decent improvement compared to baseline systems, but also maintain the performance on high frequency bands when phase wrapping occurs.
The ISCSLP 2022 Intelligent Cockpit Speech Recognition Challenge (ICSRC): Dataset, Tracks, Baseline and Results
Nov 03, 2022This paper summarizes the outcomes from the ISCSLP 2022 Intelligent Cockpit Speech Recognition Challenge (ICSRC). We first address the necessity of the challenge and then introduce the associated dataset collected from a new-energy vehicle (NEV) covering a variety of cockpit acoustic conditions and linguistic contents. We then describe the track arrangement and the baseline system. Specifically, we set up two tracks in terms of allowed model/system size to investigate resource-constrained and -unconstrained setups, targeting to vehicle embedded as well as cloud ASR systems respectively. Finally we summarize the challenge results and provide the major observations from the submitted systems.
I4U System Description for NIST SRE'20 CTS Challenge
Nov 02, 2022



This manuscript describes the I4U submission to the 2020 NIST Speaker Recognition Evaluation (SRE'20) Conversational Telephone Speech (CTS) Challenge. The I4U's submission was resulted from active collaboration among researchers across eight research teams - I$^2$R (Singapore), UEF (Finland), VALPT (Italy, Spain), NEC (Japan), THUEE (China), LIA (France), NUS (Singapore), INRIA (France) and TJU (China). The submission was based on the fusion of top performing sub-systems and sub-fusion systems contributed by individual teams. Efforts have been spent on the use of common development and validation sets, submission schedule and milestone, minimizing inconsistency in trial list and score file format across sites.
Monolingual Recognizers Fusion for Code-switching Speech Recognition
Nov 02, 2022The bi-encoder structure has been intensively investigated in code-switching (CS) automatic speech recognition (ASR). However, most existing methods require the structures of two monolingual ASR models (MAMs) should be the same and only use the encoder of MAMs. This leads to the problem that pre-trained MAMs cannot be timely and fully used for CS ASR. In this paper, we propose a monolingual recognizers fusion method for CS ASR. It has two stages: the speech awareness (SA) stage and the language fusion (LF) stage. In the SA stage, acoustic features are mapped to two language-specific predictions by two independent MAMs. To keep the MAMs focused on their own language, we further extend the language-aware training strategy for the MAMs. In the LF stage, the BELM fuses two language-specific predictions to get the final prediction. Moreover, we propose a text simulation strategy to simplify the training process of the BELM and reduce reliance on CS data. Experiments on a Mandarin-English corpus show the efficiency of the proposed method. The mix error rate is significantly reduced on the test set after using open-source pre-trained MAMs.
Deep Spectro-temporal Artifacts for Detecting Synthesized Speech
Oct 11, 2022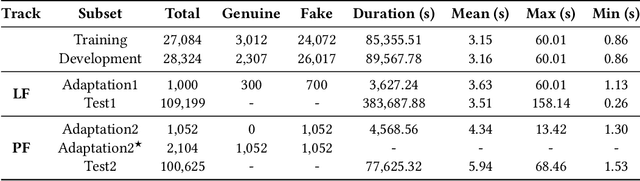
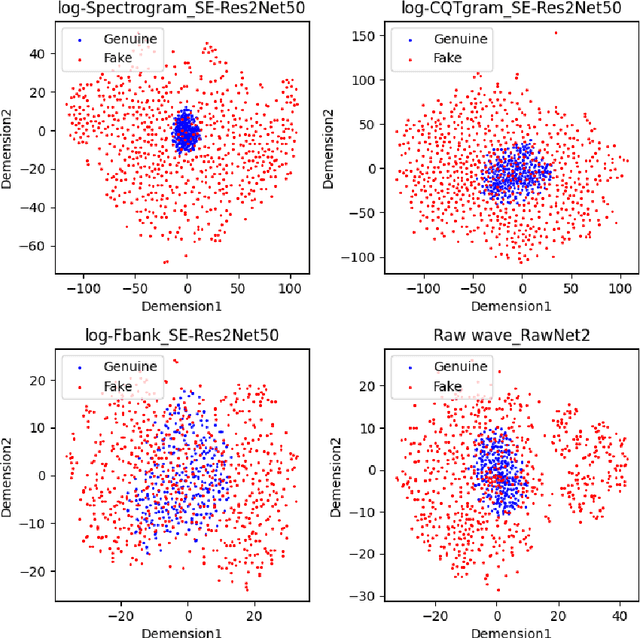
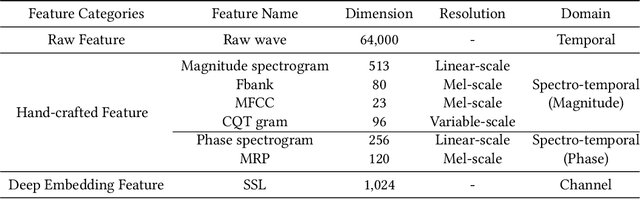

The Audio Deep Synthesis Detection (ADD) Challenge has been held to detect generated human-like speech. With our submitted system, this paper provides an overall assessment of track 1 (Low-quality Fake Audio Detection) and track 2 (Partially Fake Audio Detection). In this paper, spectro-temporal artifacts were detected using raw temporal signals, spectral features, as well as deep embedding features. To address track 1, low-quality data augmentation, domain adaptation via finetuning, and various complementary feature information fusion were aggregated in our system. Furthermore, we analyzed the clustering characteristics of subsystems with different features by visualization method and explained the effectiveness of our proposed greedy fusion strategy. As for track 2, frame transition and smoothing were detected using self-supervised learning structure to capture the manipulation of PF attacks in the time domain. We ranked 4th and 5th in track 1 and track 2, respectively.
VCSE: Time-Domain Visual-Contextual Speaker Extraction Network
Oct 09, 2022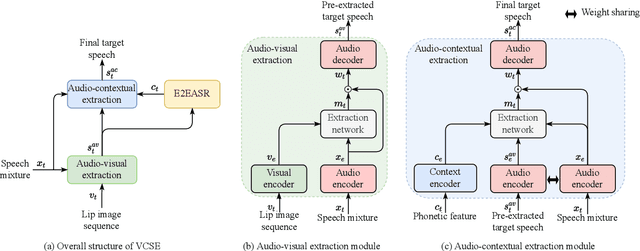
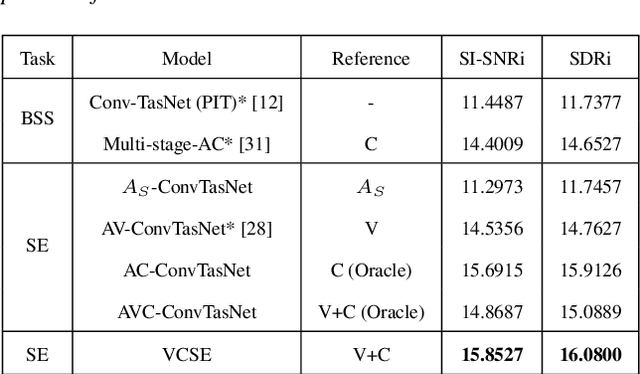
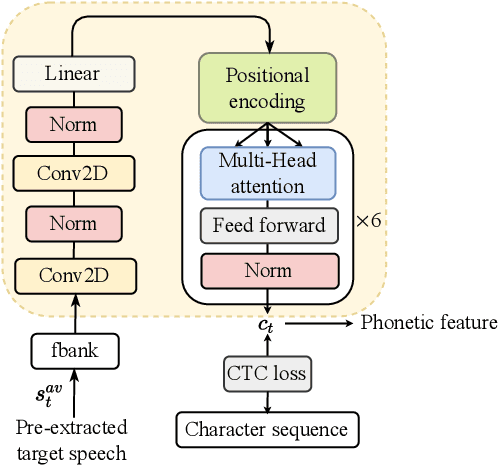
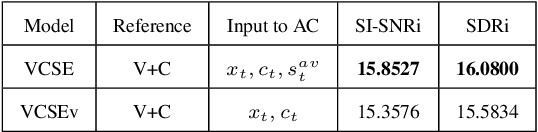
Speaker extraction seeks to extract the target speech in a multi-talker scenario given an auxiliary reference. Such reference can be auditory, i.e., a pre-recorded speech, visual, i.e., lip movements, or contextual, i.e., phonetic sequence. References in different modalities provide distinct and complementary information that could be fused to form top-down attention on the target speaker. Previous studies have introduced visual and contextual modalities in a single model. In this paper, we propose a two-stage time-domain visual-contextual speaker extraction network named VCSE, which incorporates visual and self-enrolled contextual cues stage by stage to take full advantage of every modality. In the first stage, we pre-extract a target speech with visual cues and estimate the underlying phonetic sequence. In the second stage, we refine the pre-extracted target speech with the self-enrolled contextual cues. Experimental results on the real-world Lip Reading Sentences 3 (LRS3) database demonstrate that our proposed VCSE network consistently outperforms other state-of-the-art baselines.
MIMO-DoAnet: Multi-channel Input and Multiple Outputs DoA Network with Unknown Number of Sound Sources
Jul 15, 2022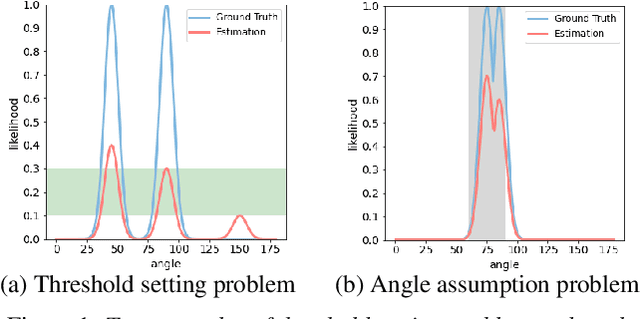

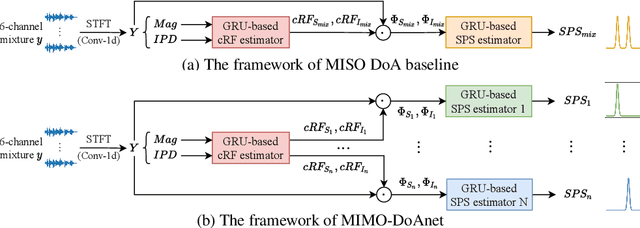
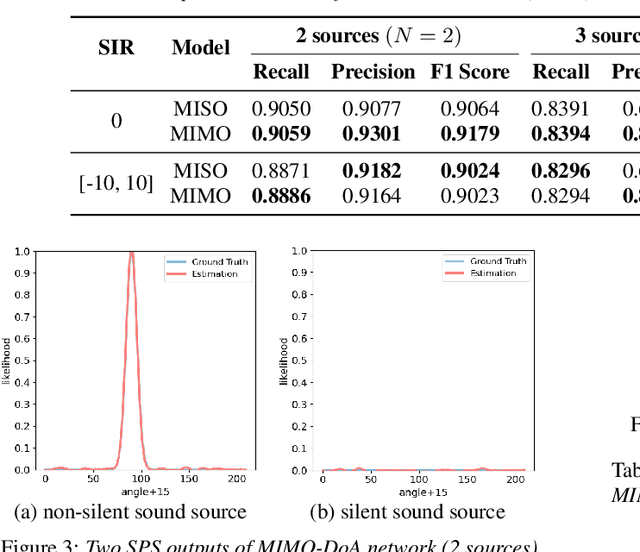
Recent neural network based Direction of Arrival (DoA) estimation algorithms have performed well on unknown number of sound sources scenarios. These algorithms are usually achieved by mapping the multi-channel audio input to the single output (i.e. overall spatial pseudo-spectrum (SPS) of all sources), that is called MISO. However, such MISO algorithms strongly depend on empirical threshold setting and the angle assumption that the angles between the sound sources are greater than a fixed angle. To address these limitations, we propose a novel multi-channel input and multiple outputs DoA network called MIMO-DoAnet. Unlike the general MISO algorithms, MIMO-DoAnet predicts the SPS coding of each sound source with the help of the informative spatial covariance matrix. By doing so, the threshold task of detecting the number of sound sources becomes an easier task of detecting whether there is a sound source in each output, and the serious interaction between sound sources disappears during inference stage. Experimental results show that MIMO-DoAnet achieves relative 18.6% and absolute 13.3%, relative 34.4% and absolute 20.2% F1 score improvement compared with the MISO baseline system in 3, 4 sources scenes. The results also demonstrate MIMO-DoAnet alleviates the threshold setting problem and solves the angle assumption problem effectively.
Language-specific Characteristic Assistance for Code-switching Speech Recognition
Jul 05, 2022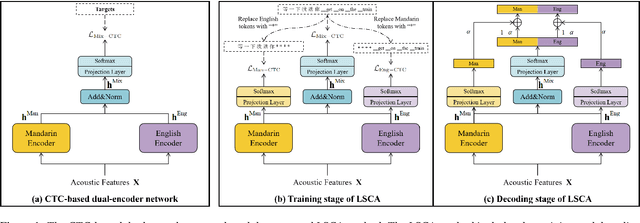
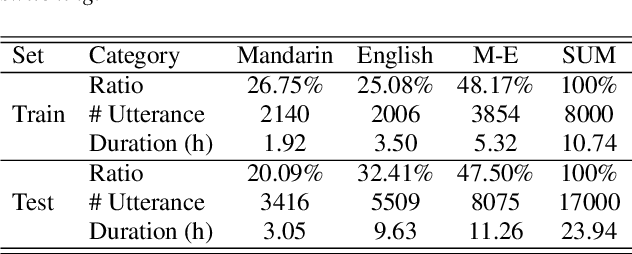

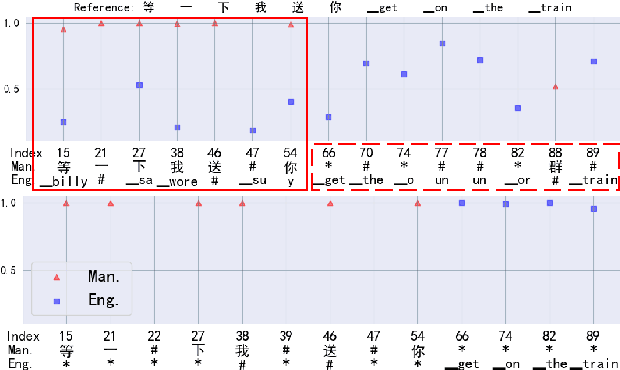
Dual-encoder structure successfully utilizes two language-specific encoders (LSEs) for code-switching speech recognition. Because LSEs are initialized by two pre-trained language-specific models (LSMs), the dual-encoder structure can exploit sufficient monolingual data and capture the individual language attributes. However, existing methods have no language constraints on LSEs and underutilize language-specific knowledge of LSMs. In this paper, we propose a language-specific characteristic assistance (LSCA) method to mitigate the above problems. Specifically, during training, we introduce two language-specific losses as language constraints and generate corresponding language-specific targets for them. During decoding, we take the decoding abilities of LSMs into account by combining the output probabilities of two LSMs and the mixture model to obtain the final predictions. Experiments show that either the training or decoding method of LSCA can improve the model's performance. Furthermore, the best result can obtain up to 15.4% relative error reduction on the code-switching test set by combining the training and decoding methods of LSCA. Moreover, the system can process code-switching speech recognition tasks well without extra shared parameters or even retraining based on two pre-trained LSMs by using our method.
Iterative Sound Source Localization for Unknown Number of Sources
Jun 24, 2022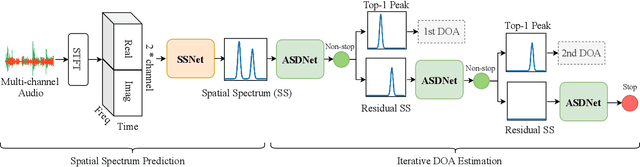
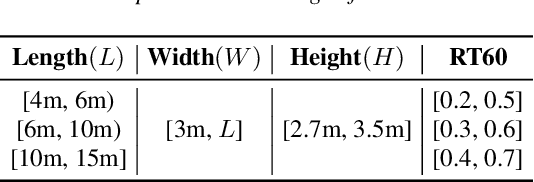
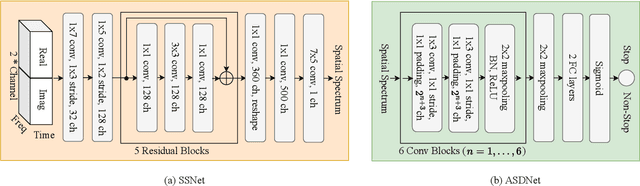
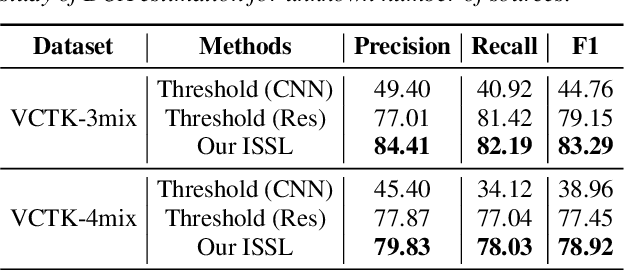
Sound source localization aims to seek the direction of arrival (DOA) of all sound sources from the observed multi-channel audio. For the practical problem of unknown number of sources, existing localization algorithms attempt to predict a likelihood-based coding (i.e., spatial spectrum) and employ a pre-determined threshold to detect the source number and corresponding DOA value. However, these threshold-based algorithms are not stable since they are limited by the careful choice of threshold. To address this problem, we propose an iterative sound source localization approach called ISSL, which can iteratively extract each source's DOA without threshold until the termination criterion is met. Unlike threshold-based algorithms, ISSL designs an active source detector network based on binary classifier to accept residual spatial spectrum and decide whether to stop the iteration. By doing so, our ISSL can deal with an arbitrary number of sources, even more than the number of sources seen during the training stage. The experimental results show that our ISSL achieves significant performance improvements in both DOA estimation and source number detection compared with the existing threshold-based algorithms.
Talking Head Generation Driven by Speech-Related Facial Action Units and Audio- Based on Multimodal Representation Fusion
Apr 27, 2022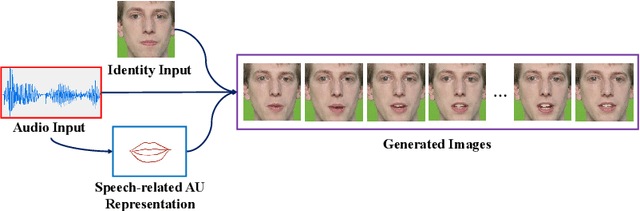
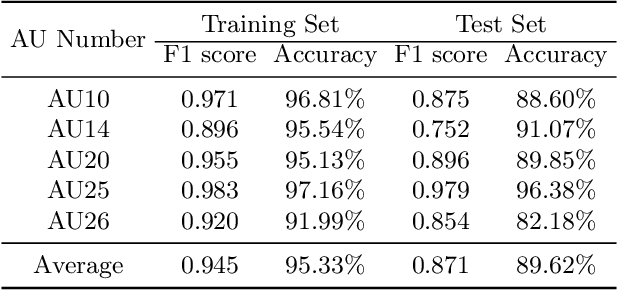
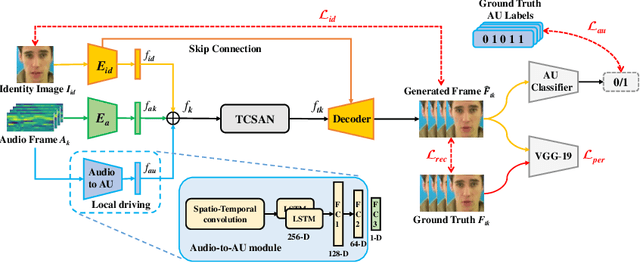

Talking head generation is to synthesize a lip-synchronized talking head video by inputting an arbitrary face image and corresponding audio clips. Existing methods ignore not only the interaction and relationship of cross-modal information, but also the local driving information of the mouth muscles. In this study, we propose a novel generative framework that contains a dilated non-causal temporal convolutional self-attention network as a multimodal fusion module to promote the relationship learning of cross-modal features. In addition, our proposed method uses both audio- and speech-related facial action units (AUs) as driving information. Speech-related AU information can guide mouth movements more accurately. Because speech is highly correlated with speech-related AUs, we propose an audio-to-AU module to predict speech-related AU information. We utilize pre-trained AU classifier to ensure that the generated images contain correct AU information. We verify the effectiveness of the proposed model on the GRID and TCD-TIMIT datasets. An ablation study is also conducted to verify the contribution of each component. The results of quantitative and qualitative experiments demonstrate that our method outperforms existing methods in terms of both image quality and lip-sync accuracy.