 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-specific Characteristic Assistance for Code-switching Speech Recognition
Jul 05, 2022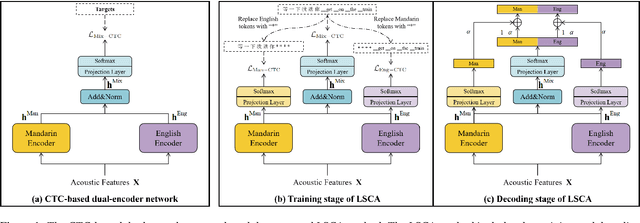

Dual-encoder structure successfully utilizes two language-specific encoders (LSEs) for code-switching speech recognition. Because LSEs are initialized by two pre-trained language-specific models (LSMs), the dual-encoder structure can exploit sufficient monolingual data and capture the individual language attributes. However, existing methods have no language constraints on LSEs and underutilize language-specific knowledge of LSMs. In this paper, we propose a language-specific characteristic assistance (LSCA) method to mitigate the above problems. Specifically, during training, we introduce two language-specific losses as language constraints and generate corresponding language-specific targets for them. During decoding, we take the decoding abilities of LSMs into account by combining the output probabilities of two LSMs and the mixture model to obtain the final predictions. Experiments show that either the training or decoding method of LSCA can improve the model's performance. Furthermore, the best result can obtain up to 15.4% relative error reduction on the code-switching test set by combining the training and decoding methods of LSCA. Moreover, the system can process code-switching speech recognition tasks well without extra shared parameters or even retraining based on two pre-trained LSMs by using our method.