 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsuka-Bench: Benchmarking Code Agents on Underspecified User Intent and Multi-Round Refinement
Jun 04, 2026Existing code-generation benchmarks score a single mapping from a complete prompt to a one-shot output. However, real web development is different. Users seldom write a full spec at the start; many requirements only become clear once they look at an intermediate result and react to it. We present Asuka-Bench, a benchmark that pairs underspecified user intent with multi-round refinement, grounded in browser-rendered behavior. Each task is resolved through a closed loop: a Code Agent generates a web project, a UI Agent executes test cases on the deployed site, and a User LLM turns evaluation outcomes into natural-language feedback for the next round. The benchmark comprises 50 web tasks with 784 evaluation criteria and 2402 expected outcomes. We benchmark 8 LLMs across 2 agent frameworks. The results separate models clearly: weighted Task Pass Rate varies by 38 percentage points and models also differ substantially in their ability to repair from feedback. Asuka-Bench is also far from saturated: even the strongest model completes only 52% of projects after three rounds.
LongCat-Next: Lexicalizing Modalities as Discrete Tokens
Mar 29, 2026The prevailing Next-Token Prediction (NTP) paradigm has driven the success of large language models through discrete autoregressive modeling. However, contemporary multimodal systems remain language-centric, often treating non-linguistic modalities as external attachments, leading to fragmented architectures and suboptimal integration. To transcend this limitation, we introduce Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space, enabling a consistent and principled autoregressive modeling across modalities. A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions, transforming continuous visual signals into hierarchical discrete tokens. Building on this foundation, we develop LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design. As an industrial-strength foundation model, it excels at seeing, painting, and talking within a single framework, achieving strong performance across a wide range of multimodal benchmarks. In particular, LongCat-Next addresses the long-standing performance ceiling of discrete vision modeling on understanding tasks and provides a unified approach to effectively reconcile the conflict between understanding and generation. As an attempt toward native multimodality, we open-source the LongCat-Next and its tokenizers, hoping to foster further research and development in the community. GitHub: https://github.com/meituan-longcat/LongCat-Next
TagaVLM: Topology-Aware Global Action Reasoning for Vision-Language Navigation
Mar 03, 2026Vision-Language Navigation (VLN) presents a unique challenge for Large Vision-Language Models (VLMs) due to their inherent architectural mismatch: VLMs are primarily pretrained on static, disembodied vision-language tasks, which fundamentally clash with the dynamic, embodied, and spatially-structured nature of navigation. Existing large-model-based methods often resort to converting rich visual and spatial information into text, forcing models to implicitly infer complex visual-topological relationships or limiting their global action capabilities. To bridge this gap, we propose TagaVLM (Topology-Aware Global Action reasoning), an end-to-end framework that explicitly injects topological structures into the VLM backbone. To introduce topological edge information, Spatial Topology Aware Residual Attention (STAR-Att) directly integrates it into the VLM's self-attention mechanism, enabling intrinsic spatial reasoning while preserving pretrained knowledge. To enhance topological node information, an Interleaved Navigation Prompt strengthens node-level visual-text alignment. Finally, with the embedded topological graph, the model is capable of global action reasoning, allowing for robust path correction. On the R2R benchmark, TagaVLM achieves state-of-the-art performance among large-model-based methods, with a Success Rate (SR) of 51.09% and SPL of 47.18 in unseen environments, outperforming prior work by 3.39% in SR and 9.08 in SPL. This demonstrates that, for embodied spatial reasoning, targeted enhancements on smaller open-source VLMs can be more effective than brute-force model scaling. The code will be released upon publication.Project page: https://apex-bjut.github.io/Taga-VLM
ViC-Bench: Benchmarking Visual-Interleaved Chain-of-Thought Capability in MLLMs with Free-Style Intermediate State Representations
May 20, 2025



Visual-Interleaved Chain-of-Thought (VI-CoT) enables MLLMs to continually update their understanding and decisions based on step-wise intermediate visual states (IVS), much like a human would, which demonstrates impressive success in various tasks, thereby leading to emerged advancements in related benchmarks. Despite promising progress, current benchmarks provide models with relatively fixed IVS, rather than free-style IVS, whch might forcibly distort the original thinking trajectories, failing to evaluate their intrinsic reasoning capabilities. More importantly, existing benchmarks neglect to systematically explore the impact factors that IVS would impart to untamed reasoning performance. To tackle above gaps, we introduce a specialized benchmark termed ViC-Bench, consisting of four representive tasks: maze navigation, jigsaw puzzle, embodied long-horizon planning, and complex counting, where each task has dedicated free-style IVS generation pipeline supporting function calls. To systematically examine VI-CoT capability, we propose a thorough evaluation suite incorporating a progressive three-stage strategy with targeted new metrics. Besides, we establish Incremental Prompting Information Injection (IPII) strategy to ablatively explore the prompting factors for VI-CoT. We extensively conduct evaluations for 18 advanced MLLMs, revealing key insights into their VI-CoT capability. Our proposed benchmark is publicly open at Huggingface.
Talking Head Generation Driven by Speech-Related Facial Action Units and Audio- Based on Multimodal Representation Fusion
Apr 27, 2022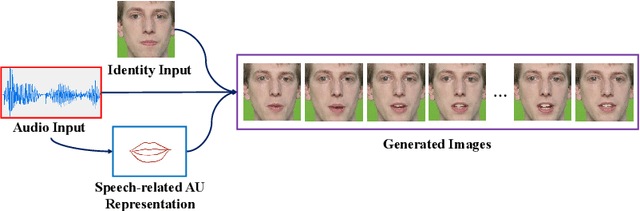
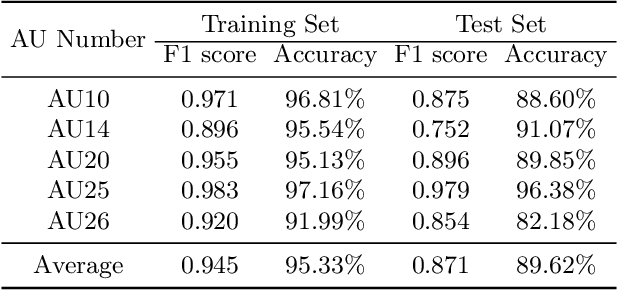
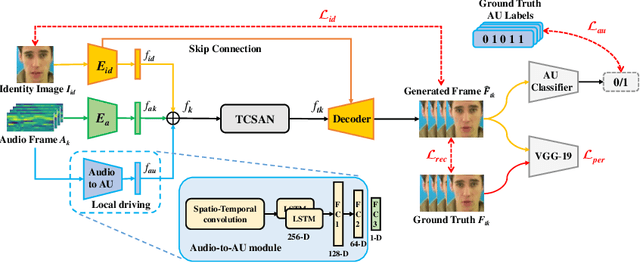

Talking head generation is to synthesize a lip-synchronized talking head video by inputting an arbitrary face image and corresponding audio clips. Existing methods ignore not only the interaction and relationship of cross-modal information, but also the local driving information of the mouth muscles. In this study, we propose a novel generative framework that contains a dilated non-causal temporal convolutional self-attention network as a multimodal fusion module to promote the relationship learning of cross-modal features. In addition, our proposed method uses both audio- and speech-related facial action units (AUs) as driving information. Speech-related AU information can guide mouth movements more accurately. Because speech is highly correlated with speech-related AUs, we propose an audio-to-AU module to predict speech-related AU information. We utilize pre-trained AU classifier to ensure that the generated images contain correct AU information. We verify the effectiveness of the proposed model on the GRID and TCD-TIMIT datasets. An ablation study is also conducted to verify the contribution of each component. The results of quantitative and qualitative experiments demonstrate that our method outperforms existing methods in terms of both image quality and lip-sync accuracy.
Talking Head Generation with Audio and Speech Related Facial Action Units
Oct 19, 2021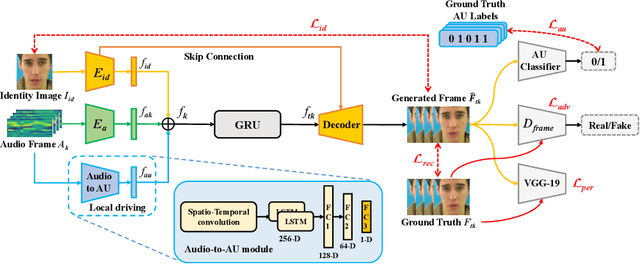
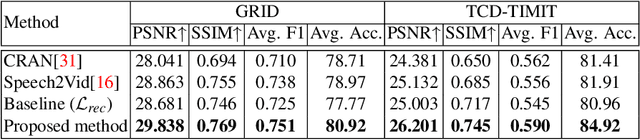


The task of talking head generation is to synthesize a lip synchronized talking head video by inputting an arbitrary face image and audio clips. Most existing methods ignore the local driving information of the mouth muscles. In this paper, we propose a novel recurrent generative network that uses both audio and speech-related facial action units (AUs) as the driving information. AU information related to the mouth can guide the movement of the mouth more accurately. Since speech is highly correlated with speech-related AUs, we propose an Audio-to-AU module in our system to predict the speech-related AU information from speech. In addition, we use AU classifier to ensure that the generated images contain correct AU information. Frame discriminator is also constructed for adversarial training to improve the realism of the generated face. We verify the effectiveness of our model on the GRID dataset and TCD-TIMIT dataset. We also conduct an ablation study to verify the contribution of each component in our model. Quantitative and qualitative experiments demonstrate that our method outperforms existing methods in both image quality and lip-sync accuracy.