 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Codec Language Models are Zero-Shot Text to Speech Synthesizers
Jan 05, 2023



We introduce a language modeling approach for text to speech synthesis (TTS). Specifically, we train a neural codec language model (called Vall-E) using discrete codes derived from an off-the-shelf neural audio codec model, and regard TTS as a conditional language modeling task rather than continuous signal regression as in previous work. During the pre-training stage, we scale up the TTS training data to 60K hours of English speech which is hundreds of times larger than existing systems. Vall-E emerges in-context learning capabilities and can be used to synthesize high-quality personalized speech with only a 3-second enrolled recording of an unseen speaker as an acoustic prompt. Experiment results show that Vall-E significantly outperforms the state-of-the-art zero-shot TTS system in terms of speech naturalness and speaker similarity. In addition, we find Vall-E could preserve the speaker's emotion and acoustic environment of the acoustic prompt in synthesis. See https://aka.ms/valle for demos of our work.
VATLM: Visual-Audio-Text Pre-Training with Unified Masked Prediction for Speech Representation Learning
Nov 21, 2022



Although speech is a simple and effective way for humans to communicate with the outside world, a more realistic speech interaction contains multimodal information, e.g., vision, text. How to design a unified framework to integrate different modal information and leverage different resources (e.g., visual-audio pairs, audio-text pairs, unlabeled speech, and unlabeled text) to facilitate speech representation learning was not well explored. In this paper, we propose a unified cross-modal representation learning framework VATLM (Visual-Audio-Text Language Model). The proposed VATLM employs a unified backbone network to model the modality-independent information and utilizes three simple modality-dependent modules to preprocess visual, speech, and text inputs. In order to integrate these three modalities into one shared semantic space, VATLM is optimized with a masked prediction task of unified tokens, given by our proposed unified tokenizer. We evaluate the pre-trained VATLM on audio-visual related downstream tasks, including audio-visual speech recognition (AVSR), visual speech recognition (VSR) tasks. Results show that the proposed VATLM outperforms previous the state-of-the-art models, such as audio-visual pre-trained AV-HuBERT model, and analysis also demonstrates that VATLM is capable of aligning different modalities into the same space. To facilitate future research, we release the code and pre-trained models at https://aka.ms/vatlm.
LAMASSU: Streaming Language-Agnostic Multilingual Speech Recognition and Translation Using Neural Transducers
Nov 05, 2022



End-to-end formulation of automatic speech recognition (ASR) and speech translation (ST) makes it easy to use a single model for both multilingual ASR and many-to-many ST. In this paper, we propose streaming language-agnostic multilingual speech recognition and translation using neural transducers (LAMASSU). To enable multilingual text generation in LAMASSU, we conduct a systematic comparison between specified and unified prediction and joint networks. We leverage a language-agnostic multilingual encoder that substantially outperforms shared encoders. To enhance LAMASSU, we propose to feed target LID to encoders. We also apply connectionist temporal classification regularization to transducer training. Experimental results show that LAMASSU not only drastically reduces the model size but also outperforms monolingual ASR and bilingual ST models.
Joint Pre-Training with Speech and Bilingual Text for Direct Speech to Speech Translation
Oct 31, 2022



Direct speech-to-speech translation (S2ST) is an attractive research topic with many advantages compared to cascaded S2ST. However, direct S2ST suffers from the data scarcity problem because the corpora from speech of the source language to speech of the target language are very rare. To address this issue, we propose in this paper a Speech2S model, which is jointly pre-trained with unpaired speech and bilingual text data for direct speech-to-speech translation tasks. By effectively leveraging the paired text data, Speech2S is capable of modeling the cross-lingual speech conversion from source to target language. We verify the performance of the proposed Speech2S on Europarl-ST and VoxPopuli datasets. Experimental results demonstrate that Speech2S gets an improvement of about 5 BLEU scores compared to encoder-only pre-training models, and achieves a competitive or even better performance than existing state-of-the-art models1.
Robust Data2vec: Noise-robust Speech Representation Learning for ASR by Combining Regression and Improved Contrastive Learning
Oct 27, 2022



Self-supervised pre-training methods based on contrastive learning or regression tasks can utilize more unlabeled data to improve the performance of automatic speech recognition (ASR). However, the robustness impact of combining the two pre-training tasks and constructing different negative samples for contrastive learning still remains unclear. In this paper, we propose a noise-robust data2vec for self-supervised speech representation learning by jointly optimizing the contrastive learning and regression tasks in the pre-training stage. Furthermore, we present two improved methods to facilitate contrastive learning. More specifically, we first propose to construct patch-based non-semantic negative samples to boost the noise robustness of the pre-training model, which is achieved by dividing the features into patches at different sizes (i.e., so-called negative samples). Second, by analyzing the distribution of positive and negative samples, we propose to remove the easily distinguishable negative samples to improve the discriminative capacity for pre-training models. Experimental results on the CHiME-4 dataset show that our method is able to improve the performance of the pre-trained model in noisy scenarios. We find that joint training of the contrastive learning and regression tasks can avoid the model collapse to some extent compared to only training the regression task.
SpeechUT: Bridging Speech and Text with Hidden-Unit for Encoder-Decoder Based Speech-Text Pre-training
Oct 07, 2022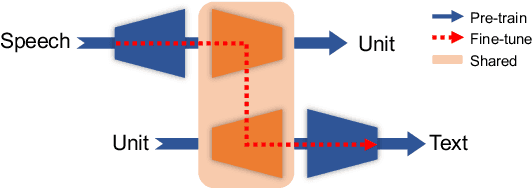
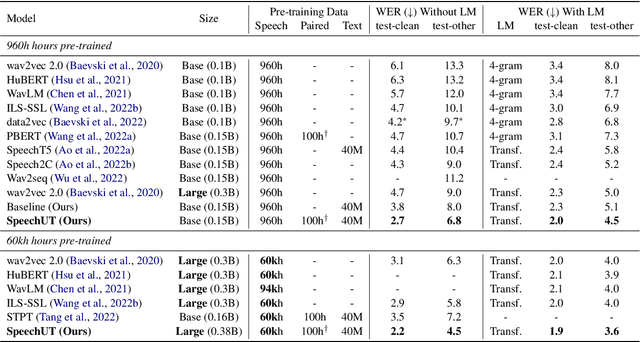
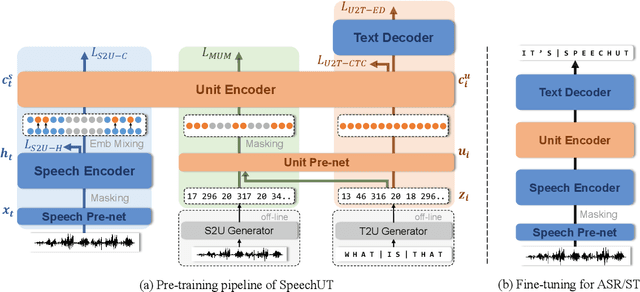
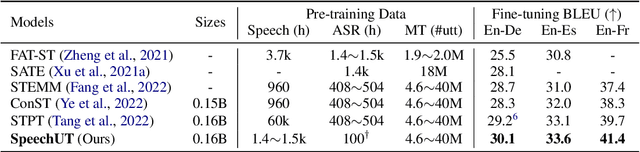
The rapid development of single-modal pre-training has prompted researchers to pay more attention to cross-modal pre-training methods. In this paper, we propose a unified-modal speech-unit-text pre-training model, SpeechUT, to connect the representations of a speech encoder and a text decoder with a shared unit encoder. Leveraging hidden-unit as an interface to align speech and text, we can decompose the speech-to-text model into a speech-to-unit model and a unit-to-text model, which can be jointly pre-trained with unpaired speech and text data respectively. Our proposed SpeechUT is fine-tuned and evaluated on automatic speech recognition (ASR) and speech translation (ST) tasks. Experimental results show that SpeechUT gets substantial improvements over strong baselines, and achieves state-of-the-art performance on both the LibriSpeech ASR and MuST-C ST tasks. To better understand the proposed SpeechUT, detailed analyses are conducted. The code and pre-trained models are available at https://aka.ms/SpeechUT.
SpeechLM: Enhanced Speech Pre-Training with Unpaired Textual Data
Sep 30, 2022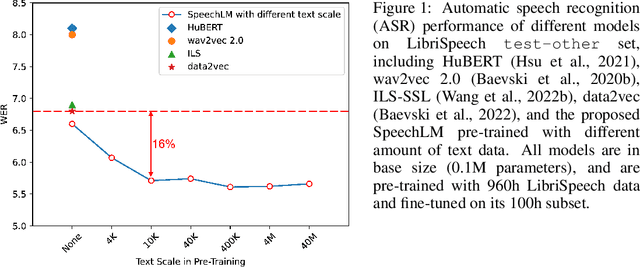
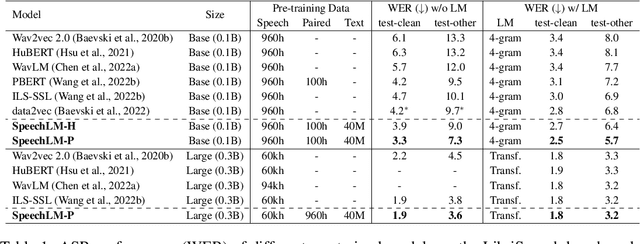
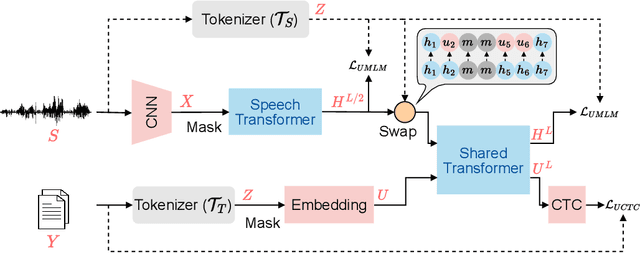
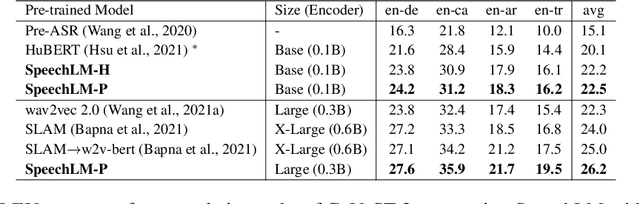
How to boost speech pre-training with textual data is an unsolved problem due to the fact that speech and text are very different modalities with distinct characteristics. In this paper, we propose a cross-modal Speech and Language Model (SpeechLM) to explicitly align speech and text pre-training with a pre-defined unified discrete representation. Specifically, we introduce two alternative discrete tokenizers to bridge the speech and text modalities, including phoneme-unit and hidden-unit tokenizers, which can be trained using a small amount of paired speech-text data. Based on the trained tokenizers, we convert the unlabeled speech and text data into tokens of phoneme units or hidden units. The pre-training objective is designed to unify the speech and the text into the same discrete semantic space with a unified Transformer network. Leveraging only 10K text sentences, our SpeechLM gets a 16\% relative WER reduction over the best base model performance (from 6.8 to 5.7) on the public LibriSpeech ASR benchmark. Moreover, SpeechLM with fewer parameters even outperforms previous SOTA models on CoVoST-2 speech translation tasks. We also evaluate our SpeechLM on various spoken language processing tasks under the universal representation evaluation framework SUPERB, demonstrating significant improvements on content-related tasks. Our code and models are available at https://aka.ms/SpeechLM.
The YiTrans End-to-End Speech Translation System for IWSLT 2022 Offline Shared Task
Jun 14, 2022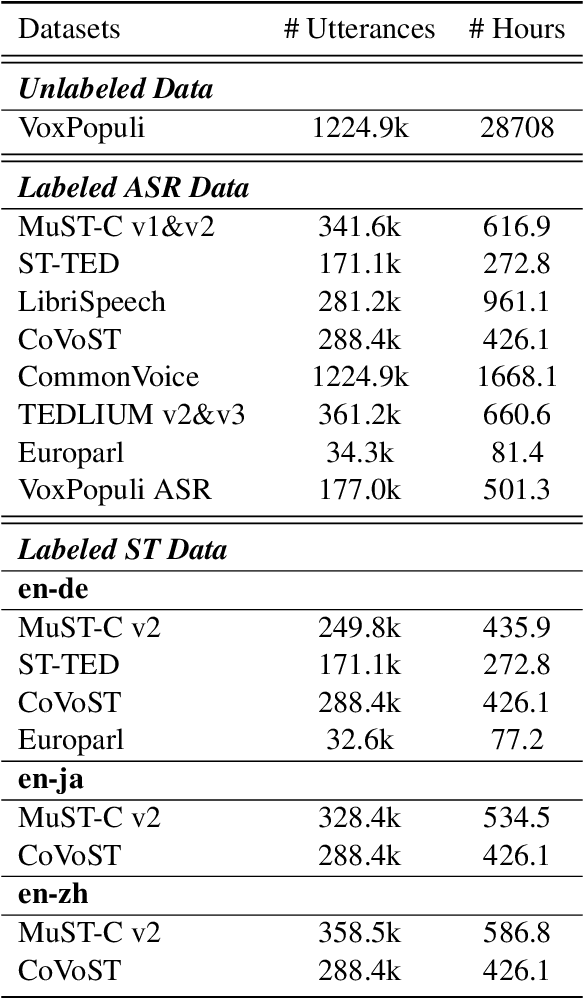
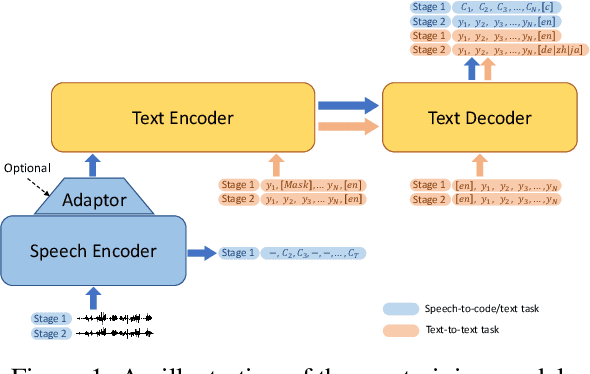
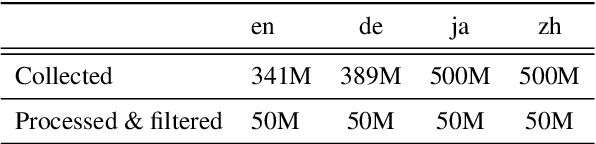
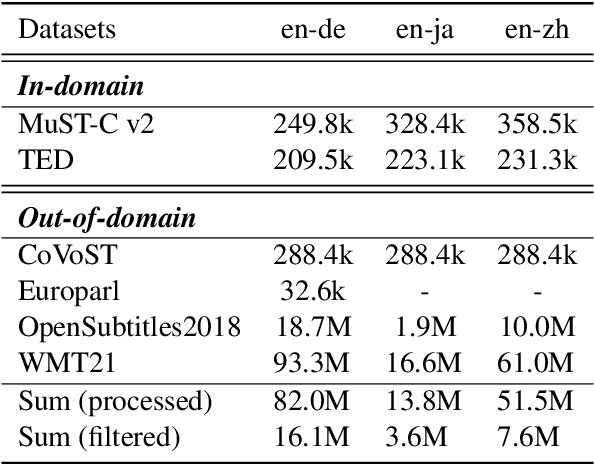
This paper describes the submission of our end-to-end YiTrans speech translation system for the IWSLT 2022 offline task, which translates from English audio to German, Chinese, and Japanese. The YiTrans system is built on large-scale pre-trained encoder-decoder models. More specifically, we first design a multi-stage pre-training strategy to build a multi-modality model with a large amount of labeled and unlabeled data. We then fine-tune the corresponding components of the model for the downstream speech translation tasks. Moreover, we make various efforts to improve performance, such as data filtering, data augmentation, speech segmentation, model ensemble, and so on. Experimental results show that our YiTrans system obtains a significant improvement than the strong baseline on three translation directions, and it achieves +5.2 BLEU improvements over last year's optimal end-to-end system on tst2021 English-German. Our final submissions rank first on English-German and English-Chinese end-to-end systems in terms of the automatic evaluation metric. We make our code and models publicly available.
Speech Pre-training with Acoustic Piece
Apr 07, 2022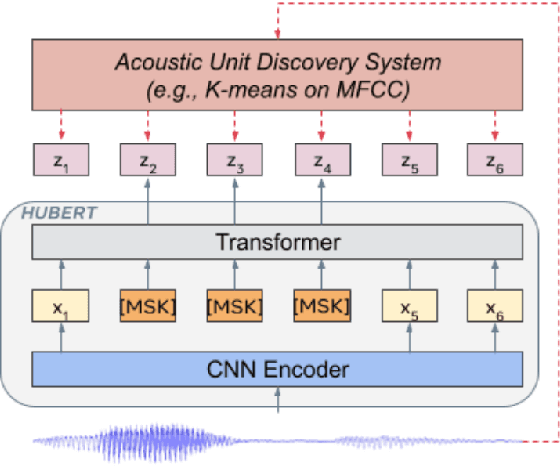

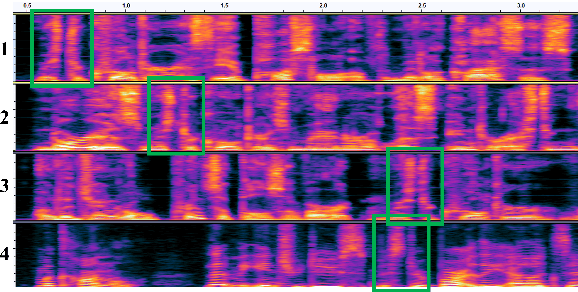
Previous speech pre-training methods, such as wav2vec2.0 and HuBERT, pre-train a Transformer encoder to learn deep representations from audio data, with objectives predicting either elements from latent vector quantized space or pre-generated labels (known as target codes) with offline clustering. However, those training signals (quantized elements or codes) are independent across different tokens without considering their relations. According to our observation and analysis, the target codes share obvious patterns aligned with phonemized text data. Based on that, we propose to leverage those patterns to better pre-train the model considering the relations among the codes. The patterns we extracted, called "acoustic piece"s, are from the sentence piece result of HuBERT codes. With the acoustic piece as the training signal, we can implicitly bridge the input audio and natural language, which benefits audio-to-text tasks, such as automatic speech recognition (ASR). Simple but effective, our method "HuBERT-AP" significantly outperforms strong baselines on the LibriSpeech ASR task.
A Roadmap for Big Model
Apr 02, 2022



With the rapid development of deep learning, training Big Models (BMs) for multiple downstream tasks becomes a popular paradigm. Researchers have achieved various outcomes in the construction of BMs and the BM application in many fields. At present, there is a lack of research work that sorts out the overall progress of BMs and guides the follow-up research. In this paper, we cover not only the BM technologies themselves but also the prerequisites for BM training and applications with BMs, dividing the BM review into four parts: Resource, Models, Key Technologies and Application. We introduce 16 specific BM-related topics in those four parts, they are Data, Knowledge, Computing System, Parallel Training System, Language Model, Vision Model, Multi-modal Model, Theory&Interpretability, Commonsense Reasoning, Reliability&Security, Governance, Evaluation, Machine Translation, Text Generation, Dialogue and Protein Research. In each topic, we summarize clearly the current studies and propose some future research directions. At the end of this paper, we conclude the further development of BMs in a more general view.