 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBASEN: Time-Domain Brain-Assisted Speech Enhancement Network with Convolutional Cross Attention in Multi-talker Conditions
May 17, 2023


Time-domain single-channel speech enhancement (SE) still remains challenging to extract the target speaker without any prior information on multi-talker conditions. It has been shown via auditory attention decoding that the brain activity of the listener contains the auditory information of the attended speaker. In this paper, we thus propose a novel time-domain brain-assisted SE network (BASEN) incorporating electroencephalography (EEG) signals recorded from the listener for extracting the target speaker from monaural speech mixtures. The proposed BASEN is based on the fully-convolutional time-domain audio separation network. In order to fully leverage the complementary information contained in the EEG signals, we further propose a convolutional multi-layer cross attention module to fuse the dual-branch features. Experimental results on a public dataset show that the proposed model outperforms the state-of-the-art method in several evaluation metrics. The reproducible code is available at https://github.com/jzhangU/Basen.git.
Speech Enhancement with Multi-granularity Vector Quantization
Feb 16, 2023With advances in deep learning, neural network based speech enhancement (SE) has developed rapidly in the last decade. Meanwhile, the self-supervised pre-trained model and vector quantization (VQ) have achieved excellent performance on many speech-related tasks, while they are less explored on SE. As it was shown in our previous work that utilizing a VQ module to discretize noisy speech representations is beneficial for speech denoising, in this work we therefore study the impact of using VQ at different layers with different number of codebooks. Different VQ modules indeed enable to extract multiple-granularity speech features. Following an attention mechanism, the contextual features extracted by a pre-trained model are fused with the local features extracted by the encoder, such that both global and local information are preserved to reconstruct the enhanced speech. Experimental results on the Valentini dataset show that the proposed model can improve the SE performance, where the impact of choosing pre-trained models is also revealed.
Robust Data2vec: Noise-robust Speech Representation Learning for ASR by Combining Regression and Improved Contrastive Learning
Oct 27, 2022



Self-supervised pre-training methods based on contrastive learning or regression tasks can utilize more unlabeled data to improve the performance of automatic speech recognition (ASR). However, the robustness impact of combining the two pre-training tasks and constructing different negative samples for contrastive learning still remains unclear. In this paper, we propose a noise-robust data2vec for self-supervised speech representation learning by jointly optimizing the contrastive learning and regression tasks in the pre-training stage. Furthermore, we present two improved methods to facilitate contrastive learning. More specifically, we first propose to construct patch-based non-semantic negative samples to boost the noise robustness of the pre-training model, which is achieved by dividing the features into patches at different sizes (i.e., so-called negative samples). Second, by analyzing the distribution of positive and negative samples, we propose to remove the easily distinguishable negative samples to improve the discriminative capacity for pre-training models. Experimental results on the CHiME-4 dataset show that our method is able to improve the performance of the pre-trained model in noisy scenarios. We find that joint training of the contrastive learning and regression tasks can avoid the model collapse to some extent compared to only training the regression task.
Speech Enhancement Using Self-Supervised Pre-Trained Model and Vector Quantization
Sep 28, 2022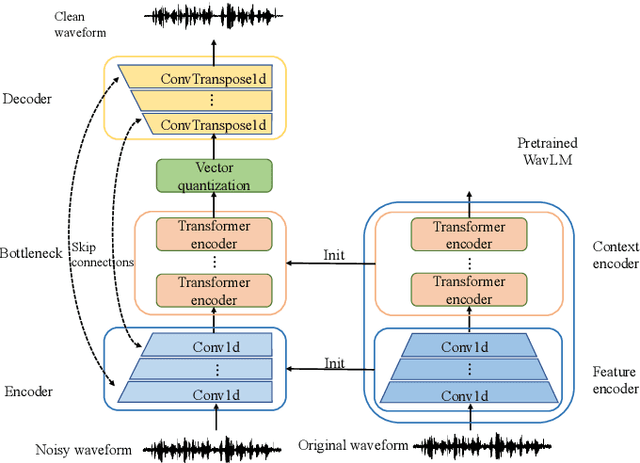
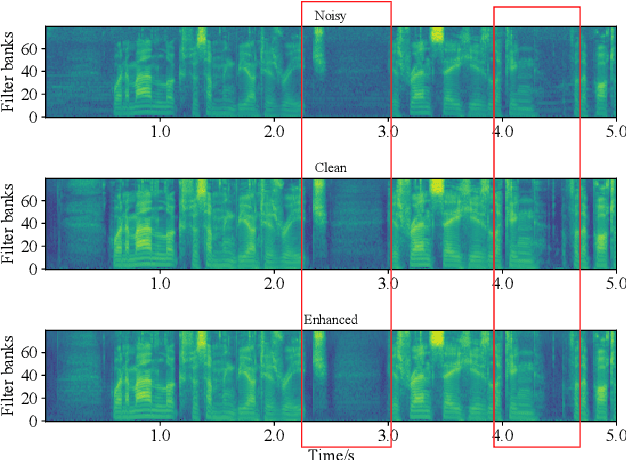
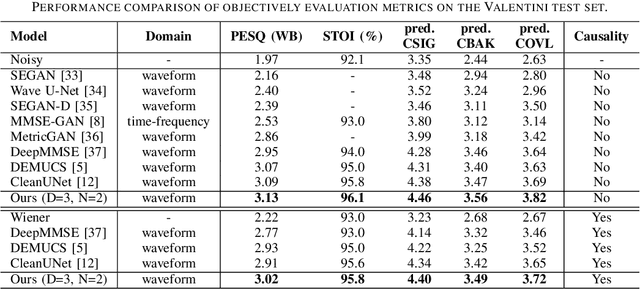
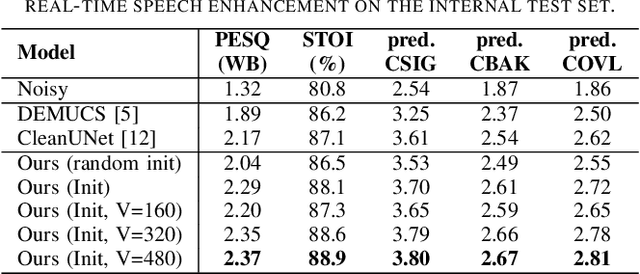
With the development of deep learning, neural network-based speech enhancement (SE) models have shown excellent performance. Meanwhile, it was shown that the development of self-supervised pre-trained models can be applied to various downstream tasks. In this paper, we will consider the application of the pre-trained model to the real-time SE problem. Specifically, the encoder and bottleneck layer of the DEMUCS model are initialized using the self-supervised pretrained WavLM model, the convolution in the encoder is replaced by causal convolution, and the transformer encoder in the bottleneck layer is based on causal attention mask. In addition, as discretizing the noisy speech representations is more beneficial for denoising, we utilize a quantization module to discretize the representation output from the bottleneck layer, which is then fed into the decoder to reconstruct the clean speech waveform. Experimental results on the Valentini dataset and an internal dataset show that the pre-trained model based initialization can improve the SE performance and the discretization operation suppresses the noise component in the representations to some extent, which can further improve the performance.
Joint Training of Speech Enhancement and Self-supervised Model for Noise-robust ASR
May 26, 2022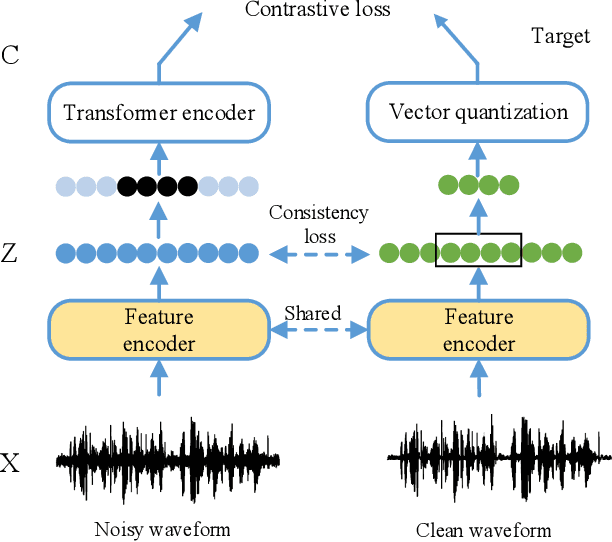
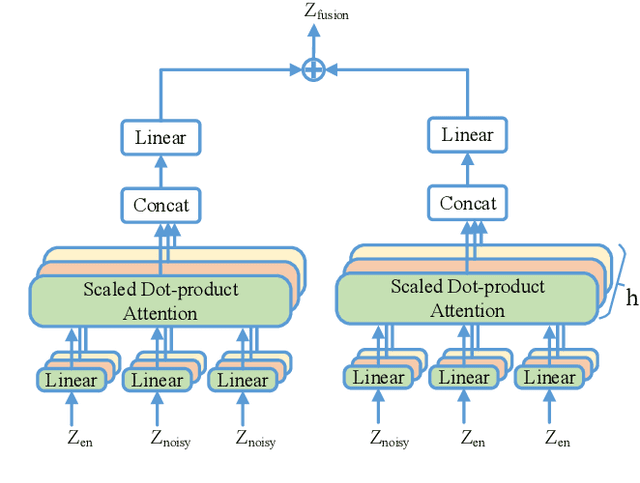
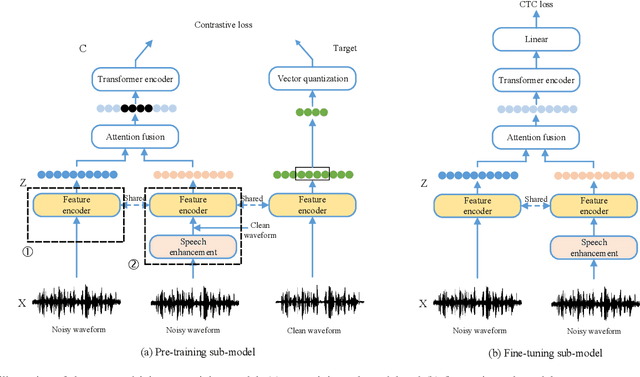
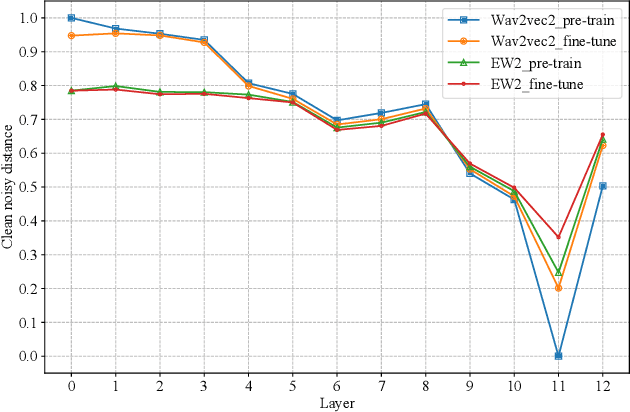
Speech enhancement (SE) is usually required as a front end to improve the speech quality in noisy environments, while the enhanced speech might not be optimal for automatic speech recognition (ASR) systems due to speech distortion. On the other hand, it was shown that self-supervised pre-training enables the utilization of a large amount of unlabeled noisy data, which is rather beneficial for the noise robustness of ASR. However, the potential of the (optimal) integration of SE and self-supervised pre-training still remains unclear. In order to find an appropriate combination and reduce the impact of speech distortion caused by SE, in this paper we therefore propose a joint pre-training approach for the SE module and the self-supervised model. First, in the pre-training phase the original noisy waveform or the waveform obtained by SE is fed into the self-supervised model to learn the contextual representation, where the quantified clean speech acts as the target. Second, we propose a dual-attention fusion method to fuse the features of noisy and enhanced speeches, which can compensate the information loss caused by separately using individual modules. Due to the flexible exploitation of clean/noisy/enhanced branches, the proposed method turns out to be a generalization of some existing noise-robust ASR models, e.g., enhanced wav2vec2.0. Finally, experimental results on both synthetic and real noisy datasets show that the proposed joint training approach can improve the ASR performance under various noisy settings, leading to a stronger noise robustness.
A Complementary Joint Training Approach Using Unpaired Speech and Text for Low-Resource Automatic Speech Recognition
Apr 05, 2022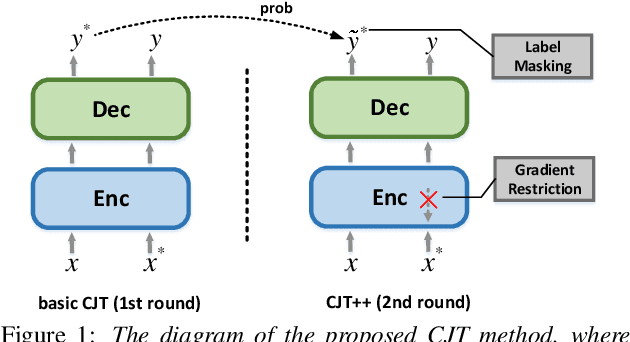
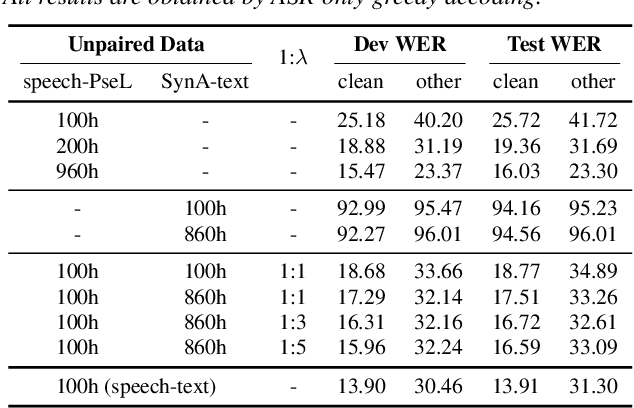
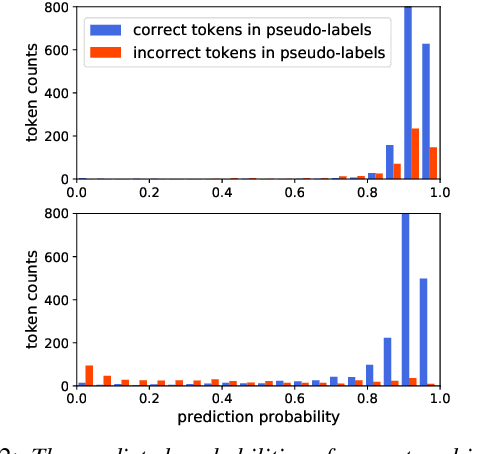
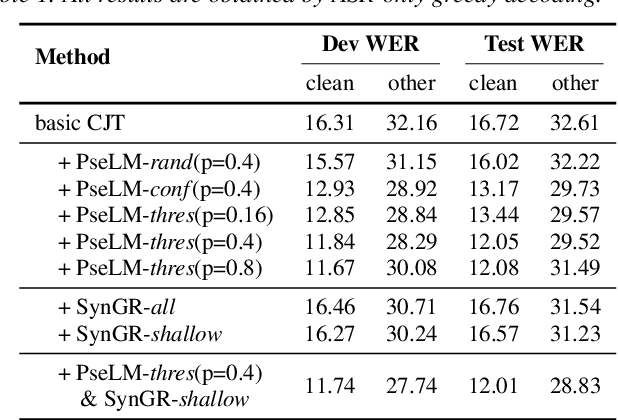
Unpaired data has shown to be beneficial for low-resource automatic speech recognition~(ASR), which can be involved in the design of hybrid models with multi-task training or language model dependent pre-training. In this work, we leverage unpaired data to train a general sequence-to-sequence model. Unpaired speech and text are used in the form of data pairs by generating the corresponding missing parts in prior to model training. Inspired by the complementarity of speech-PseudoLabel pair and SynthesizedAudio-text pair in both acoustic features and linguistic features, we propose a complementary joint training~(CJT) method that trains a model alternatively with two data pairs. Furthermore, label masking for pseudo-labels and gradient restriction for synthesized audio are proposed to further cope with the deviations from real data, termed as CJT++. Experimental results show that compared to speech-only training, the proposed basic CJT achieves great performance improvements on clean/other test sets, and the CJT++ re-training yields further performance enhancements. It is also apparent that the proposed method outperforms the wav2vec2.0 model with the same model size and beam size, particularly in extreme low-resource cases.
Supervised and Self-supervised Pretraining Based COVID-19 Detection Using Acoustic Breathing/Cough/Speech Signals
Jan 22, 2022
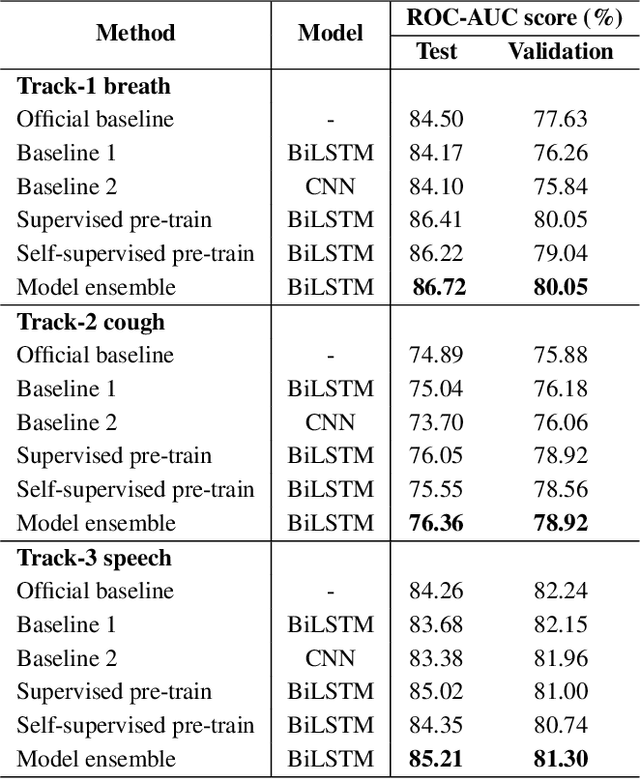
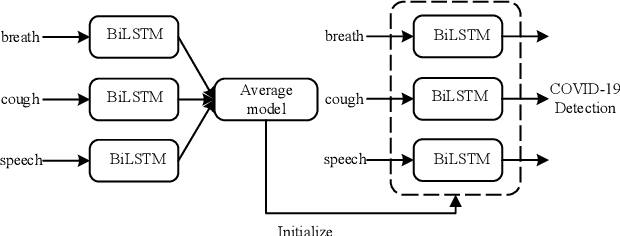
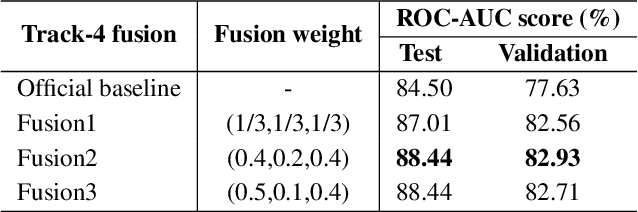
In this work, we propose a bi-directional long short-term memory (BiLSTM) network based COVID-19 detection method using breath/speech/cough signals. By using the acoustic signals to train the network, respectively, we can build individual models for three tasks, whose parameters are averaged to obtain an average model, which is then used as the initialization for the BiLSTM model training of each task. This initialization method can significantly improve the performance on the three tasks, which surpasses the official baseline results. Besides, we also utilize a public pre-trained model wav2vec2.0 and pre-train it using the official DiCOVA datasets. This wav2vec2.0 model is utilized to extract high-level features of the sound as the model input to replace conventional mel-frequency cepstral coefficients (MFCC) features. Experimental results reveal that using high-level features together with MFCC features can improve the performance. To further improve the performance, we also deploy some preprocessing techniques like silent segment removal, amplitude normalization and time-frequency mask. The proposed detection model is evaluated on the DiCOVA dataset and results show that our method achieves an area under curve (AUC) score of 88.44% on blind test in the fusion track.
A Noise-Robust Self-supervised Pre-training Model Based Speech Representation Learning for Automatic Speech Recognition
Jan 22, 2022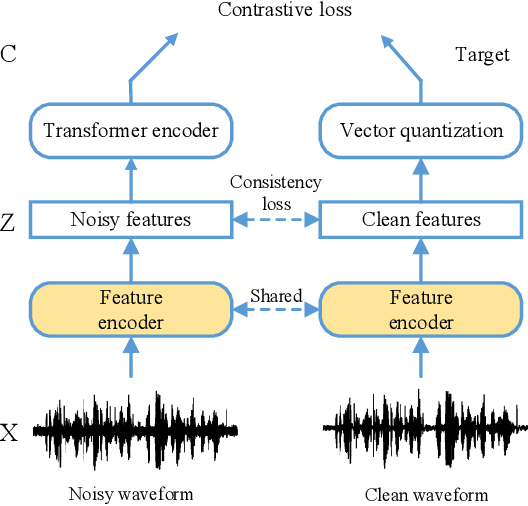
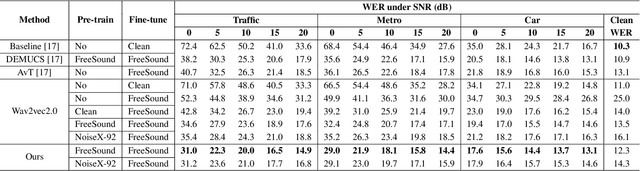
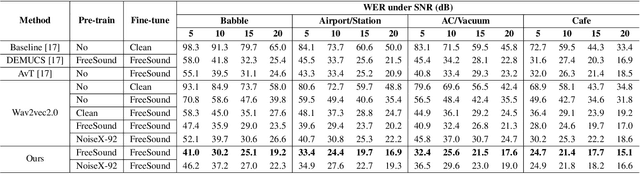
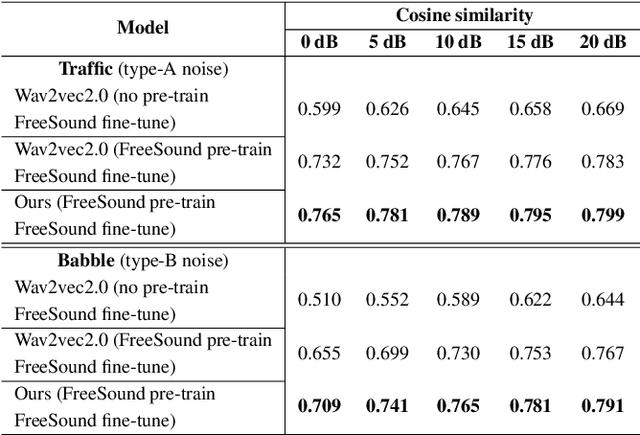
Wav2vec2.0 is a popular self-supervised pre-training framework for learning speech representations in the context of automatic speech recognition (ASR). It was shown that wav2vec2.0 has a good robustness against the domain shift, while the noise robustness is still unclear. In this work, we therefore first analyze the noise robustness of wav2vec2.0 via experiments. We observe that wav2vec2.0 pre-trained on noisy data can obtain good representations and thus improve the ASR performance on the noisy test set, which however brings a performance degradation on the clean test set. To avoid this issue, in this work we propose an enhanced wav2vec2.0 model. Specifically, the noisy speech and the corresponding clean version are fed into the same feature encoder, where the clean speech provides training targets for the model. Experimental results reveal that the proposed method can not only improve the ASR performance on the noisy test set which surpasses the original wav2vec2.0, but also ensure a tiny performance decrease on the clean test set. In addition, the effectiveness of the proposed method is demonstrated under different types of noise conditions.