 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Enhanced Negatives for Training Language-Based Object Detectors
Dec 29, 2023The recent progress in language-based open-vocabulary object detection can be largely attributed to finding better ways of leveraging large-scale data with free-form text annotations. Training such models with a discriminative objective function has proven successful, but requires good positive and negative samples. However, the free-form nature and the open vocabulary of object descriptions make the space of negatives extremely large. Prior works randomly sample negatives or use rule-based techniques to build them. In contrast, we propose to leverage the vast knowledge built into modern generative models to automatically build negatives that are more relevant to the original data. Specifically, we use large-language-models to generate negative text descriptions, and text-to-image diffusion models to also generate corresponding negative images. Our experimental analysis confirms the relevance of the generated negative data, and its use in language-based detectors improves performance on two complex benchmarks.
Deep Deformable Models: Learning 3D Shape Abstractions with Part Consistency
Sep 02, 2023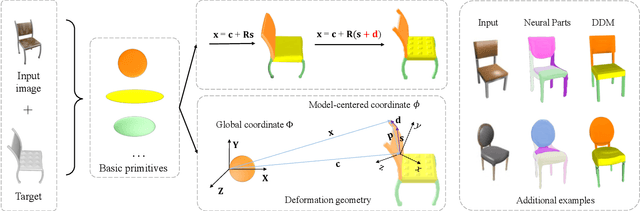
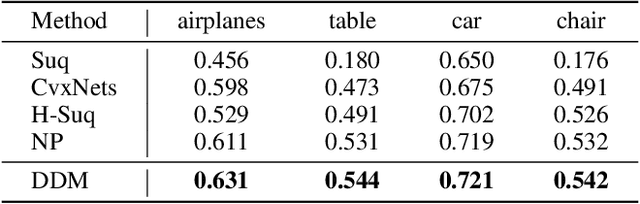
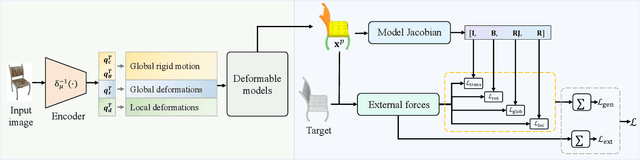
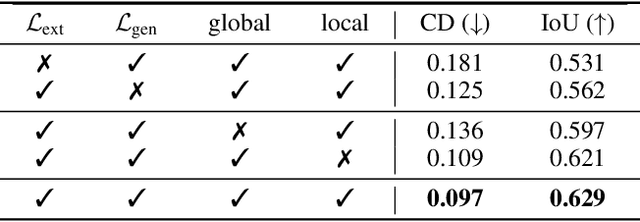
The task of shape abstraction with semantic part consistency is challenging due to the complex geometries of natural objects. Recent methods learn to represent an object shape using a set of simple primitives to fit the target. \textcolor{black}{However, in these methods, the primitives used do not always correspond to real parts or lack geometric flexibility for semantic interpretation.} In this paper, we investigate salient and efficient primitive descriptors for accurate shape abstractions, and propose \textit{Deep Deformable Models (DDMs)}. DDM employs global deformations and diffeomorphic local deformations. These properties enable DDM to abstract complex object shapes with significantly fewer primitives that offer broader geometry coverage and finer details. DDM is also capable of learning part-level semantic correspondences due to the differentiable and invertible properties of our primitive deformation. Moreover, DDM learning formulation is based on dynamic and kinematic modeling, which enables joint regularization of each sub-transformation during primitive fitting. Extensive experiments on \textit{ShapeNet} demonstrate that DDM outperforms the state-of-the-art in terms of reconstruction and part consistency by a notable margin.
Learning from Semantic Alignment between Unpaired Multiviews for Egocentric Video Recognition
Aug 23, 2023We are concerned with a challenging scenario in unpaired multiview video learning. In this case, the model aims to learn comprehensive multiview representations while the cross-view semantic information exhibits variations. We propose Semantics-based Unpaired Multiview Learning (SUM-L) to tackle this unpaired multiview learning problem. The key idea is to build cross-view pseudo-pairs and do view-invariant alignment by leveraging the semantic information of videos. To facilitate the data efficiency of multiview learning, we further perform video-text alignment for first-person and third-person videos, to fully leverage the semantic knowledge to improve video representations. Extensive experiments on multiple benchmark datasets verify the effectiveness of our framework. Our method also outperforms multiple existing view-alignment methods, under the more challenging scenario than typical paired or unpaired multimodal or multiview learning. Our code is available at https://github.com/wqtwjt1996/SUM-L.
Improving Pseudo Labels for Open-Vocabulary Object Detection
Aug 11, 2023Recent studies show promising performance in open-vocabulary object detection (OVD) using pseudo labels (PLs) from pretrained vision and language models (VLMs). However, PLs generated by VLMs are extremely noisy due to the gap between the pretraining objective of VLMs and OVD, which blocks further advances on PLs. In this paper, we aim to reduce the noise in PLs and propose a method called online Self-training And a Split-and-fusion head for OVD (SAS-Det). First, the self-training finetunes VLMs to generate high quality PLs while prevents forgetting the knowledge learned in the pretraining. Second, a split-and-fusion (SAF) head is designed to remove the noise in localization of PLs, which is usually ignored in existing methods. It also fuses complementary knowledge learned from both precise ground truth and noisy pseudo labels to boost the performance. Extensive experiments demonstrate SAS-Det is both efficient and effective. Our pseudo labeling is 3 times faster than prior methods. SAS-Det outperforms prior state-of-the-art models of the same scale by a clear margin and achieves 37.4 AP$_{50}$ and 27.3 AP$_r$ on novel categories of the COCO and LVIS benchmarks, respectively.
VideoGLUE: Video General Understanding Evaluation of Foundation Models
Jul 06, 2023



We evaluate existing foundation models video understanding capabilities using a carefully designed experiment protocol consisting of three hallmark tasks (action recognition, temporal localization, and spatiotemporal localization), eight datasets well received by the community, and four adaptation methods tailoring a foundation model (FM) for a downstream task. Moreover, we propose a scalar VideoGLUE score (VGS) to measure an FMs efficacy and efficiency when adapting to general video understanding tasks. Our main findings are as follows. First, task-specialized models significantly outperform the six FMs studied in this work, in sharp contrast to what FMs have achieved in natural language and image understanding. Second,video-native FMs, whose pretraining data contains the video modality, are generally better than image-native FMs in classifying motion-rich videos, localizing actions in time, and understanding a video of more than one action. Third, the video-native FMs can perform well on video tasks under light adaptations to downstream tasks(e.g., freezing the FM backbones), while image-native FMs win in full end-to-end finetuning. The first two observations reveal the need and tremendous opportunities to conduct research on video-focused FMs, and the last confirms that both tasks and adaptation methods matter when it comes to the evaluation of FMs.
Spatiotemporally Discriminative Video-Language Pre-Training with Text Grounding
Mar 28, 2023



Most of existing video-language pre-training methods focus on instance-level alignment between video clips and captions via global contrastive learning but neglect rich fine-grained local information, which is of importance to downstream tasks requiring temporal localization and semantic reasoning. In this work, we propose a simple yet effective video-language pre-training framework, namely G-ViLM, to learn discriminative spatiotemporal features. Two novel designs involving spatiotemporal grounding and temporal grouping promote learning local region-noun alignment and temporal-aware features simultaneously. Specifically, spatiotemporal grounding aggregates semantically similar video tokens and aligns them with noun phrases extracted from the caption to promote local region-noun correspondences. Moreover, temporal grouping leverages cut-and-paste to manually create temporal scene changes and then learns distinguishable features from different scenes. Comprehensive evaluations demonstrate that G-ViLM performs favorably against existing approaches on four representative downstream tasks, covering text-video retrieval, video question answering, video action recognition and temporal action localization. G-ViLM performs competitively on all evaluated tasks and in particular achieves R@10 of 65.1 on zero-shot MSR-VTT retrieval, over 9% higher than the state-of-the-art method.
Steering Prototype with Prompt-tuning for Rehearsal-free Continual Learning
Mar 16, 2023



Prototype, as a representation of class embeddings, has been explored to reduce memory footprint or mitigate forgetting for continual learning scenarios. However, prototype-based methods still suffer from abrupt performance deterioration due to semantic drift and prototype interference. In this study, we propose Contrastive Prototypical Prompt (CPP) and show that task-specific prompt-tuning, when optimized over a contrastive learning objective, can effectively address both obstacles and significantly improve the potency of prototypes. Our experiments demonstrate that CPP excels in four challenging class-incremental learning benchmarks, resulting in 4% to 6% absolute improvements over state-of-the-art methods. Moreover, CPP does not require a rehearsal buffer and it largely bridges the performance gap between continual learning and offline joint-learning, showcasing a promising design scheme for continual learning systems under a Transformer architecture.
Unified Visual Relationship Detection with Vision and Language Models
Mar 16, 2023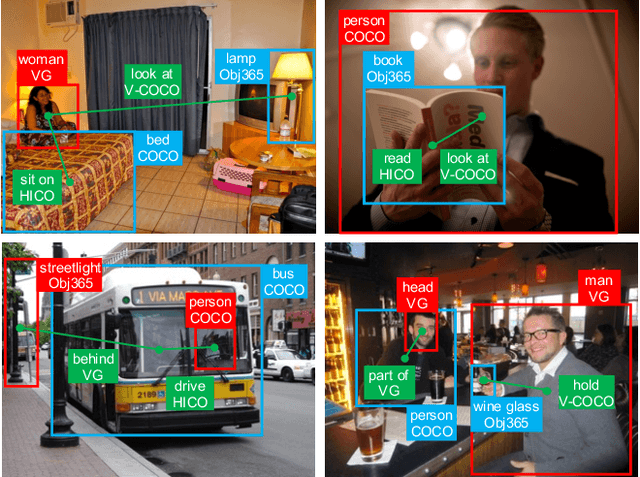
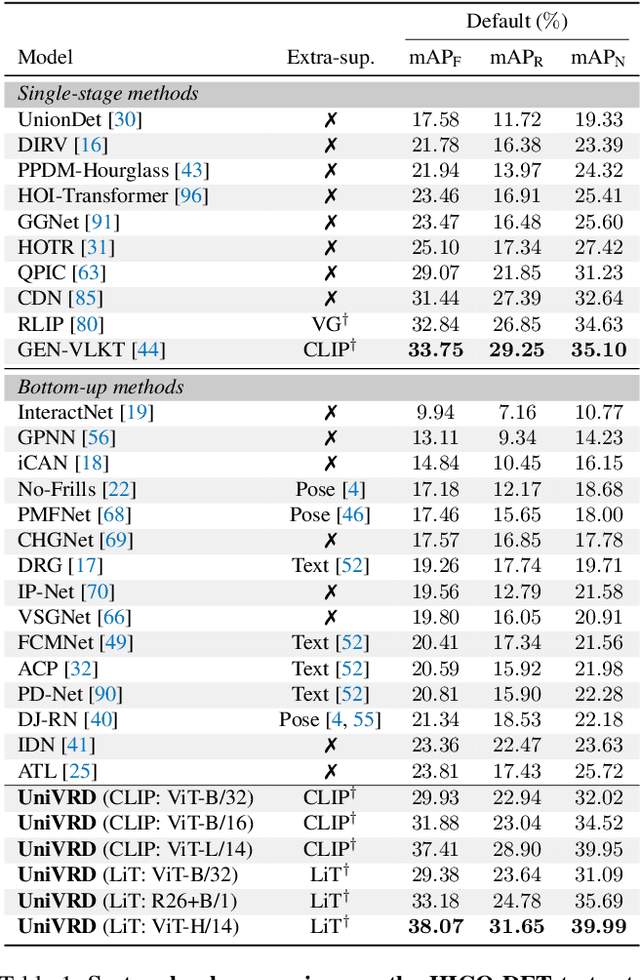
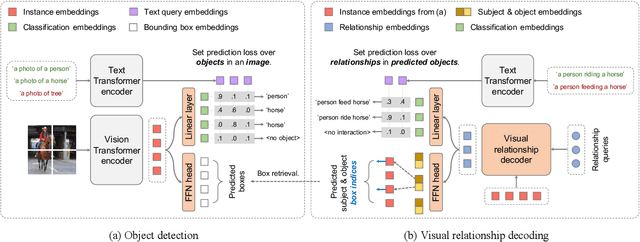
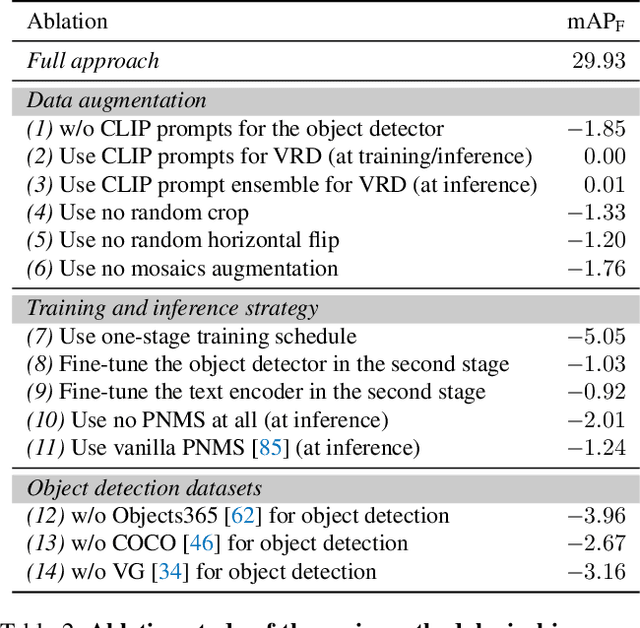
This work focuses on training a single visual relationship detector predicting over the union of label spaces from multiple datasets. Merging labels spanning different datasets could be challenging due to inconsistent taxonomies. The issue is exacerbated in visual relationship detection when second-order visual semantics are introduced between pairs of objects. To address this challenge, we propose UniVRD, a novel bottom-up method for Unified Visual Relationship Detection by leveraging vision and language models (VLMs). VLMs provide well-aligned image and text embeddings, where similar relationships are optimized to be close to each other for semantic unification. Our bottom-up design enables the model to enjoy the benefit of training with both object detection and visual relationship datasets. Empirical results on both human-object interaction detection and scene-graph generation demonstrate the competitive performance of our model. UniVRD achieves 38.07 mAP on HICO-DET, outperforming the current best bottom-up HOI detector by 60% relatively. More importantly, we show that our unified detector performs as well as dataset-specific models in mAP, and achieves further improvements when we scale up the model.
Hierarchically Self-Supervised Transformer for Human Skeleton Representation Learning
Jul 20, 2022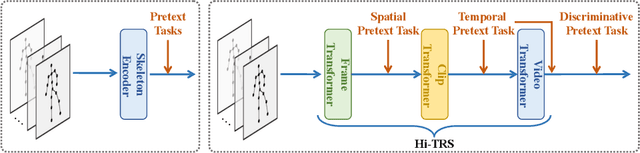
Despite the success of fully-supervised human skeleton sequence modeling, utilizing self-supervised pre-training for skeleton sequence representation learning has been an active field because acquiring task-specific skeleton annotations at large scales is difficult. Recent studies focus on learning video-level temporal and discriminative information using contrastive learning, but overlook the hierarchical spatial-temporal nature of human skeletons. Different from such superficial supervision at the video level, we propose a self-supervised hierarchical pre-training scheme incorporated into a hierarchical Transformer-based skeleton sequence encoder (Hi-TRS), to explicitly capture spatial, short-term, and long-term temporal dependencies at frame, clip, and video levels, respectively. To evaluate the proposed self-supervised pre-training scheme with Hi-TRS, we conduct extensive experiments covering three skeleton-based downstream tasks including action recognition, action detection, and motion prediction. Under both supervised and semi-supervised evaluation protocols, our method achieves the state-of-the-art performance. Additionally, we demonstrate that the prior knowledge learned by our model in the pre-training stage has strong transfer capability for different downstream tasks.
Exploiting Unlabeled Data with Vision and Language Models for Object Detection
Jul 18, 2022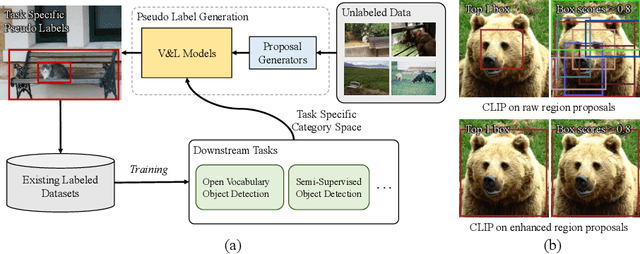
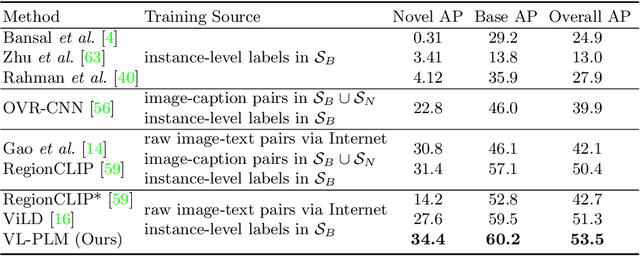
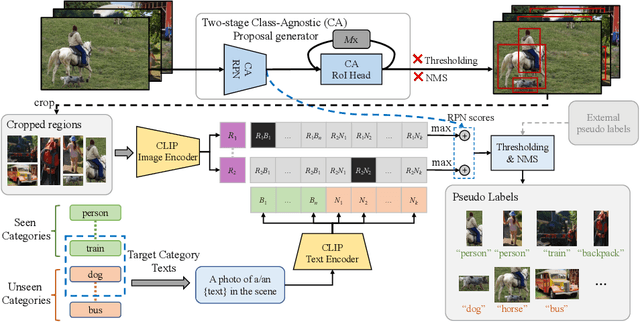

Building robust and generic object detection frameworks requires scaling to larger label spaces and bigger training datasets. However, it is prohibitively costly to acquire annotations for thousands of categories at a large scale. We propose a novel method that leverages the rich semantics available in recent vision and language models to localize and classify objects in unlabeled images, effectively generating pseudo labels for object detection. Starting with a generic and class-agnostic region proposal mechanism, we use vision and language models to categorize each region of an image into any object category that is required for downstream tasks. We demonstrate the value of the generated pseudo labels in two specific tasks, open-vocabulary detection, where a model needs to generalize to unseen object categories, and semi-supervised object detection, where additional unlabeled images can be used to improve the model. Our empirical evaluation shows the effectiveness of the pseudo labels in both tasks, where we outperform competitive baselines and achieve a novel state-of-the-art for open-vocabulary object detection. Our code is available at https://github.com/xiaofeng94/VL-PLM.