 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCQPR: Proactive Conversational Question Planning with Reflection
Oct 02, 2024



Conversational Question Generation (CQG) enhances the interactivity of conversational question-answering systems in fields such as education, customer service, and entertainment. However, traditional CQG, focusing primarily on the immediate context, lacks the conversational foresight necessary to guide conversations toward specified conclusions. This limitation significantly restricts their ability to achieve conclusion-oriented conversational outcomes. In this work, we redefine the CQG task as Conclusion-driven Conversational Question Generation (CCQG) by focusing on proactivity, not merely reacting to the unfolding conversation but actively steering it towards a conclusion-oriented question-answer pair. To address this, we propose a novel approach, called Proactive Conversational Question Planning with self-Refining (PCQPR). Concretely, by integrating a planning algorithm inspired by Monte Carlo Tree Search (MCTS) with the analytical capabilities of large language models (LLMs), PCQPR predicts future conversation turns and continuously refines its questioning strategies. This iterative self-refining mechanism ensures the generation of contextually relevant questions strategically devised to reach a specified outcome. Our extensive evaluations demonstrate that PCQPR significantly surpasses existing CQG methods, marking a paradigm shift towards conclusion-oriented conversational question-answering systems.
* Accepted by EMNLP 2024 Main
Retrieval Augmented Generation for Dynamic Graph Modeling
Aug 26, 2024



Dynamic graph modeling is crucial for analyzing evolving patterns in various applications. Existing approaches often integrate graph neural networks with temporal modules or redefine dynamic graph modeling as a generative sequence task. However, these methods typically rely on isolated historical contexts of the target nodes from a narrow perspective, neglecting occurrences of similar patterns or relevant cases associated with other nodes. In this work, we introduce the Retrieval-Augmented Generation for Dynamic Graph Modeling (RAG4DyG) framework, which leverages guidance from contextually and temporally analogous examples to broaden the perspective of each node. This approach presents two critical challenges: (1) How to identify and retrieve high-quality demonstrations that are contextually and temporally analogous to dynamic graph samples? (2) How can these demonstrations be effectively integrated to improve dynamic graph modeling? To address these challenges, we propose RAG4DyG, which enriches the understanding of historical contexts by retrieving and learning from contextually and temporally pertinent demonstrations. Specifically, we employ a time- and context-aware contrastive learning module to identify and retrieve relevant cases for each query sequence. Moreover, we design a graph fusion strategy to integrate the retrieved cases, thereby augmenting the inherent historical contexts for improved prediction. Extensive experiments on real-world datasets across different domains demonstrate the effectiveness of RAG4DyG for dynamic graph modeling.
Planning Like Human: A Dual-process Framework for Dialogue Planning
Jun 08, 2024



In proactive dialogue, the challenge lies not just in generating responses but in steering conversations toward predetermined goals, a task where Large Language Models (LLMs) typically struggle due to their reactive nature. Traditional approaches to enhance dialogue planning in LLMs, ranging from elaborate prompt engineering to the integration of policy networks, either face efficiency issues or deliver suboptimal performance. Inspired by the dualprocess theory in psychology, which identifies two distinct modes of thinking - intuitive (fast) and analytical (slow), we propose the Dual-Process Dialogue Planning (DPDP) framework. DPDP embodies this theory through two complementary planning systems: an instinctive policy model for familiar contexts and a deliberative Monte Carlo Tree Search (MCTS) mechanism for complex, novel scenarios. This dual strategy is further coupled with a novel two-stage training regimen: offline Reinforcement Learning for robust initial policy model formation followed by MCTS-enhanced on-the-fly learning, which ensures a dynamic balance between efficiency and strategic depth. Our empirical evaluations across diverse dialogue tasks affirm DPDP's superiority in achieving both high-quality dialogues and operational efficiency, outpacing existing methods.
Analyzing Temporal Complex Events with Large Language Models? A Benchmark towards Temporal, Long Context Understanding
Jun 04, 2024



The digital landscape is rapidly evolving with an ever-increasing volume of online news, emphasizing the need for swift and precise analysis of complex events. We refer to the complex events composed of many news articles over an extended period as Temporal Complex Event (TCE). This paper proposes a novel approach using Large Language Models (LLMs) to systematically extract and analyze the event chain within TCE, characterized by their key points and timestamps. We establish a benchmark, named TCELongBench, to evaluate the proficiency of LLMs in handling temporal dynamics and understanding extensive text. This benchmark encompasses three distinct tasks - reading comprehension, temporal sequencing, and future event forecasting. In the experiment, we leverage retrieval-augmented generation (RAG) method and LLMs with long context window to deal with lengthy news articles of TCE. Our findings indicate that models with suitable retrievers exhibit comparable performance with those utilizing long context window.
Towards Human-centered Proactive Conversational Agents
Apr 19, 2024



Recent research on proactive conversational agents (PCAs) mainly focuses on improving the system's capabilities in anticipating and planning action sequences to accomplish tasks and achieve goals before users articulate their requests. This perspectives paper highlights the importance of moving towards building human-centered PCAs that emphasize human needs and expectations, and that considers ethical and social implications of these agents, rather than solely focusing on technological capabilities. The distinction between a proactive and a reactive system lies in the proactive system's initiative-taking nature. Without thoughtful design, proactive systems risk being perceived as intrusive by human users. We address the issue by establishing a new taxonomy concerning three key dimensions of human-centered PCAs, namely Intelligence, Adaptivity, and Civility. We discuss potential research opportunities and challenges based on this new taxonomy upon the five stages of PCA system construction. This perspectives paper lays a foundation for the emerging area of conversational information retrieval research and paves the way towards advancing human-centered proactive conversational systems.
Multilingual Large Language Model: A Survey of Resources, Taxonomy and Frontiers
Apr 07, 2024

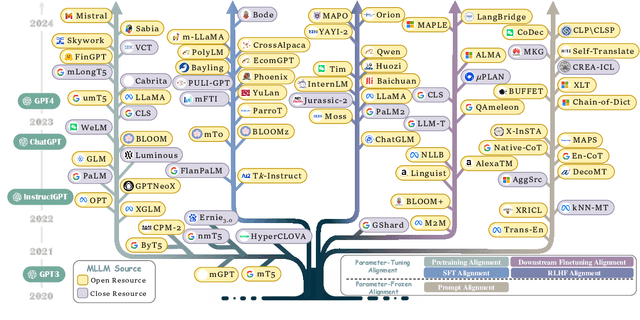
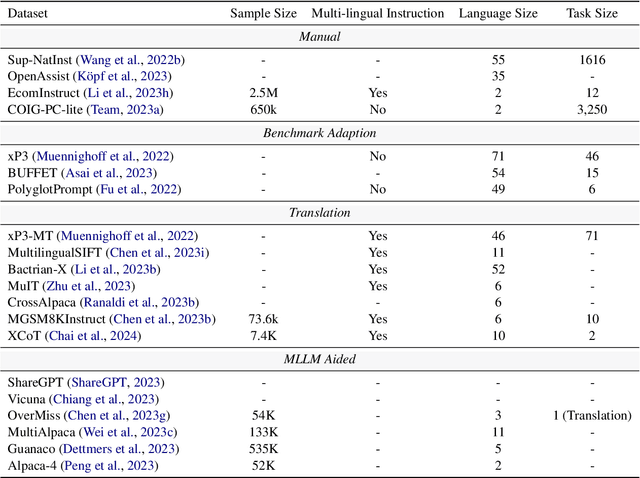
Multilingual Large Language Models are capable of using powerful Large Language Models to handle and respond to queries in multiple languages, which achieves remarkable success in multilingual natural language processing tasks. Despite these breakthroughs, there still remains a lack of a comprehensive survey to summarize existing approaches and recent developments in this field. To this end, in this paper, we present a thorough review and provide a unified perspective to summarize the recent progress as well as emerging trends in multilingual large language models (MLLMs) literature. The contributions of this paper can be summarized: (1) First survey: to our knowledge, we take the first step and present a thorough review in MLLMs research field according to multi-lingual alignment; (2) New taxonomy: we offer a new and unified perspective to summarize the current progress of MLLMs; (3) New frontiers: we highlight several emerging frontiers and discuss the corresponding challenges; (4) Abundant resources: we collect abundant open-source resources, including relevant papers, data corpora, and leaderboards. We hope our work can provide the community with quick access and spur breakthrough research in MLLMs.
SGSH: Stimulate Large Language Models with Skeleton Heuristics for Knowledge Base Question Generation
Apr 02, 2024



Knowledge base question generation (KBQG) aims to generate natural language questions from a set of triplet facts extracted from KB. Existing methods have significantly boosted the performance of KBQG via pre-trained language models (PLMs) thanks to the richly endowed semantic knowledge. With the advance of pre-training techniques, large language models (LLMs) (e.g., GPT-3.5) undoubtedly possess much more semantic knowledge. Therefore, how to effectively organize and exploit the abundant knowledge for KBQG becomes the focus of our study. In this work, we propose SGSH--a simple and effective framework to Stimulate GPT-3.5 with Skeleton Heuristics to enhance KBQG. The framework incorporates "skeleton heuristics", which provides more fine-grained guidance associated with each input to stimulate LLMs to generate optimal questions, encompassing essential elements like the question phrase and the auxiliary verb.More specifically, we devise an automatic data construction strategy leveraging ChatGPT to construct a skeleton training dataset, based on which we employ a soft prompting approach to train a BART model dedicated to generating the skeleton associated with each input. Subsequently, skeleton heuristics are encoded into the prompt to incentivize GPT-3.5 to generate desired questions. Extensive experiments demonstrate that SGSH derives the new state-of-the-art performance on the KBQG tasks.
Mix-Initiative Response Generation with Dynamic Prefix Tuning
Mar 27, 2024



Mixed initiative serves as one of the key factors in controlling conversation directions. For a speaker, responding passively or leading proactively would result in rather different responses. However, most dialogue systems focus on training a holistic response generation model without any distinction among different initiatives. It leads to the cross-contamination problem, where the model confuses different initiatives and generates inappropriate responses. Moreover, obtaining plenty of human annotations for initiative labels can be expensive. To address this issue, we propose a general mix-Initiative Dynamic Prefix Tuning framework (IDPT) to decouple different initiatives from the generation model, which learns initiative-aware prefixes in both supervised and unsupervised settings. Specifically, IDPT decouples initiative factors into different prefix parameters and uses the attention mechanism to adjust the selection of initiatives in guiding generation dynamically. The prefix parameters can be tuned towards accurate initiative prediction as well as mix-initiative response generation. Extensive experiments on two public dialogue datasets show that the proposed IDPT outperforms previous baselines on both automatic metrics and human evaluations. It also manages to generate appropriate responses with manipulated initiatives.
Multi-party Response Generation with Relation Disentanglement
Mar 23, 2024



Existing neural response generation models have achieved impressive improvements for two-party conversations, which assume that utterances are sequentially organized. However, many real-world dialogues involve multiple interlocutors and the structure of conversational context is much more complex, e.g. utterances from different interlocutors can occur "in parallel". Facing this challenge, there are works trying to model the relations among utterances or interlocutors to facilitate response generation with clearer context. Nonetheless, these methods rely heavily on such relations and all assume that these are given beforehand, which is impractical and hinders the generality of such methods. In this work, we propose to automatically infer the relations via relational thinking on subtle clues inside the conversation context without any human label, and leverage these relations to guide the neural response generation. Specifically, we first apply a deep graph random process to fully consider all possible relations among utterances in the conversational context. Then the inferred relation graphs are integrated with a variational auto-encoder framework to train a GAN for structure-aware response generation. Experimental results on the Ubuntu Internet Relay Chat (IRC) channel benchmark and the most recent Movie Dialogues show that our method outperforms various baseline models for multi-party response generation.
Contrastive Pre-training for Deep Session Data Understanding
Mar 05, 2024Session data has been widely used for understanding user's behavior in e-commerce. Researchers are trying to leverage session data for different tasks, such as purchase intention prediction, remaining length prediction, recommendation, etc., as it provides context clues about the user's dynamic interests. However, online shopping session data is semi-structured and complex in nature, which contains both unstructured textual data about the products, search queries, and structured user action sequences. Most existing works focus on leveraging the coarse-grained item sequences for specific tasks, while largely ignore the fine-grained information from text and user action details. In this work, we delve into deep session data understanding via scrutinizing the various clues inside the rich information in user sessions. Specifically, we propose to pre-train a general-purpose User Behavior Model (UBM) over large-scale session data with rich details, such as product title, attributes and various kinds of user actions. A two-stage pre-training scheme is introduced to encourage the model to self-learn from various augmentations with contrastive learning objectives, which spans different granularity levels of session data. Then the well-trained session understanding model can be easily fine-tuned for various downstream tasks. Extensive experiments show that UBM better captures the complex intra-item semantic relations, inter-item connections and inter-interaction dependencies, leading to large performance gains as compared to the baselines on several downstream tasks. And it also demonstrates strong robustness when data is sparse.