 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Rollout Editing for Reducing Overthinking in RL-Trained Reasoning Models
Jun 16, 2026Long-form chain-of-thought reasoning can improve LLM performance on complex tasks, but models often continue generating unnecessary reasoning after a correct answer has emerged. We refer to this behavior as overthinking. We study this phenomenon from the perspective of GRPO-style reinforcement learning (RL) post-training, framing it as a training-time credit-assignment problem rather than merely a decoding-time stopping problem. In rollouts sampled at the onset of GRPO training, we observe that successful trajectories can exhibit a slightly higher degree of overthinking than unsuccessful trajectories for the same prompts. This early imbalance provides a starting point for an undesirable feedback loop: because GRPO assigns sequence-level credit, it cannot distinguish the solution-reaching prefix from the unnecessary continuation that lengthens a successful trajectory. Both receive positive update signal, allowing the initial imbalance to grow into more severe overthinking during training. To address this issue, we introduce Dynamic Rollout Editing (DRE), a training-time intervention for successful trajectories that continue thinking after answer emergence. DRE preserves the accepted verified prefix, edits the remaining thinking, and prefers the edited trajectory within the same RL group, weakening the preference signal for unnecessary thinking without penalizing the reasoning needed to reach the answer. Experiments across diverse tasks show the effectiveness of DRE.
SkillAudit: Ground-Truth-Free Skill Evolution via Paired Trajectory Auditing
Jun 12, 2026Agent skills are structured procedural packages that guide frozen LLM agents in specialized workflows. Skills rarely remain sufficient after deployment: edge cases, API changes, and deployment constraints become visible only through use, making skill evolution a practical necessity. Existing methods depend on privileged feedback such as held-out validation scores, hidden test outcomes, or environment rewards -- signals often unavailable when a practitioner has only a task description and workspace data. We introduce SkillAudit, a framework for evolving agent skills without ground-truth feedback. The key idea is paired trajectory auditing: at each iteration, the same task is executed with and without the candidate skill, isolating how the skill changes agent behavior without external labels. To turn behavioral differences into edit guidance, SkillAudit uses Process-Aligned Contrastive Evaluation (PACE), a cluster of evaluators that maps trajectory divergences to diagnostic signals linked to specific passages in the skill document. A structural verifier, compiled once from the task specification and then fixed, checks task constraints and rolls back harmful updates. SkillAudit routes edits through two pipelines: Refine removes noisy or irrelevant guidance from broadly useful skills, while Repair replaces passages that conflict with the task. Across 89 containerized tasks spanning 8 professional domains, SkillAudit achieves 73.9% average task reward, outperforming an agent without skills (40.9%) and the static expert skill (56.7%). These gains are obtained without accessing hidden tests, reference solutions, or external scoring functions during evolution.
ActiveMem: Distributed Active Memory for Long-Horizon LLM Reasoning
Jun 09, 2026Memory is essential for enabling large language model (LLM) agents to handle long-horizon reasoning tasks. Existing memory mechanisms are largely centralized, typically organizing retrieved information and interaction history within a single model context. This design imposes a fundamental trade-off: scaling reasoning trajectories risks context overload, whereas aggressive content pruning may result in irreversible information loss. Seeking a better trade-off, we draw inspiration from human cognitive systems, especially the functional complementarity between the prefrontal cortex (executive control) and the hippocampus (memory management), suggesting that such a trade-off need not be inherent, but may instead stem from centralized memory organization. To this end, we propose ActiveMem, a heterogeneous framework that decouples agent memory from the core reasoning process. Specifically, a high-level Planner utilizes distilled semantic gists to execute reasoning, while a lightweight, distributed memory system operates in parallel to actively accumulate and consolidate these gists throughout the task. Experiments on BrowseComp-Plus and GAIA show that ActiveMem achieves state-of-the-art accuracy with significantly reduced overhead, demonstrating the effectiveness of distributed active memory for long-horizon reasoning.
VisualSimpleQA: A Benchmark for Decoupled Evaluation of Large Vision-Language Models in Fact-Seeking Question Answering
Mar 09, 2025Large vision-language models (LVLMs) have demonstrated remarkable achievements, yet the generation of non-factual responses remains prevalent in fact-seeking question answering (QA). Current multimodal fact-seeking benchmarks primarily focus on comparing model outputs to ground truth answers, providing limited insights into the performance of modality-specific modules. To bridge this gap, we introduce VisualSimpleQA, a multimodal fact-seeking benchmark with two key features. First, it enables streamlined and decoupled evaluation of LVLMs in visual and linguistic modalities. Second, it incorporates well-defined difficulty criteria to guide human annotation and facilitates the extraction of a challenging subset, VisualSimpleQA-hard. Experiments on 15 LVLMs show that even state-of-the-art models such as GPT-4o achieve merely 60%+ correctness in multimodal fact-seeking QA on VisualSimpleQA and 30%+ on VisualSimpleQA-hard. Furthermore, the decoupled evaluation across these models highlights substantial opportunities for improvement in both visual and linguistic modules. The dataset is available at https://huggingface.co/datasets/WYLing/VisualSimpleQA.
PCQPR: Proactive Conversational Question Planning with Reflection
Oct 02, 2024



Conversational Question Generation (CQG) enhances the interactivity of conversational question-answering systems in fields such as education, customer service, and entertainment. However, traditional CQG, focusing primarily on the immediate context, lacks the conversational foresight necessary to guide conversations toward specified conclusions. This limitation significantly restricts their ability to achieve conclusion-oriented conversational outcomes. In this work, we redefine the CQG task as Conclusion-driven Conversational Question Generation (CCQG) by focusing on proactivity, not merely reacting to the unfolding conversation but actively steering it towards a conclusion-oriented question-answer pair. To address this, we propose a novel approach, called Proactive Conversational Question Planning with self-Refining (PCQPR). Concretely, by integrating a planning algorithm inspired by Monte Carlo Tree Search (MCTS) with the analytical capabilities of large language models (LLMs), PCQPR predicts future conversation turns and continuously refines its questioning strategies. This iterative self-refining mechanism ensures the generation of contextually relevant questions strategically devised to reach a specified outcome. Our extensive evaluations demonstrate that PCQPR significantly surpasses existing CQG methods, marking a paradigm shift towards conclusion-oriented conversational question-answering systems.
* Accepted by EMNLP 2024 Main
A Label-Free and Non-Monotonic Metric for Evaluating Denoising in Event Cameras
Jun 13, 2024



Event cameras are renowned for their high efficiency due to outputting a sparse, asynchronous stream of events. However, they are plagued by noisy events, especially in low light conditions. Denoising is an essential task for event cameras, but evaluating denoising performance is challenging. Label-dependent denoising metrics involve artificially adding noise to clean sequences, complicating evaluations. Moreover, the majority of these metrics are monotonic, which can inflate scores by removing substantial noise and valid events. To overcome these limitations, we propose the first label-free and non-monotonic evaluation metric, the area of the continuous contrast curve (AOCC), which utilizes the area enclosed by event frame contrast curves across different time intervals. This metric is inspired by how events capture the edge contours of scenes or objects with high temporal resolution. An effective denoising method removes noise without eliminating these edge-contour events, thus preserving the contrast of event frames. Consequently, contrast across various time ranges serves as a metric to assess denoising effectiveness. As the time interval lengthens, the curve will initially rise and then fall. The proposed metric is validated through both theoretical and experimental evidence.
SGSH: Stimulate Large Language Models with Skeleton Heuristics for Knowledge Base Question Generation
Apr 02, 2024



Knowledge base question generation (KBQG) aims to generate natural language questions from a set of triplet facts extracted from KB. Existing methods have significantly boosted the performance of KBQG via pre-trained language models (PLMs) thanks to the richly endowed semantic knowledge. With the advance of pre-training techniques, large language models (LLMs) (e.g., GPT-3.5) undoubtedly possess much more semantic knowledge. Therefore, how to effectively organize and exploit the abundant knowledge for KBQG becomes the focus of our study. In this work, we propose SGSH--a simple and effective framework to Stimulate GPT-3.5 with Skeleton Heuristics to enhance KBQG. The framework incorporates "skeleton heuristics", which provides more fine-grained guidance associated with each input to stimulate LLMs to generate optimal questions, encompassing essential elements like the question phrase and the auxiliary verb.More specifically, we devise an automatic data construction strategy leveraging ChatGPT to construct a skeleton training dataset, based on which we employ a soft prompting approach to train a BART model dedicated to generating the skeleton associated with each input. Subsequently, skeleton heuristics are encoded into the prompt to incentivize GPT-3.5 to generate desired questions. Extensive experiments demonstrate that SGSH derives the new state-of-the-art performance on the KBQG tasks.
A Survey on Neural Question Generation: Methods, Applications, and Prospects
Feb 28, 2024

In this survey, we present a detailed examination of the advancements in Neural Question Generation (NQG), a field leveraging neural network techniques to generate relevant questions from diverse inputs like knowledge bases, texts, and images. The survey begins with an overview of NQG's background, encompassing the task's problem formulation, prevalent benchmark datasets, established evaluation metrics, and notable applications. It then methodically classifies NQG approaches into three predominant categories: structured NQG, which utilizes organized data sources, unstructured NQG, focusing on more loosely structured inputs like texts or visual content, and hybrid NQG, drawing on diverse input modalities. This classification is followed by an in-depth analysis of the distinct neural network models tailored for each category, discussing their inherent strengths and potential limitations. The survey culminates with a forward-looking perspective on the trajectory of NQG, identifying emergent research trends and prospective developmental paths. Accompanying this survey is a curated collection of related research papers, datasets and codes, systematically organized on Github, providing an extensive reference for those delving into NQG.
Diversifying Question Generation over Knowledge Base via External Natural Questions
Sep 23, 2023



Previous methods on knowledge base question generation (KBQG) primarily focus on enhancing the quality of a single generated question. Recognizing the remarkable paraphrasing ability of humans, we contend that diverse texts should convey the same semantics through varied expressions. The above insights make diversifying question generation an intriguing task, where the first challenge is evaluation metrics for diversity. Current metrics inadequately assess the above diversity since they calculate the ratio of unique n-grams in the generated question itself, which leans more towards measuring duplication rather than true diversity. Accordingly, we devise a new diversity evaluation metric, which measures the diversity among top-k generated questions for each instance while ensuring their relevance to the ground truth. Clearly, the second challenge is how to enhance diversifying question generation. To address this challenge, we introduce a dual model framework interwoven by two selection strategies to generate diverse questions leveraging external natural questions. The main idea of our dual framework is to extract more diverse expressions and integrate them into the generation model to enhance diversifying question generation. Extensive experiments on widely used benchmarks for KBQG demonstrate that our proposed approach generates highly diverse questions and improves the performance of question answering tasks.
SeqXFilter: A Memory-efficient Denoising Filter for Dynamic Vision Sensors
Jun 02, 2020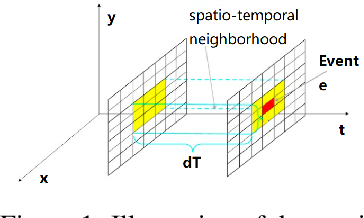
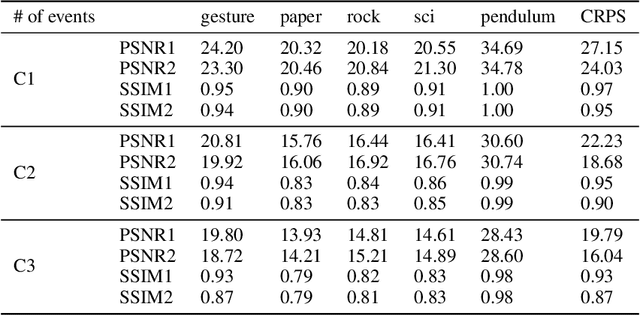
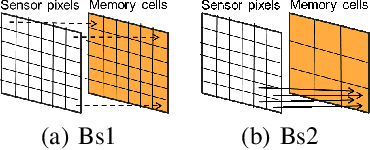
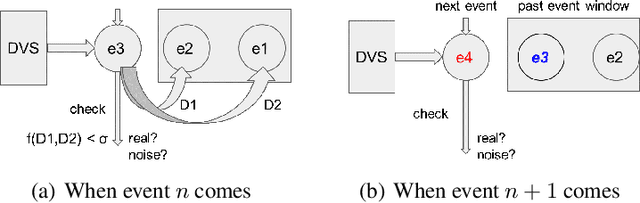
Neuromorphic event-based dynamic vision sensors (DVS) have much faster sampling rates and a higher dynamic range than frame-based imaging sensors. However, they are sensitive to background activity (BA) events that are unwanted. There are some filters for tackling this problem based on spatio-temporal correlation. However, they are either memory-intensive or computing-intensive. We propose \emph{SeqXFilter}, a spatio-temporal correlation filter with only a past event window that has an O(1) space complexity and has simple computations. We explore the spatial correlation of an event with its past few events by analyzing the distribution of the events when applying different functions on the spatial distances. We find the best function to check the spatio-temporal correlation for an event for \emph{SeqXFilter}, best separating real events and noise events. We not only give the visual denoising effect of the filter but also use two metrics for quantitatively analyzing the filter's performance. Four neuromorphic event-based datasets, recorded from four DVS with different output sizes, are used for validation of our method. The experimental results show that \emph{SeqXFilter} achieves similar performance as baseline NNb filters, but with extremely small memory cost and simple computation logic.