 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMining Implicit Relevance Feedback from User Behavior for Web Question Answering
Jun 16, 2020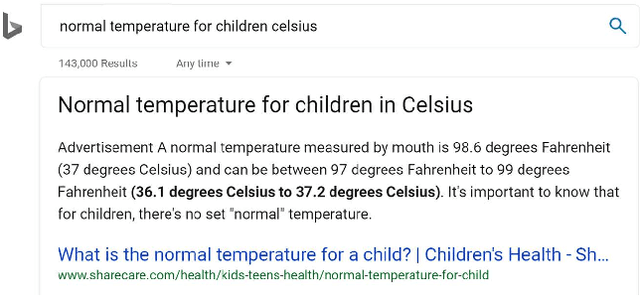
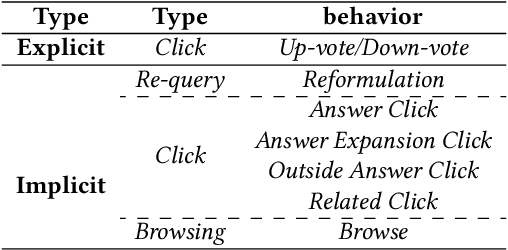
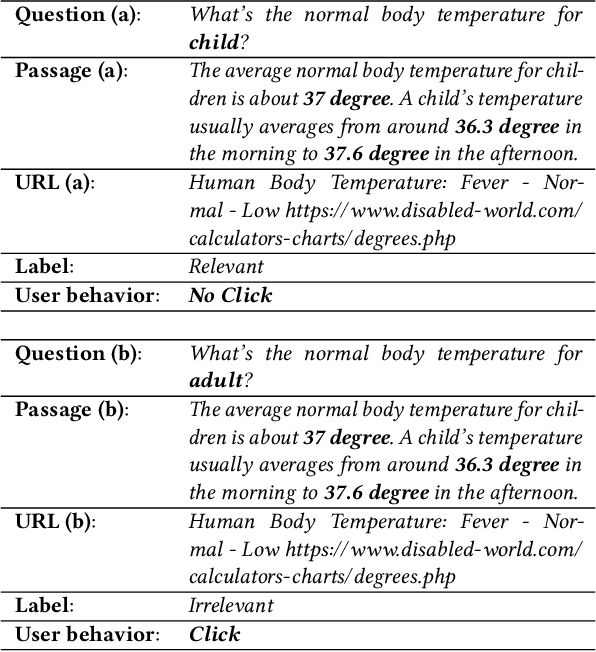
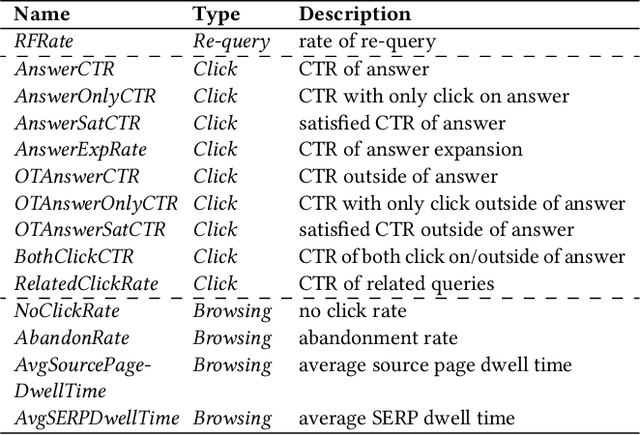
Training and refreshing a web-scale Question Answering (QA) system for a multi-lingual commercial search engine often requires a huge amount of training examples. One principled idea is to mine implicit relevance feedback from user behavior recorded in search engine logs. All previous works on mining implicit relevance feedback target at relevance of web documents rather than passages. Due to several unique characteristics of QA tasks, the existing user behavior models for web documents cannot be applied to infer passage relevance. In this paper, we make the first study to explore the correlation between user behavior and passage relevance, and propose a novel approach for mining training data for Web QA. We conduct extensive experiments on four test datasets and the results show our approach significantly improves the accuracy of passage ranking without extra human labeled data. In practice, this work has proved effective to substantially reduce the human labeling cost for the QA service in a global commercial search engine, especially for languages with low resources. Our techniques have been deployed in multi-language services.
Enhancing Answer Boundary Detection for Multilingual Machine Reading Comprehension
May 08, 2020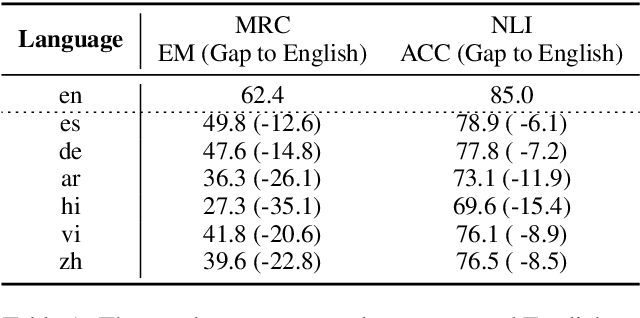
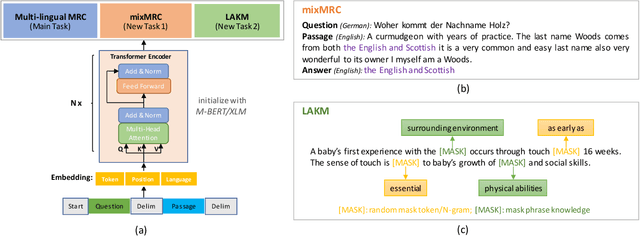
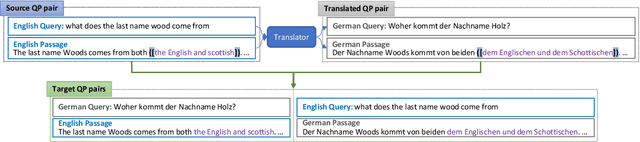
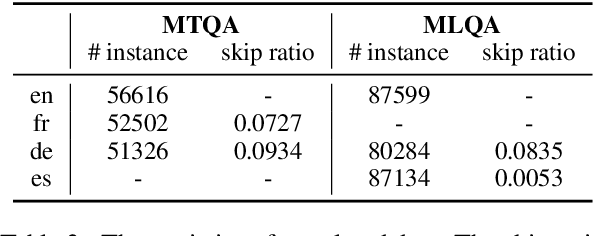
Multilingual pre-trained models could leverage the training data from a rich source language (such as English) to improve performance on low resource languages. However, the transfer quality for multilingual Machine Reading Comprehension (MRC) is significantly worse than sentence classification tasks mainly due to the requirement of MRC to detect the word level answer boundary. In this paper, we propose two auxiliary tasks in the fine-tuning stage to create additional phrase boundary supervision: (1) A mixed MRC task, which translates the question or passage to other languages and builds cross-lingual question-passage pairs; (2) A language-agnostic knowledge masking task by leveraging knowledge phrases mined from web. Besides, extensive experiments on two cross-lingual MRC datasets show the effectiveness of our proposed approach.
LogicalFactChecker: Leveraging Logical Operations for Fact Checking with Graph Module Network
Apr 28, 2020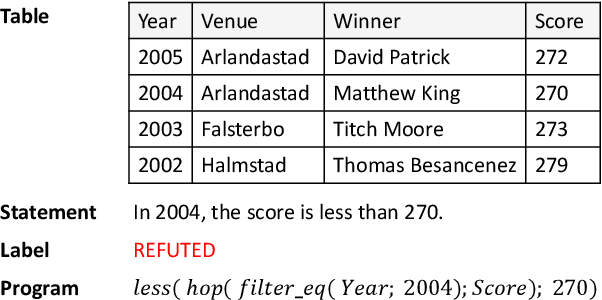
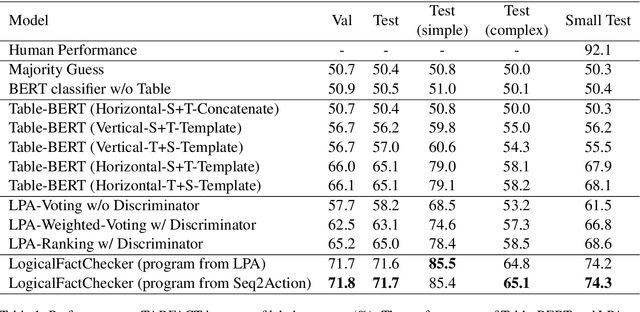
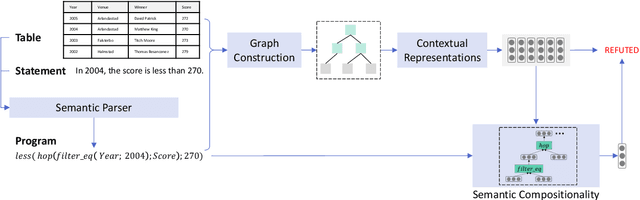
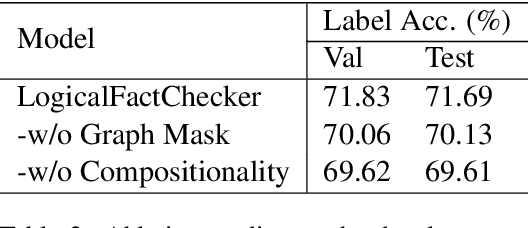
Verifying the correctness of a textual statement requires not only semantic reasoning about the meaning of words, but also symbolic reasoning about logical operations like count, superlative, aggregation, etc. In this work, we propose LogicalFactChecker, a neural network approach capable of leveraging logical operations for fact checking. It achieves the state-of-the-art performance on TABFACT, a large-scale, benchmark dataset built for verifying a textual statement with semi-structured tables. This is achieved by a graph module network built upon the Transformer-based architecture. With a textual statement and a table as the input, LogicalFactChecker automatically derives a program (a.k.a. logical form) of the statement in a semantic parsing manner. A heterogeneous graph is then constructed to capture not only the structures of the table and the program, but also the connections between inputs with different modalities. Such a graph reveals the related contexts of each word in the statement, the table and the program. The graph is used to obtain graph-enhanced contextual representations of words in Transformer-based architecture. After that, a program-driven module network is further introduced to exploit the hierarchical structure of the program, where semantic compositionality is dynamically modeled along the program structure with a set of function-specific modules. Ablation experiments suggest that both the heterogeneous graph and the module network are important to obtain strong results.
XGLUE: A New Benchmark Dataset for Cross-lingual Pre-training, Understanding and Generation
Apr 19, 2020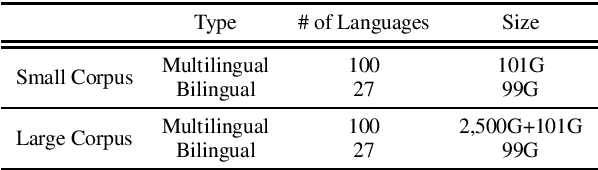
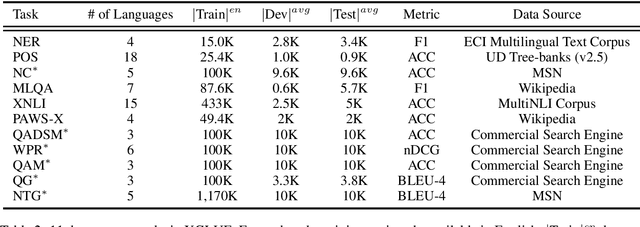
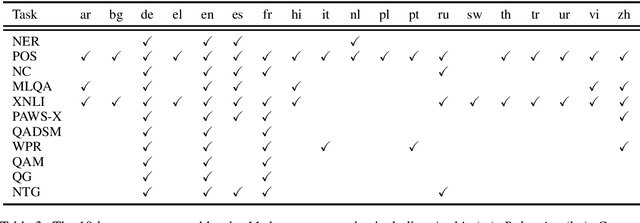
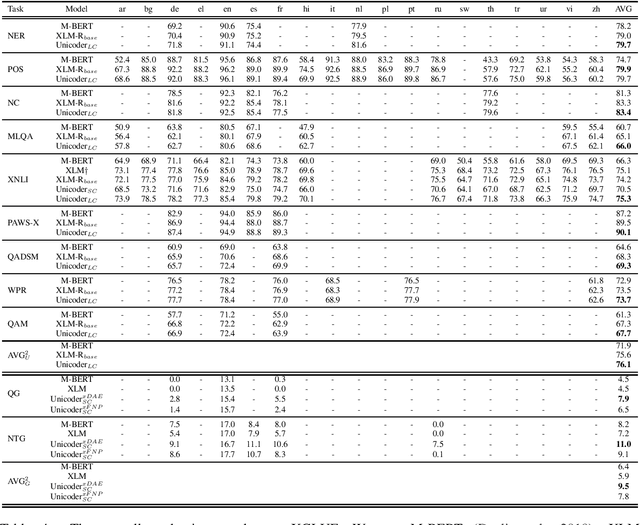
In this paper, we introduce XGLUE, a new benchmark dataset to train large-scale cross-lingual pre-trained models using multilingual and bilingual corpora, and evaluate their performance across a diverse set of cross-lingual tasks. Comparing to GLUE (Wang et al.,2019), which is labeled in English and includes natural language understanding tasks only, XGLUE has three main advantages: (1) it provides two corpora with different sizes for cross-lingual pre-training; (2) it provides 11 diversified tasks that cover both natural language understanding and generation scenarios; (3) for each task, it provides labeled data in multiple languages. We extend a recent cross-lingual pre-trained model Unicoder (Huang et al., 2019) to cover both understanding and generation tasks, which is evaluated on XGLUE as a strong baseline. We also evaluate the base versions (12-layer) of Multilingual BERT, XLM and XLM-R for comparison.
Inferential Text Generation with Multiple Knowledge Sources and Meta-Learning
Apr 15, 2020
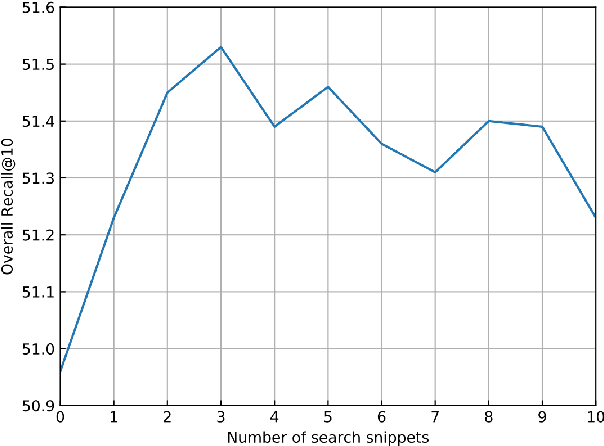
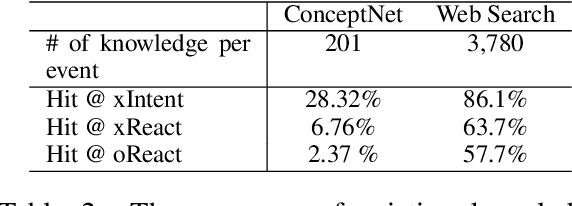
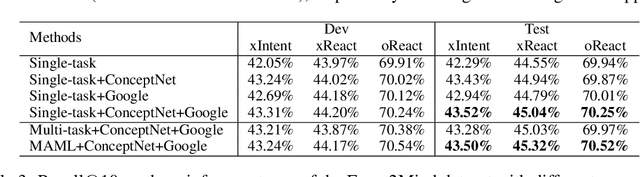
We study the problem of generating inferential texts of events for a variety of commonsense like \textit{if-else} relations. Existing approaches typically use limited evidence from training examples and learn for each relation individually. In this work, we use multiple knowledge sources as fuels for the model. Existing commonsense knowledge bases like ConceptNet are dominated by taxonomic knowledge (e.g., \textit{isA} and \textit{relatedTo} relations), having a limited number of inferential knowledge. We use not only structured commonsense knowledge bases, but also natural language snippets from search-engine results. These sources are incorporated into a generative base model via key-value memory network. In addition, we introduce a meta-learning based multi-task learning algorithm. For each targeted commonsense relation, we regard the learning of examples from other relations as the meta-training process, and the evaluation on examples from the targeted relation as the meta-test process. We conduct experiments on Event2Mind and ATOMIC datasets. Results show that both the integration of multiple knowledge sources and the use of the meta-learning algorithm improve the performance.
Pre-training Text Representations as Meta Learning
Apr 12, 2020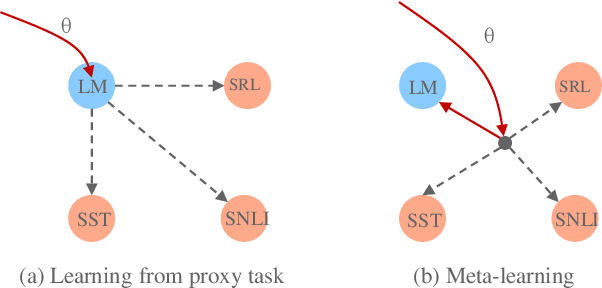
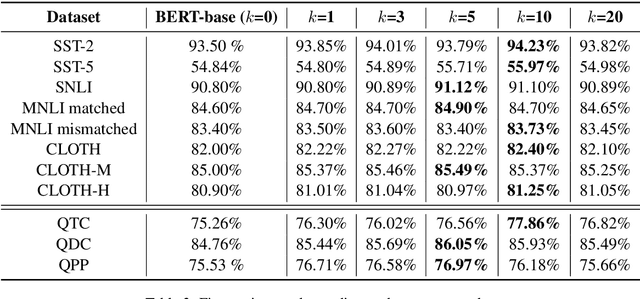
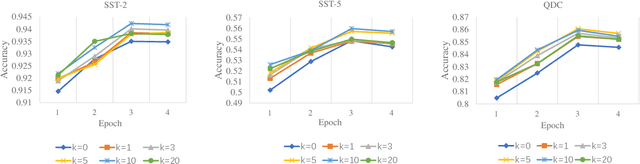
Pre-training text representations has recently been shown to significantly improve the state-of-the-art in many natural language processing tasks. The central goal of pre-training is to learn text representations that are useful for subsequent tasks. However, existing approaches are optimized by minimizing a proxy objective, such as the negative log likelihood of language modeling. In this work, we introduce a learning algorithm which directly optimizes model's ability to learn text representations for effective learning of downstream tasks. We show that there is an intrinsic connection between multi-task pre-training and model-agnostic meta-learning with a sequence of meta-train steps. The standard multi-task learning objective adopted in BERT is a special case of our learning algorithm where the depth of meta-train is zero. We study the problem in two settings: unsupervised pre-training and supervised pre-training with different pre-training objects to verify the generality of our approach.Experimental results show that our algorithm brings improvements and learns better initializations for a variety of downstream tasks.
Improving Readability for Automatic Speech Recognition Transcription
Apr 09, 2020
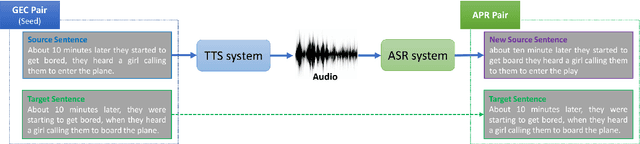
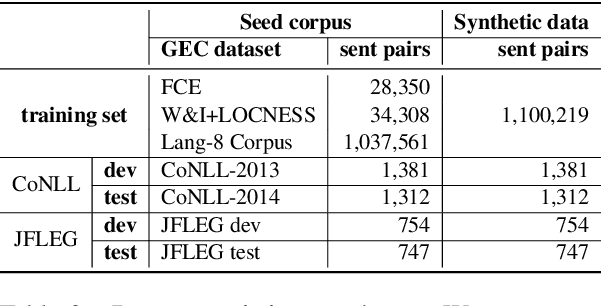
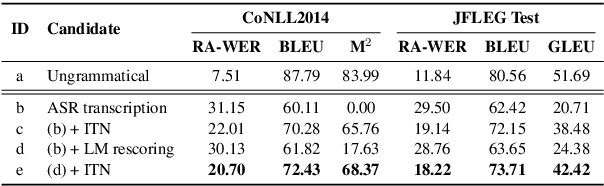
Modern Automatic Speech Recognition (ASR) systems can achieve high performance in terms of recognition accuracy. However, a perfectly accurate transcript still can be challenging to read due to grammatical errors, disfluency, and other errata common in spoken communication. Many downstream tasks and human readers rely on the output of the ASR system; therefore, errors introduced by the speaker and ASR system alike will be propagated to the next task in the pipeline. In this work, we propose a novel NLP task called ASR post-processing for readability (APR) that aims to transform the noisy ASR output into a readable text for humans and downstream tasks while maintaining the semantic meaning of the speaker. In addition, we describe a method to address the lack of task-specific data by synthesizing examples for the APR task using the datasets collected for Grammatical Error Correction (GEC) followed by text-to-speech (TTS) and ASR. Furthermore, we propose metrics borrowed from similar tasks to evaluate performance on the APR task. We compare fine-tuned models based on several open-sourced and adapted pre-trained models with the traditional pipeline method. Our results suggest that finetuned models improve the performance on the APR task significantly, hinting at the potential benefits of using APR systems. We hope that the read, understand, and rewrite approach of our work can serve as a basis that many NLP tasks and human readers can benefit from.
CodeBERT: A Pre-Trained Model for Programming and Natural Languages
Feb 19, 2020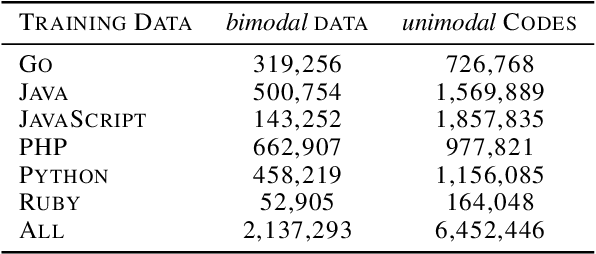

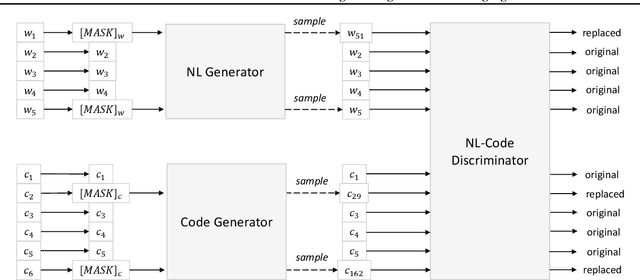
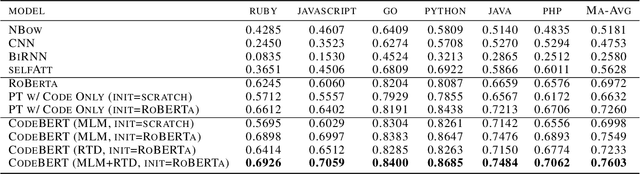
We present CodeBERT, a bimodal pre-trained model for programming language (PL) and nat-ural language (NL). CodeBERT learns general-purpose representations that support downstream NL-PL applications such as natural language codesearch, code documentation generation, etc. We develop CodeBERT with Transformer-based neural architecture, and train it with a hybrid objective function that incorporates the pre-training task of replaced token detection, which is to detect plausible alternatives sampled from generators. This enables us to utilize both bimodal data of NL-PL pairs and unimodal data, where the former provides input tokens for model training while the latter helps to learn better generators. We evaluate CodeBERT on two NL-PL applications by fine-tuning model parameters. Results show that CodeBERT achieves state-of-the-art performance on both natural language code search and code documentation generation tasks. Furthermore, to investigate what type of knowledge is learned in CodeBERT, we construct a dataset for NL-PL probing, and evaluate in a zero-shot setting where parameters of pre-trained models are fixed. Results show that CodeBERT performs better than previous pre-trained models on NL-PL probing.
Model Compression with Two-stage Multi-teacher Knowledge Distillation for Web Question Answering System
Oct 18, 2019
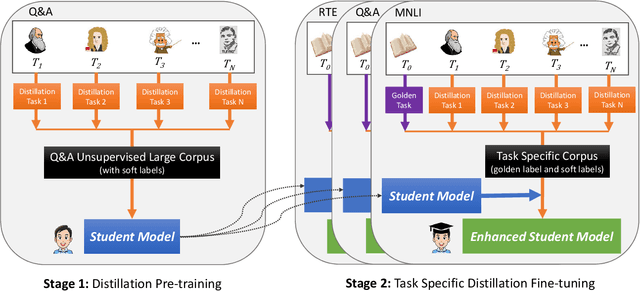

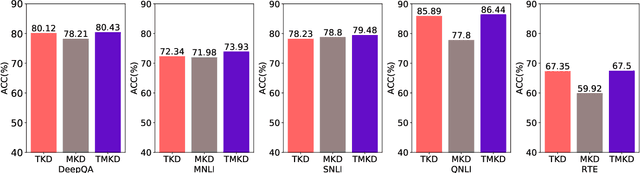
Deep pre-training and fine-tuning models (such as BERT and OpenAI GPT) have demonstrated excellent results in question answering areas. However, due to the sheer amount of model parameters, the inference speed of these models is very slow. How to apply these complex models to real business scenarios becomes a challenging but practical problem. Previous model compression methods usually suffer from information loss during the model compression procedure, leading to inferior models compared with the original one. To tackle this challenge, we propose a Two-stage Multi-teacher Knowledge Distillation (TMKD for short) method for web Question Answering system. We first develop a general Q\&A distillation task for student model pre-training, and further fine-tune this pre-trained student model with multi-teacher knowledge distillation on downstream tasks (like Web Q\&A task, MNLI, SNLI, RTE tasks from GLUE), which effectively reduces the overfitting bias in individual teacher models, and transfers more general knowledge to the student model. The experiment results show that our method can significantly outperform the baseline methods and even achieve comparable results with the original teacher models, along with substantial speedup of model inference.
Graph-Based Reasoning over Heterogeneous External Knowledge for Commonsense Question Answering
Sep 09, 2019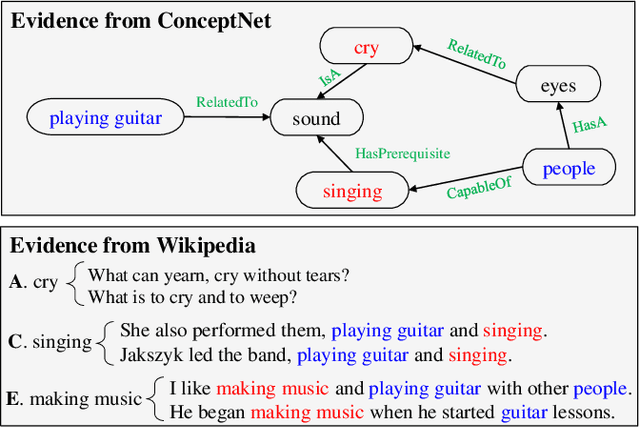
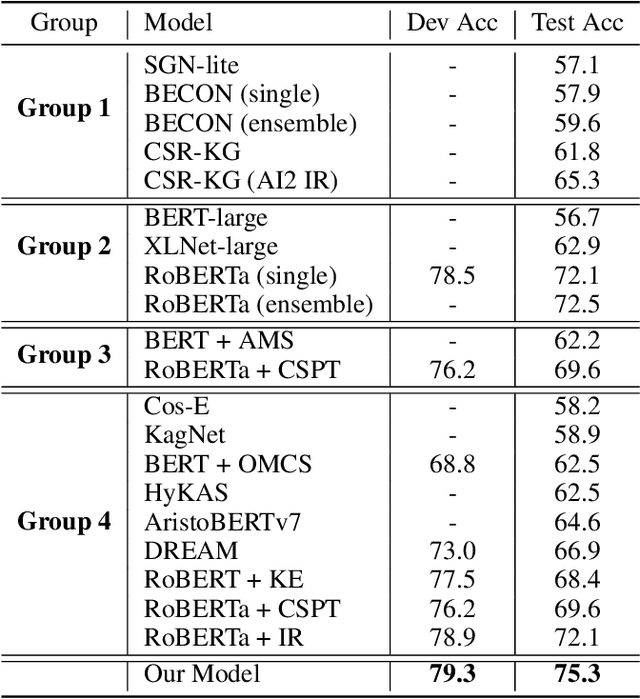
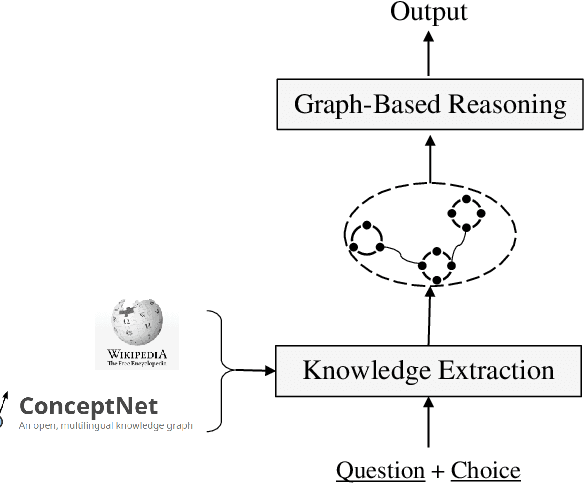

Commonsense question answering aims to answer questions which require background knowledge that is not explicitly expressed in the question. The key challenge is how to obtain evidence from external knowledge and make predictions based on the evidence. Recent works either learn to generate evidence from human-annotated evidence which is expensive to collect, or extract evidence from either structured or unstructured knowledge bases which fails to take advantages of both sources. In this work, we propose to automatically extract evidence from heterogeneous knowledge sources, and answer questions based on the extracted evidence. Specifically, we extract evidence from both structured knowledge base (i.e. ConceptNet) and Wikipedia plain texts. We construct graphs for both sources to obtain the relational structures of evidence. Based on these graphs, we propose a graph-based approach consisting of a graph-based contextual word representation learning module and a graph-based inference module. The first module utilizes graph structural information to re-define the distance between words for learning better contextual word representations. The second module adopts graph convolutional network to encode neighbor information into the representations of nodes, and aggregates evidence with graph attention mechanism for predicting the final answer. Experimental results on CommonsenseQA dataset illustrate that our graph-based approach over both knowledge sources brings improvement over strong baselines. Our approach achieves the state-of-the-art accuracy (75.3%) on the CommonsenseQA leaderboard.