 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-Based Method for High-Speed 3D Deformation Measurement under Extreme Illumination Conditions
Mar 30, 2026Background: Large engineering structures, such as space launch towers and suspension bridges, are subjected to extreme forces that cause high-speed 3D deformation and compromise safety. These structures typically operate under extreme illumination conditions. Traditional cameras often struggle to handle strong light intensity, leading to overexposure due to their limited dynamic range. Objective: Event cameras have emerged as a compelling alternative to traditional cameras in high dynamic range and low-latency applications. This paper presents an integrated method, from calibration to measurement, using a multi-event camera array for high-speed 3D deformation monitoring of structures in extreme illumination conditions. Methods: Firstly, the proposed method combines the characteristics of the asynchronous event stream and temporal correlation analysis to extract the corresponding marker center point. Subsequently, the method achieves rapid calibration by solving the Kruppa equations in conjunction with a parameter optimization framework. Finally, by employing a unified coordinate transformation and linear intersection, the method enables the measurement of 3D deformation of the target structure. Results: Experiments confirmed that the relative measurement error is below 0.08%. Field experiments under extreme illumination conditions, including self-calibration of a multi-event camera array and 3D deformation measurement, verified the performance of the proposed method. Conclusions: This paper addressed the critical limitation of traditional cameras in measuring high-speed 3D deformations under extreme illumination conditions. The experimental results demonstrate that, compared to other methods, the proposed method can accurately measure 3D deformations of structures under harsh lighting conditions, and the relative error of the measured deformation is less than 0.1%.
High Dynamic Range Imaging Based on an Asymmetric Event-SVE Camera System
Feb 28, 2026High dynamic range (HDR) imaging under extreme illumination remains challenging for conventional cameras due to overexposure. Event cameras provide microsecond temporal resolution and high dynamic range, while spatially varying exposure (SVE) sensors offer single-shot radiometric diversity.We present a hardware--algorithm co-designed HDR imaging system that tightly integrates an SVE micro-attenuation camera with an event sensor in an asymmetric dual-modality configuration. To handle non-coaxial geometry and heterogeneous optics, we develop a two-stage cross-modal alignment framework that combines feature-guided coarse homography estimation with a multi-scale refinement module based on spatial pooling and frequency-domain filtering. On top of aligned representations, we develop a cross-modal HDR reconstruction network with convolutional fusion, mutual-information regularization, and a learnable fusion loss that adaptively balances intensity cues and event-derived structural constraints. Comprehensive experiments on both synthetic benchmarks and real captures demonstrate that the proposed system consistently improves highlight recovery, edge fidelity, and robustness compared with frame-only or event-only HDR pipelines. The results indicate that jointly optimizing optical design, cross-modal alignment, and computational fusion provides an effective foundation for reliable HDR perception in highly dynamic and radiometrically challenging environments.
Enhancing Answer Boundary Detection for Multilingual Machine Reading Comprehension
May 08, 2020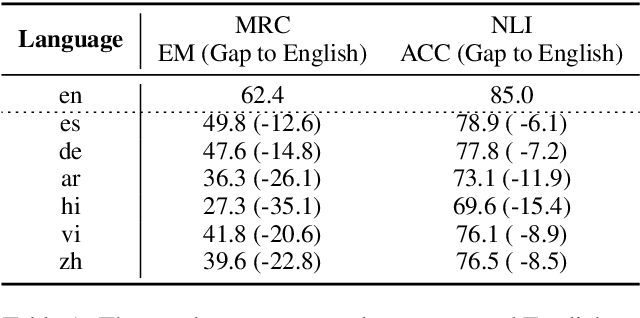
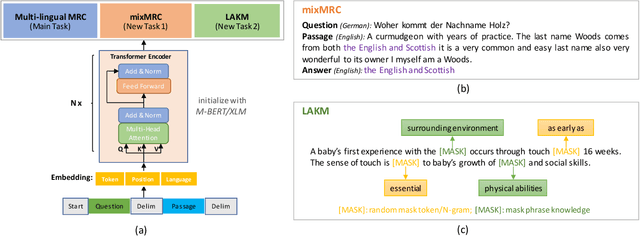
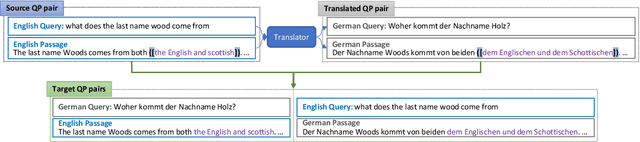
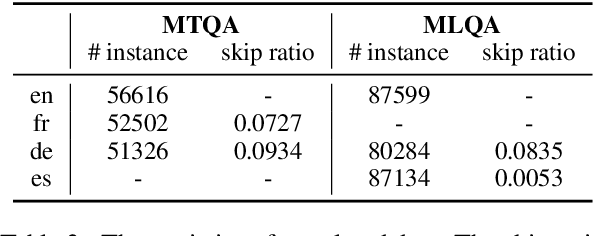
Multilingual pre-trained models could leverage the training data from a rich source language (such as English) to improve performance on low resource languages. However, the transfer quality for multilingual Machine Reading Comprehension (MRC) is significantly worse than sentence classification tasks mainly due to the requirement of MRC to detect the word level answer boundary. In this paper, we propose two auxiliary tasks in the fine-tuning stage to create additional phrase boundary supervision: (1) A mixed MRC task, which translates the question or passage to other languages and builds cross-lingual question-passage pairs; (2) A language-agnostic knowledge masking task by leveraging knowledge phrases mined from web. Besides, extensive experiments on two cross-lingual MRC datasets show the effectiveness of our proposed approach.