 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaper Summary Attack: Jailbreaking LLMs through LLM Safety Papers
Jul 17, 2025



The safety of large language models (LLMs) has garnered significant research attention. In this paper, we argue that previous empirical studies demonstrate LLMs exhibit a propensity to trust information from authoritative sources, such as academic papers, implying new possible vulnerabilities. To verify this possibility, a preliminary analysis is designed to illustrate our two findings. Based on this insight, a novel jailbreaking method, Paper Summary Attack (\llmname{PSA}), is proposed. It systematically synthesizes content from either attack-focused or defense-focused LLM safety paper to construct an adversarial prompt template, while strategically infilling harmful query as adversarial payloads within predefined subsections. Extensive experiments show significant vulnerabilities not only in base LLMs, but also in state-of-the-art reasoning model like Deepseek-R1. PSA achieves a 97\% attack success rate (ASR) on well-aligned models like Claude3.5-Sonnet and an even higher 98\% ASR on Deepseek-R1. More intriguingly, our work has further revealed diametrically opposed vulnerability bias across different base models, and even between different versions of the same model, when exposed to either attack-focused or defense-focused papers. This phenomenon potentially indicates future research clues for both adversarial methodologies and safety alignment.Code is available at https://github.com/233liang/Paper-Summary-Attack
Enhancing Cross-Prompt Transferability in Vision-Language Models through Contextual Injection of Target Tokens
Jun 19, 2024



Vision-language models (VLMs) seamlessly integrate visual and textual data to perform tasks such as image classification, caption generation, and visual question answering. However, adversarial images often struggle to deceive all prompts effectively in the context of cross-prompt migration attacks, as the probability distribution of the tokens in these images tends to favor the semantics of the original image rather than the target tokens. To address this challenge, we propose a Contextual-Injection Attack (CIA) that employs gradient-based perturbation to inject target tokens into both visual and textual contexts, thereby improving the probability distribution of the target tokens. By shifting the contextual semantics towards the target tokens instead of the original image semantics, CIA enhances the cross-prompt transferability of adversarial images.Extensive experiments on the BLIP2, InstructBLIP, and LLaVA models show that CIA outperforms existing methods in cross-prompt transferability, demonstrating its potential for more effective adversarial strategies in VLMs.
Semantic-Enhanced Relational Metric Learning for Recommender Systems
Jun 07, 2024



Recently, relational metric learning methods have been received great attention in recommendation community, which is inspired by the translation mechanism in knowledge graph. Different from the knowledge graph where the entity-to-entity relations are given in advance, historical interactions lack explicit relations between users and items in recommender systems. Currently, many researchers have succeeded in constructing the implicit relations to remit this issue. However, in previous work, the learning process of the induction function only depends on a single source of data (i.e., user-item interaction) in a supervised manner, resulting in the co-occurrence relation that is free of any semantic information. In this paper, to tackle the above problem in recommender systems, we propose a joint Semantic-Enhanced Relational Metric Learning (SERML) framework that incorporates the semantic information. Specifically, the semantic signal is first extracted from the target reviews containing abundant item features and personalized user preferences. A novel regression model is then designed via leveraging the extracted semantic signal to improve the discriminative ability of original relation-based training process. On four widely-used public datasets, experimental results demonstrate that SERML produces a competitive performance compared with several state-of-the-art methods in recommender systems.
Hateful Memes Detection via Complementary Visual and Linguistic Networks
Dec 09, 2020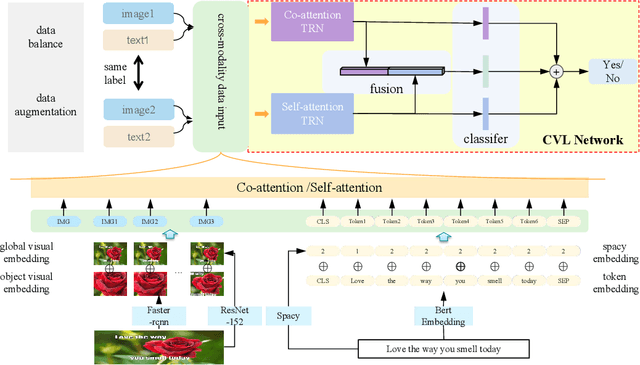
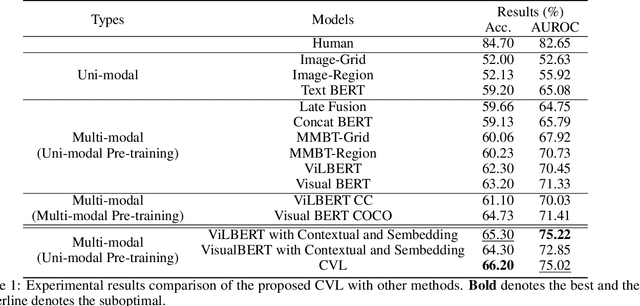
Hateful memes are widespread in social media and convey negative information. The main challenge of hateful memes detection is that the expressive meaning can not be well recognized by a single modality. In order to further integrate modal information, we investigate a candidate solution based on complementary visual and linguistic network in Hateful Memes Challenge 2020. In this way, more comprehensive information of the multi-modality could be explored in detail. Both contextual-level and sensitive object-level information are considered in visual and linguistic embedding to formulate the complex multi-modal scenarios. Specifically, a pre-trained classifier and object detector are utilized to obtain the contextual features and region-of-interests (RoIs) from the input, followed by the position representation fusion for visual embedding. While linguistic embedding is composed of three components, i.e., the sentence words embedding, position embedding and the corresponding Spacy embedding (Sembedding), which is a symbol represented by vocabulary extracted by Spacy. Both visual and linguistic embedding are fed into the designed Complementary Visual and Linguistic (CVL) networks to produce the prediction for hateful memes. Experimental results on Hateful Memes Challenge Dataset demonstrate that CVL provides a decent performance, and produces 78:48% and 72:95% on the criteria of AUROC and Accuracy. Code is available at https://github.com/webYFDT/hateful.
AutoSUM: Automating Feature Extraction and Multi-user Preference Simulation for Entity Summarization
May 25, 2020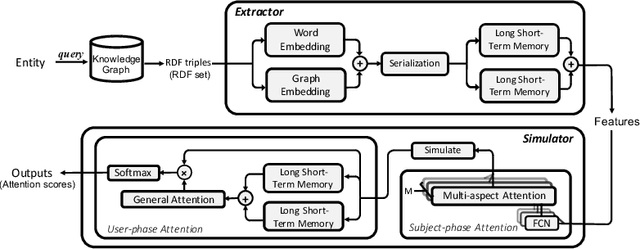
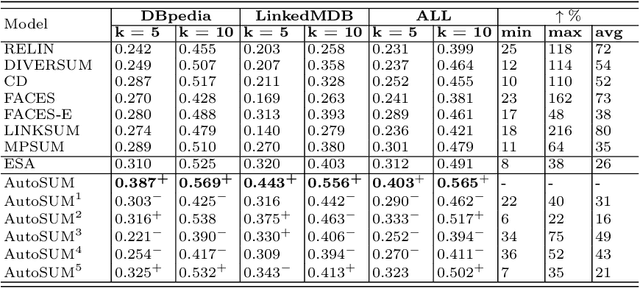
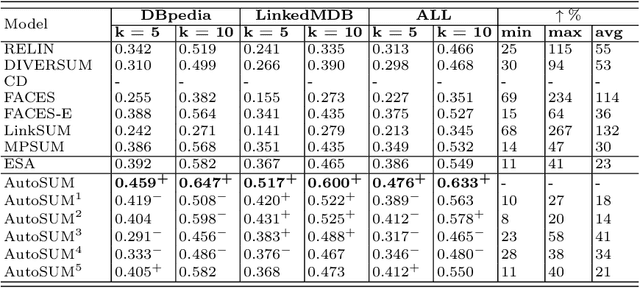
Withthegrowthofknowledgegraphs, entity descriptions are becoming extremely lengthy. Entity summarization task, aiming to generate diverse, comprehensive, and representative summaries for entities, has received increasing interest recently. In most previous methods, features are usually extracted by the handcrafted templates. Then the feature selection and multi-user preference simulation take place, depending too much on human expertise. In this paper, a novel integration method called AutoSUM is proposed for automatic feature extraction and multi-user preference simulation to overcome the drawbacks of previous methods. There are two modules in AutoSUM: extractor and simulator. The extractor module operates automatic feature extraction based on a BiLSTM with a combined input representation including word embeddings and graph embeddings. Meanwhile, the simulator module automates multi-user preference simulation based on a well-designed two-phase attention mechanism (i.e., entity-phase attention and user-phase attention). Experimental results demonstrate that AutoSUM produces state-of-the-art performance on two widely used datasets (i.e., DBpedia and LinkedMDB) in both F-measure and MAP.
Pre-training Text Representations as Meta Learning
Apr 12, 2020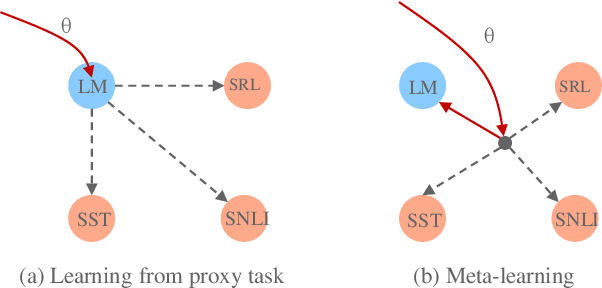
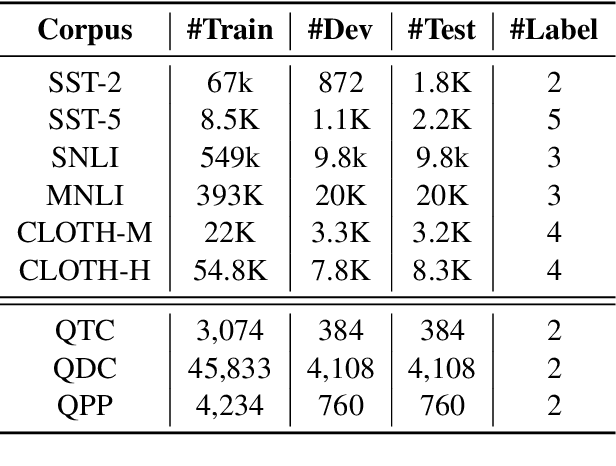
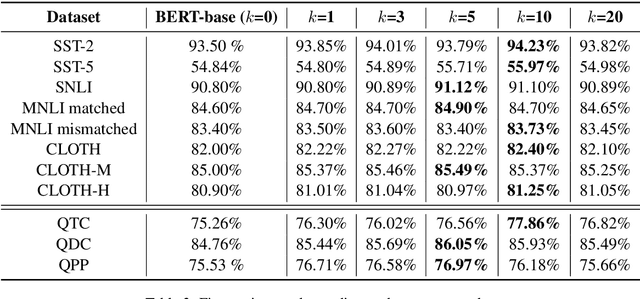
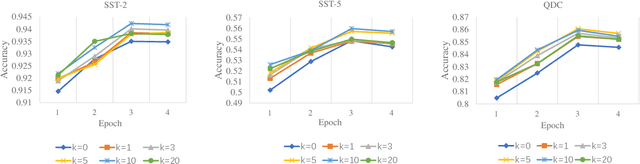
Pre-training text representations has recently been shown to significantly improve the state-of-the-art in many natural language processing tasks. The central goal of pre-training is to learn text representations that are useful for subsequent tasks. However, existing approaches are optimized by minimizing a proxy objective, such as the negative log likelihood of language modeling. In this work, we introduce a learning algorithm which directly optimizes model's ability to learn text representations for effective learning of downstream tasks. We show that there is an intrinsic connection between multi-task pre-training and model-agnostic meta-learning with a sequence of meta-train steps. The standard multi-task learning objective adopted in BERT is a special case of our learning algorithm where the depth of meta-train is zero. We study the problem in two settings: unsupervised pre-training and supervised pre-training with different pre-training objects to verify the generality of our approach.Experimental results show that our algorithm brings improvements and learns better initializations for a variety of downstream tasks.
Pseudo-positive regularization for deep person re-identification
Nov 17, 2017
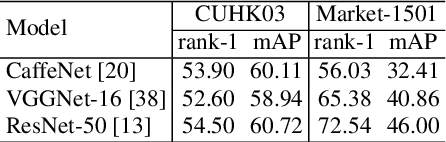

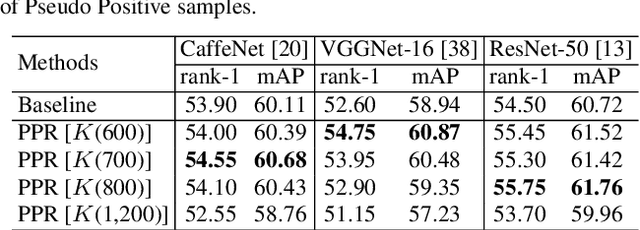
An intrinsic challenge of person re-identification (re-ID) is the annotation difficulty. This typically means 1) few training samples per identity, and 2) thus the lack of diversity among the training samples. Consequently, we face high risk of over-fitting when training the convolutional neural network (CNN), a state-of-the-art method in person re-ID. To reduce the risk of over-fitting, this paper proposes a Pseudo Positive Regularization (PPR) method to enrich the diversity of the training data. Specifically, unlabeled data from an independent pedestrian database is retrieved using the target training data as query. A small proportion of these retrieved samples are randomly selected as the Pseudo Positive samples and added to the target training set for the supervised CNN training. The addition of Pseudo Positive samples is therefore a data augmentation method to reduce the risk of over-fitting during CNN training. We implement our idea in the identification CNN models (i.e., CaffeNet, VGGNet-16 and ResNet-50). On CUHK03 and Market-1501 datasets, experimental results demonstrate that the proposed method consistently improves the baseline and yields competitive performance to the state-of-the-art person re-ID methods.
Part-based Deep Hashing for Large-scale Person Re-identification
May 05, 2017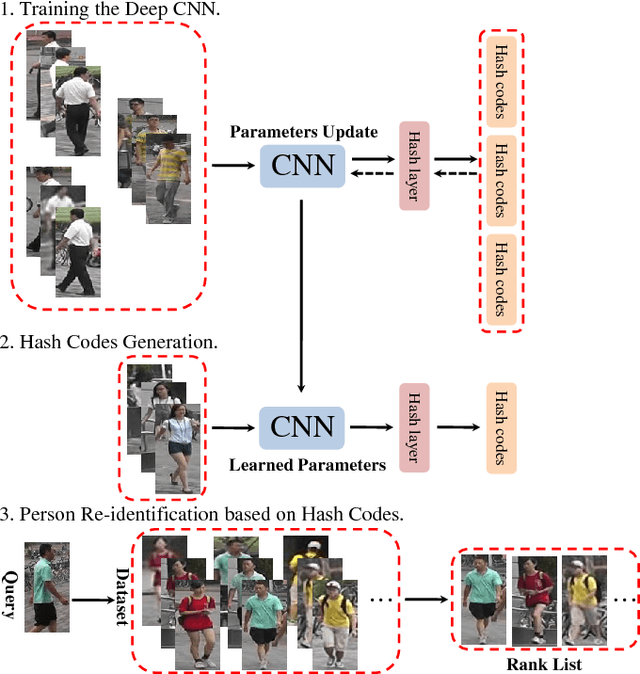
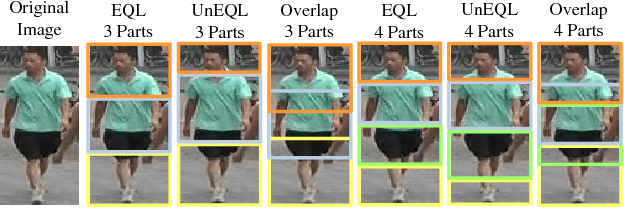
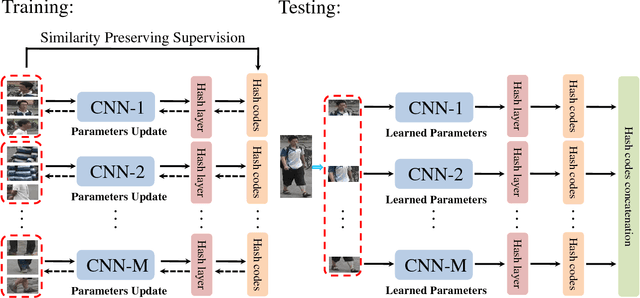
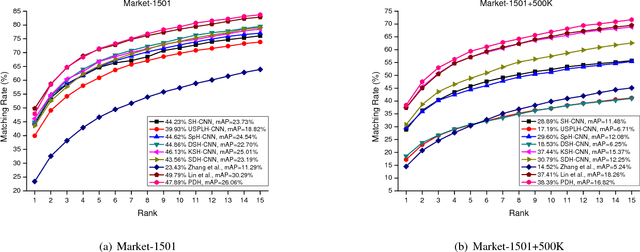
Large-scale is a trend in person re-identification (re-id). It is important that real-time search be performed in a large gallery. While previous methods mostly focus on discriminative learning, this paper makes the attempt in integrating deep learning and hashing into one framework to evaluate the efficiency and accuracy for large-scale person re-id. We integrate spatial information for discriminative visual representation by partitioning the pedestrian image into horizontal parts. Specifically, Part-based Deep Hashing (PDH) is proposed, in which batches of triplet samples are employed as the input of the deep hashing architecture. Each triplet sample contains two pedestrian images (or parts) with the same identity and one pedestrian image (or part) of the different identity. A triplet loss function is employed with a constraint that the Hamming distance of pedestrian images (or parts) with the same identity is smaller than ones with the different identity. In the experiment, we show that the proposed Part-based Deep Hashing method yields very competitive re-id accuracy on the large-scale Market-1501 and Market-1501+500K datasets.