 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuidedMix-Net: Learning to Improve Pseudo Masks Using Labeled Images as Reference
Jun 30, 2021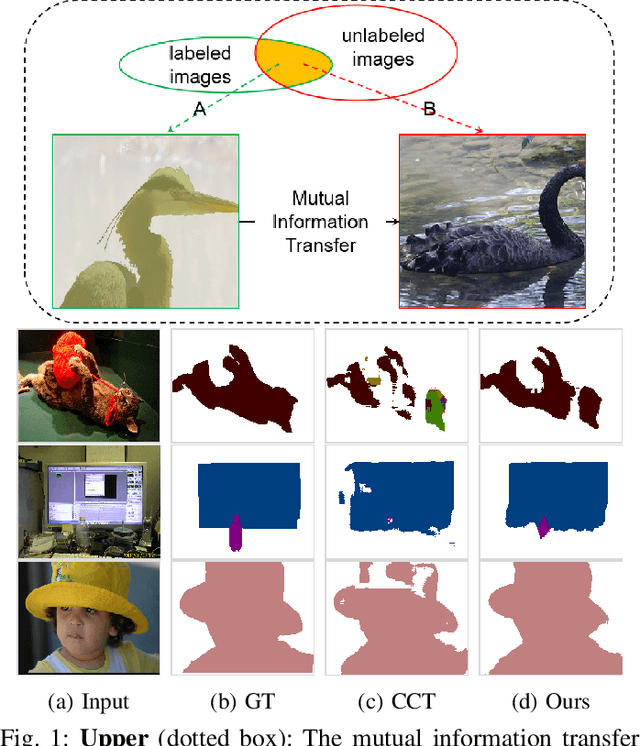
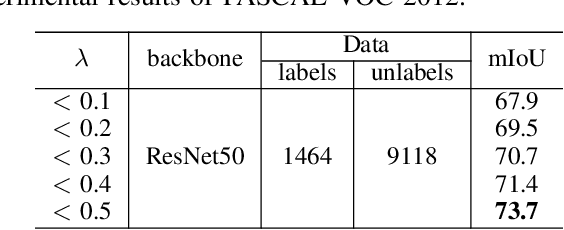
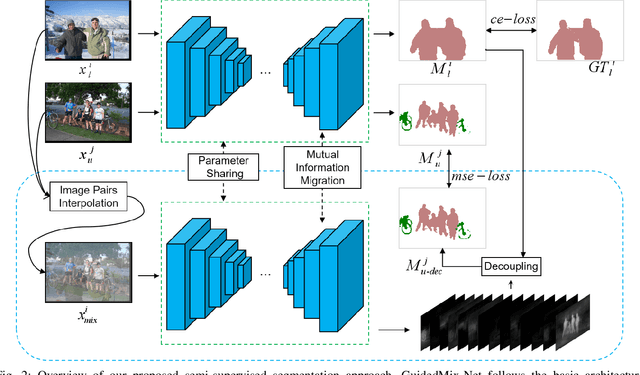
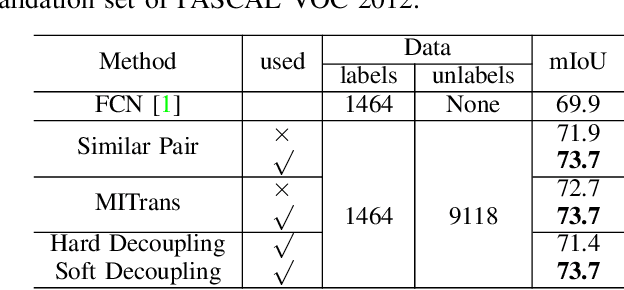
Semi-supervised learning is a challenging problem which aims to construct a model by learning from a limited number of labeled examples. Numerous methods have been proposed to tackle this problem, with most focusing on utilizing the predictions of unlabeled instances consistency alone to regularize networks. However, treating labeled and unlabeled data separately often leads to the discarding of mass prior knowledge learned from the labeled examples, and failure to mine the feature interaction between the labeled and unlabeled image pairs. In this paper, we propose a novel method for semi-supervised semantic segmentation named GuidedMix-Net, by leveraging labeled information to guide the learning of unlabeled instances. Specifically, we first introduce a feature alignment objective between labeled and unlabeled data to capture potentially similar image pairs and then generate mixed inputs from them. The proposed mutual information transfer (MITrans), based on the cluster assumption, is shown to be a powerful knowledge module for further progressive refining features of unlabeled data in the mixed data space. To take advantage of the labeled examples and guide unlabeled data learning, we further propose a mask generation module to generate high-quality pseudo masks for the unlabeled data. Along with supervised learning for labeled data, the prediction of unlabeled data is jointly learned with the generated pseudo masks from the mixed data. Extensive experiments on PASCAL VOC 2012, PASCAL-Context and Cityscapes demonstrate the effectiveness of our GuidedMix-Net, which achieves competitive segmentation accuracy and significantly improves the mIoU by +7$\%$ compared to previous state-of-the-art approaches.
Accelerated Multi-Modal MR Imaging with Transformers
Jun 29, 2021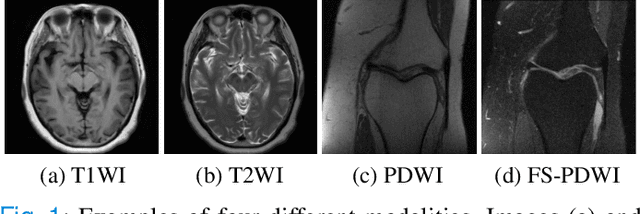
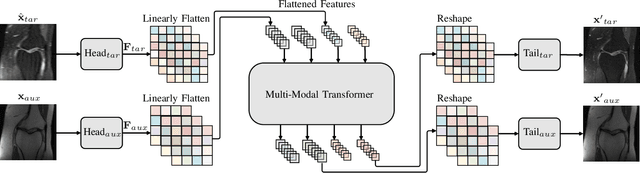
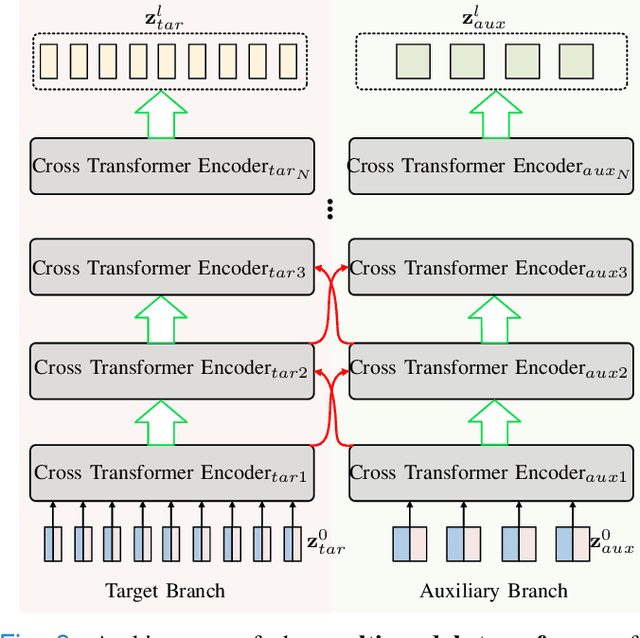
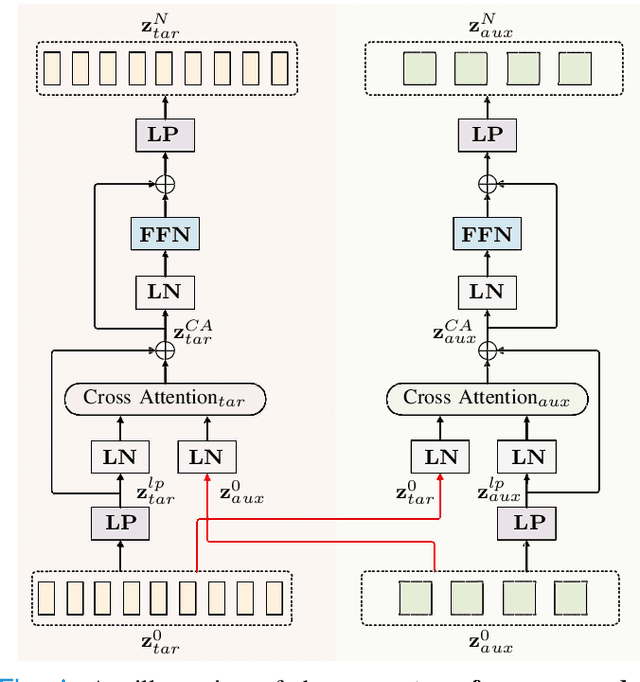
Accelerating multi-modal magnetic resonance (MR) imaging is a new and effective solution for fast MR imaging, providing superior performance in restoring the target modality from its undersampled counterpart with guidance from an auxiliary modality. However, existing works simply introduce the auxiliary modality as prior information, lacking in-depth investigations on the potential mechanisms for fusing two modalities. Further, they usually rely on the convolutional neural networks (CNNs), which focus on local information and prevent them from fully capturing the long-distance dependencies of global knowledge. To this end, we propose a multi-modal transformer (MTrans), which is capable of transferring multi-scale features from the target modality to the auxiliary modality, for accelerated MR imaging. By restructuring the transformer architecture, our MTrans gains a powerful ability to capture deep multi-modal information. More specifically, the target modality and the auxiliary modality are first split into two branches and then fused using a multi-modal transformer module. This module is based on an improved multi-head attention mechanism, named the cross attention module, which absorbs features from the auxiliary modality that contribute to the target modality. Our framework provides two appealing benefits: (i) MTrans is the first attempt at using improved transformers for multi-modal MR imaging, affording more global information compared with CNN-based methods. (ii) A new cross attention module is proposed to exploit the useful information in each branch at different scales. It affords both distinct structural information and subtle pixel-level information, which supplement the target modality effectively.
Sparse Needlets for Lighting Estimation with Spherical Transport Loss
Jun 24, 2021

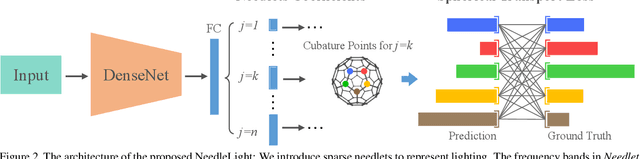
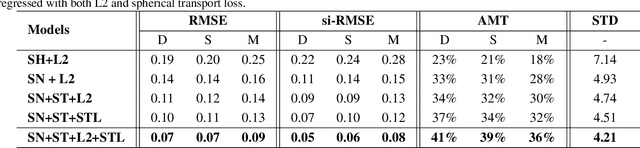
Accurate lighting estimation is challenging yet critical to many computer vision and computer graphics tasks such as high-dynamic-range (HDR) relighting. Existing approaches model lighting in either frequency domain or spatial domain which is insufficient to represent the complex lighting conditions in scenes and tends to produce inaccurate estimation. This paper presents NeedleLight, a new lighting estimation model that represents illumination with needlets and allows lighting estimation in both frequency domain and spatial domain jointly. An optimal thresholding function is designed to achieve sparse needlets which trims redundant lighting parameters and demonstrates superior localization properties for illumination representation. In addition, a novel spherical transport loss is designed based on optimal transport theory which guides to regress lighting representation parameters with consideration of the spatial information. Furthermore, we propose a new metric that is concise yet effective by directly evaluating the estimated illumination maps rather than rendered images. Extensive experiments show that NeedleLight achieves superior lighting estimation consistently across multiple evaluation metrics as compared with state-of-the-art methods.
Federated Noisy Client Learning
Jun 24, 2021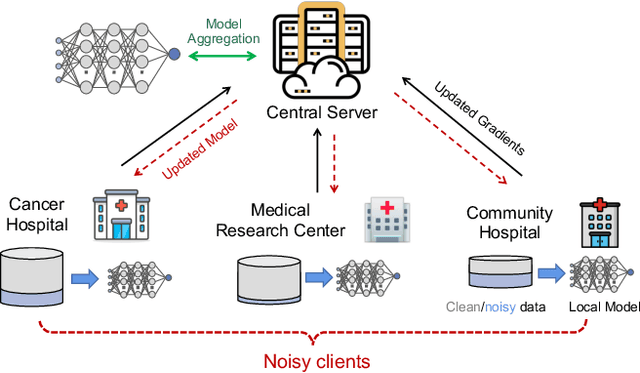
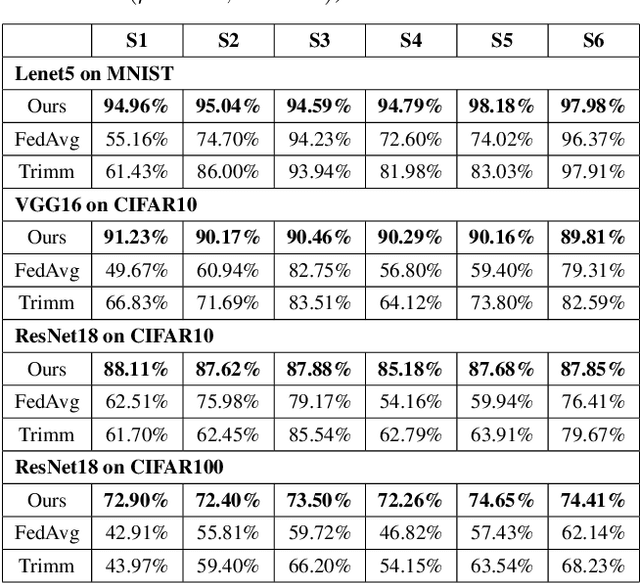
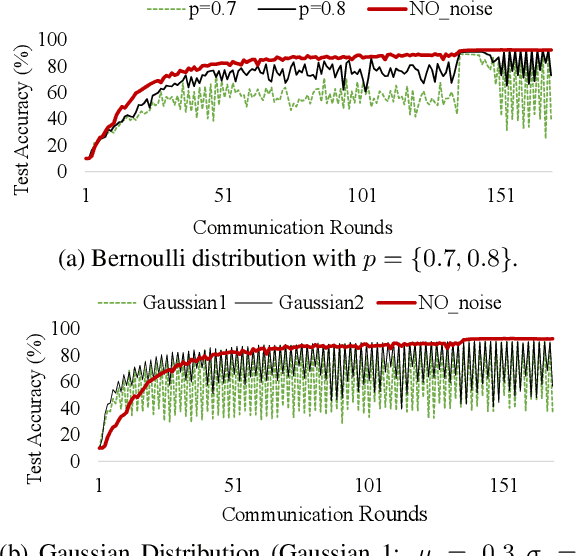
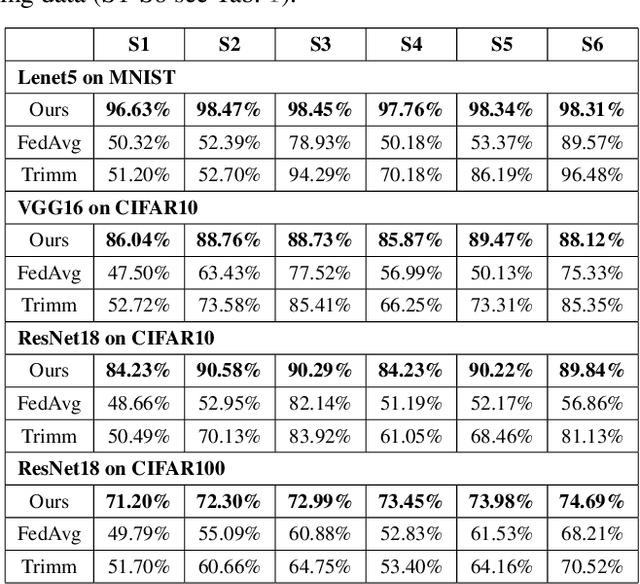
Federated learning (FL) collaboratively aggregates a shared global model depending on multiple local clients, while keeping the training data decentralized in order to preserve data privacy. However, standard FL methods ignore the noisy client issue, which may harm the overall performance of the aggregated model. In this paper, we first analyze the noisy client statement, and then model noisy clients with different noise distributions (e.g., Bernoulli and truncated Gaussian distributions). To learn with noisy clients, we propose a simple yet effective FL framework, named Federated Noisy Client Learning (Fed-NCL), which is a plug-and-play algorithm and contains two main components: a data quality measurement (DQM) to dynamically quantify the data quality of each participating client, and a noise robust aggregation (NRA) to adaptively aggregate the local models of each client by jointly considering the amount of local training data and the data quality of each client. Our Fed-NCL can be easily applied in any standard FL workflow to handle the noisy client issue. Experimental results on various datasets demonstrate that our algorithm boosts the performances of different state-of-the-art systems with noisy clients.
Exploring Visual Context for Weakly Supervised Person Search
Jun 19, 2021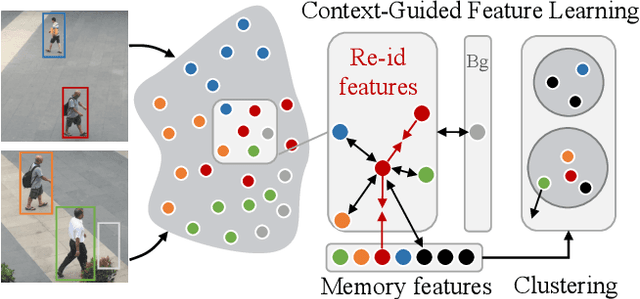
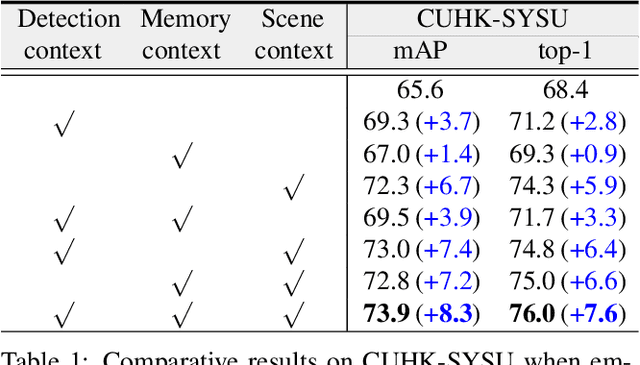
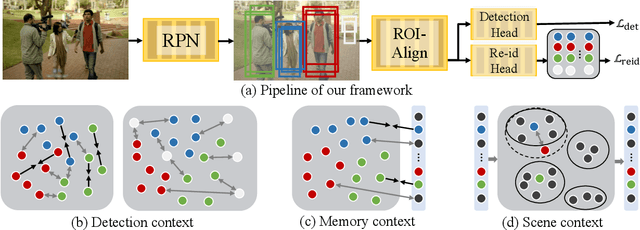

Person search has recently emerged as a challenging task that jointly addresses pedestrian detection and person re-identification. Existing approaches follow a fully supervised setting where both bounding box and identity annotations are available. However, annotating identities is labor-intensive, limiting the practicability and scalability of current frameworks. This paper inventively considers weakly supervised person search with only bounding box annotations. We proposed the first framework to address this novel task, namely Context-Guided Person Search (CGPS), by investigating three levels of context clues (i.e., detection, memory and scene) in unconstrained natural images. The first two are employed to promote local and global discriminative capabilities, while the latter enhances clustering accuracy. Despite its simple design, our CGPS boosts the baseline model by 8.3% in mAP on CUHK-SYSU. Surprisingly, it even achieves comparable performance to two-step person search models, while displaying higher efficiency. Our code is available at https://github.com/ljpadam/CGPS.
AFAN: Augmented Feature Alignment Network for Cross-Domain Object Detection
Jun 10, 2021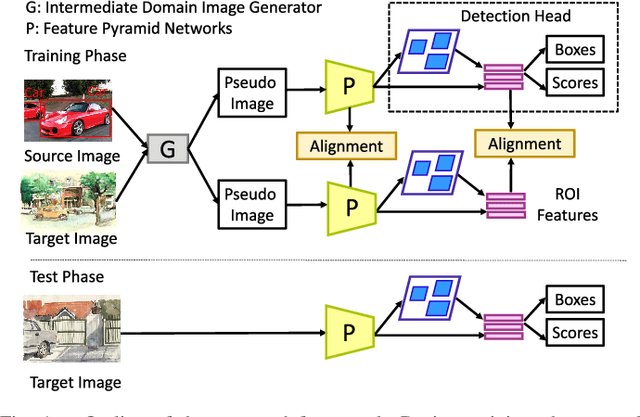
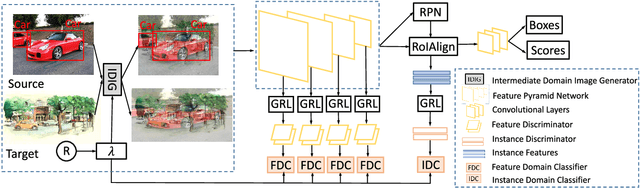
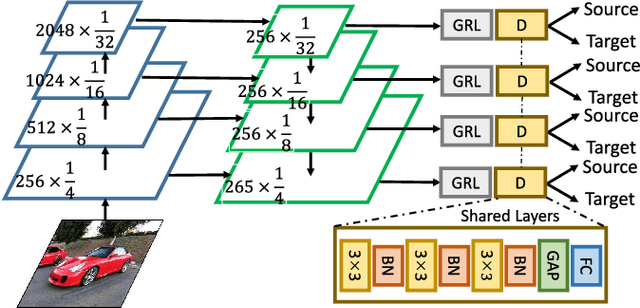
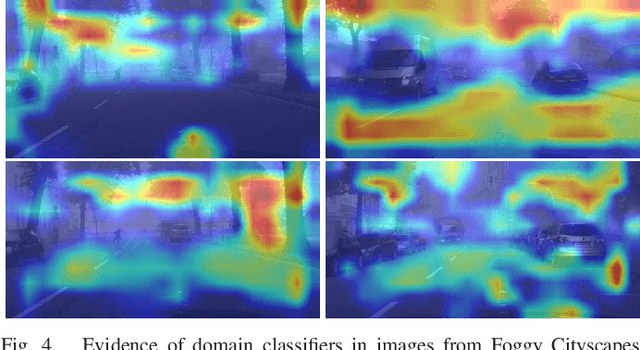
Unsupervised domain adaptation for object detection is a challenging problem with many real-world applications. Unfortunately, it has received much less attention than supervised object detection. Models that try to address this task tend to suffer from a shortage of annotated training samples. Moreover, existing methods of feature alignments are not sufficient to learn domain-invariant representations. To address these limitations, we propose a novel augmented feature alignment network (AFAN) which integrates intermediate domain image generation and domain-adversarial training into a unified framework. An intermediate domain image generator is proposed to enhance feature alignments by domain-adversarial training with automatically generated soft domain labels. The synthetic intermediate domain images progressively bridge the domain divergence and augment the annotated source domain training data. A feature pyramid alignment is designed and the corresponding feature discriminator is used to align multi-scale convolutional features of different semantic levels. Last but not least, we introduce a region feature alignment and an instance discriminator to learn domain-invariant features for object proposals. Our approach significantly outperforms the state-of-the-art methods on standard benchmarks for both similar and dissimilar domain adaptations. Further extensive experiments verify the effectiveness of each component and demonstrate that the proposed network can learn domain-invariant representations.
Category Contrast for Unsupervised Domain Adaptation in Visual Tasks
Jun 08, 2021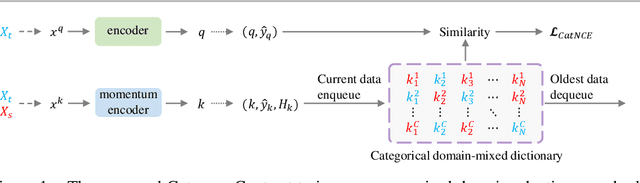
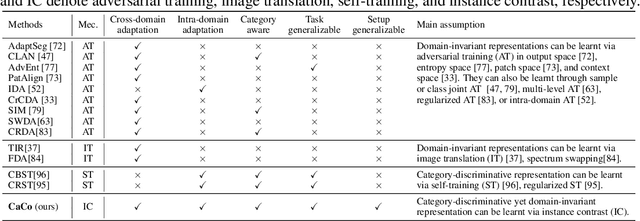
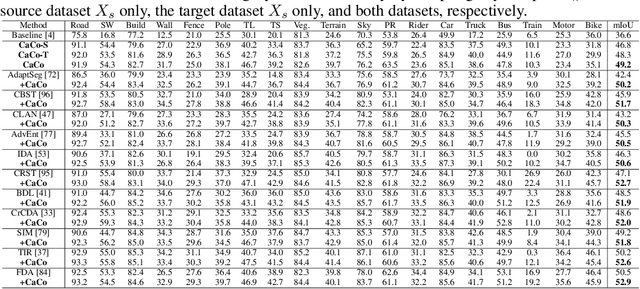
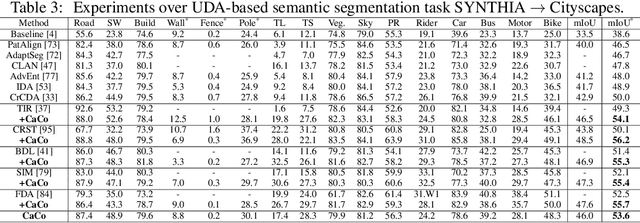
Instance contrast for unsupervised representation learning has achieved great success in recent years. In this work, we explore the idea of instance contrastive learning in unsupervised domain adaptation (UDA) and propose a novel Category Contrast technique (CaCo) that introduces semantic priors on top of instance discrimination for visual UDA tasks. By considering instance contrastive learning as a dictionary look-up operation, we construct a semantics-aware dictionary with samples from both source and target domains where each target sample is assigned a (pseudo) category label based on the category priors of source samples. This allows category contrastive learning (between target queries and the category-level dictionary) for category-discriminative yet domain-invariant feature representations: samples of the same category (from either source or target domain) are pulled closer while those of different categories are pushed apart simultaneously. Extensive UDA experiments in multiple visual tasks ($e.g.$, segmentation, classification and detection) show that the simple implementation of CaCo achieves superior performance as compared with the highly-optimized state-of-the-art methods. Analytically and empirically, the experiments also demonstrate that CaCo is complementary to existing UDA methods and generalizable to other learning setups such as semi-supervised learning, unsupervised model adaptation, etc.
You Never Cluster Alone
Jun 03, 2021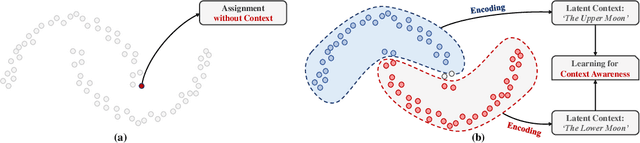
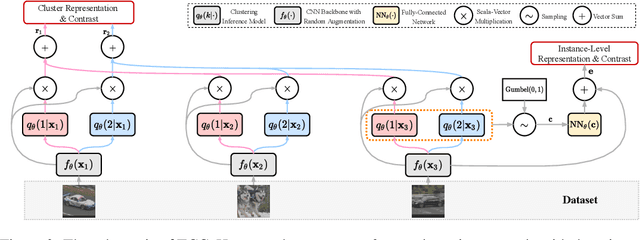
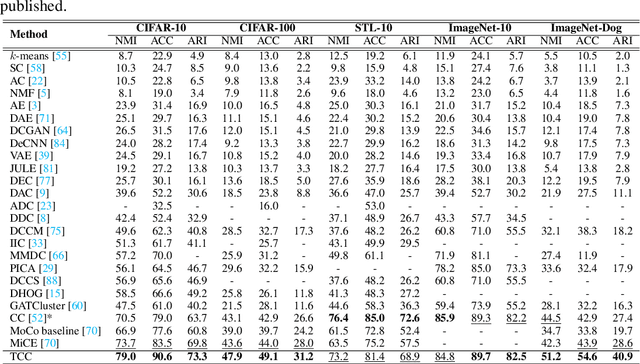
Recent advances in self-supervised learning with instance-level contrastive objectives facilitate unsupervised clustering. However, a standalone datum is not perceiving the context of the holistic cluster, and may undergo sub-optimal assignment. In this paper, we extend the mainstream contrastive learning paradigm to a cluster-level scheme, where all the data subjected to the same cluster contribute to a unified representation that encodes the context of each data group. Contrastive learning with this representation then rewards the assignment of each datum. To implement this vision, we propose twin-contrast clustering (TCC). We define a set of categorical variables as clustering assignment confidence, which links the instance-level learning track with the cluster-level one. On one hand, with the corresponding assignment variables being the weight, a weighted aggregation along the data points implements the set representation of a cluster. We further propose heuristic cluster augmentation equivalents to enable cluster-level contrastive learning. On the other hand, we derive the evidence lower-bound of the instance-level contrastive objective with the assignments. By reparametrizing the assignment variables, TCC is trained end-to-end, requiring no alternating steps. Extensive experiments show that TCC outperforms the state-of-the-art on challenging benchmarks.
When Liebig's Barrel Meets Facial Landmark Detection: A Practical Model
Jun 02, 2021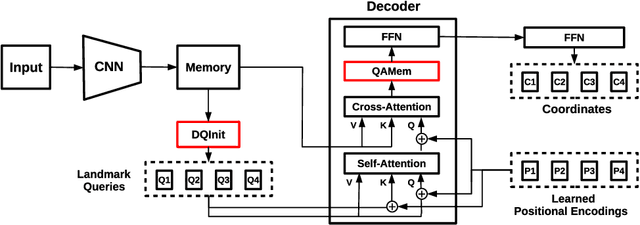
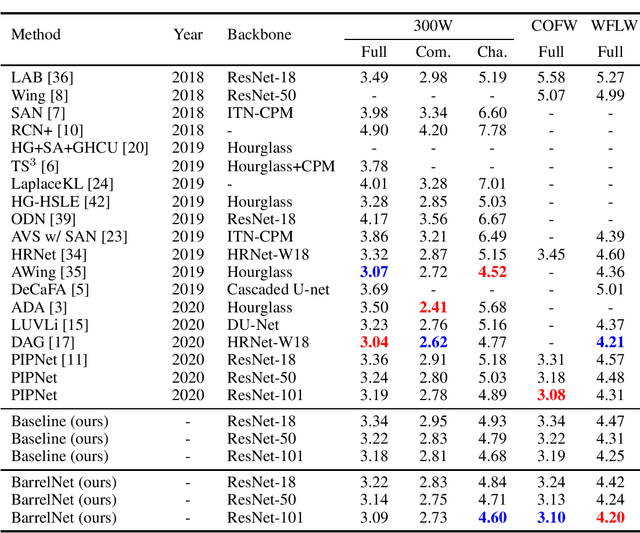
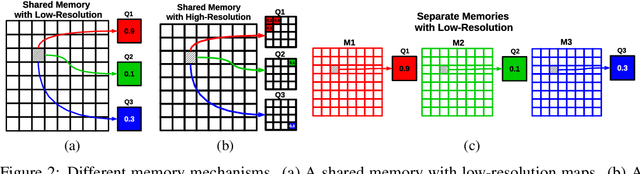
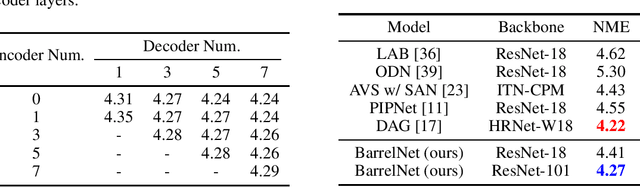
In recent years, significant progress has been made in the research of facial landmark detection. However, few prior works have thoroughly discussed about models for practical applications. Instead, they often focus on improving a couple of issues at a time while ignoring the others. To bridge this gap, we aim to explore a practical model that is accurate, robust, efficient, generalizable, and end-to-end trainable at the same time. To this end, we first propose a baseline model equipped with one transformer decoder as detection head. In order to achieve a better accuracy, we further propose two lightweight modules, namely dynamic query initialization (DQInit) and query-aware memory (QAMem). Specifically, DQInit dynamically initializes the queries of decoder from the inputs, enabling the model to achieve as good accuracy as the ones with multiple decoder layers. QAMem is designed to enhance the discriminative ability of queries on low-resolution feature maps by assigning separate memory values to each query rather than a shared one. With the help of QAMem, our model removes the dependence on high-resolution feature maps and is still able to obtain superior accuracy. Extensive experiments and analysis on three popular benchmarks show the effectiveness and practical advantages of the proposed model. Notably, our model achieves new state of the art on WFLW as well as competitive results on 300W and COFW, while still running at 50+ FPS.
Transformer-Based Deep Image Matching for Generalizable Person Re-identification
May 30, 2021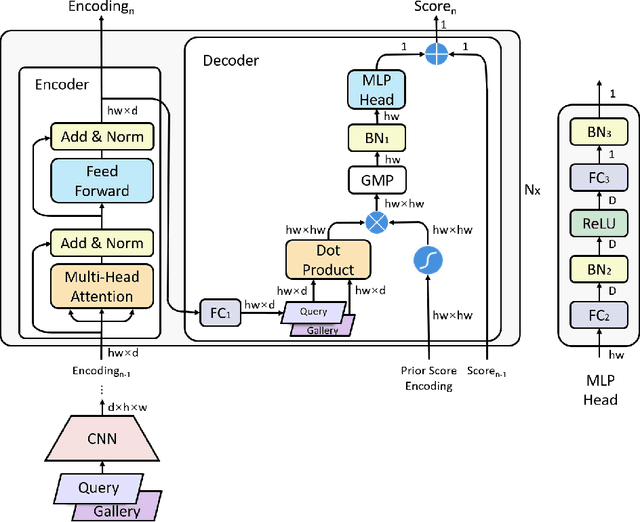
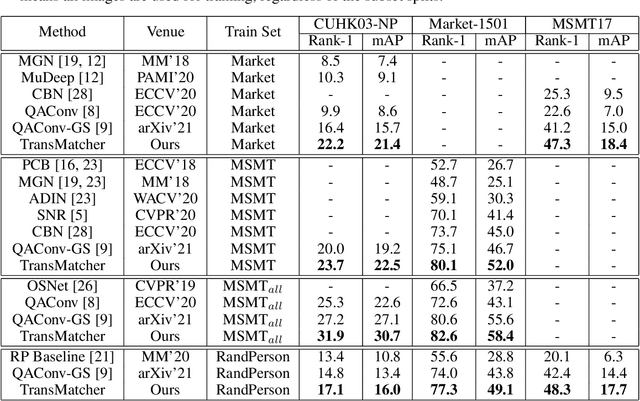
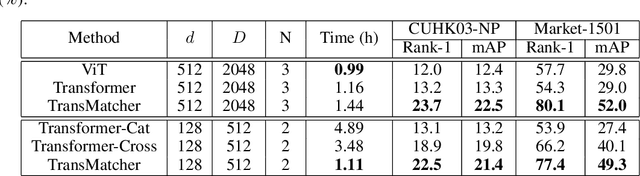
Transformers have recently gained increasing attention in computer vision. However, existing studies mostly use Transformers for feature representation learning, e.g. for image classification and dense predictions. In this work, we further investigate the possibility of applying Transformers for image matching and metric learning given pairs of images. We find that the Vision Transformer (ViT) and the vanilla Transformer with decoders are not adequate for image matching due to their lack of image-to-image attention. Thus, we further design two naive solutions, i.e. query-gallery concatenation in ViT, and query-gallery cross-attention in the vanilla Transformer. The latter improves the performance, but it is still limited. This implies that the attention mechanism in Transformers is primarily designed for global feature aggregation, which is not naturally suitable for image matching. Accordingly, we propose a new simplified decoder, which drops the full attention implementation with the softmax weighting, keeping only the query-key similarity computation. Additionally, global max pooling and a multilayer perceptron (MLP) head are applied to decode the matching result. This way, the simplified decoder is computationally more efficient, while at the same time more effective for image matching. The proposed method, called TransMatcher, achieves state-of-the-art performance in generalizable person re-identification, with up to 6.1% and 5.7% performance gains in Rank-1 and mAP, respectively, on several popular datasets. The source code of this study will be made publicly available.