 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualized Spatio-Temporal Contrastive Learning with Self-Supervision
Dec 09, 2021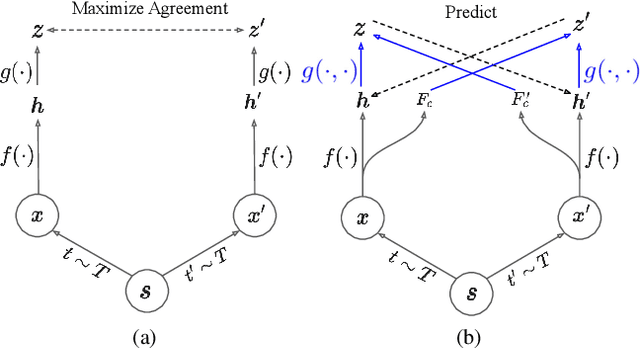
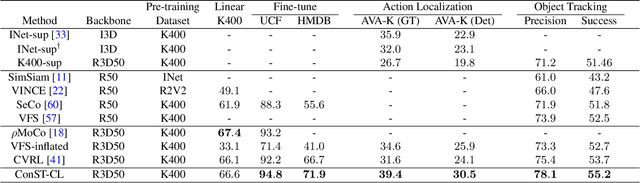
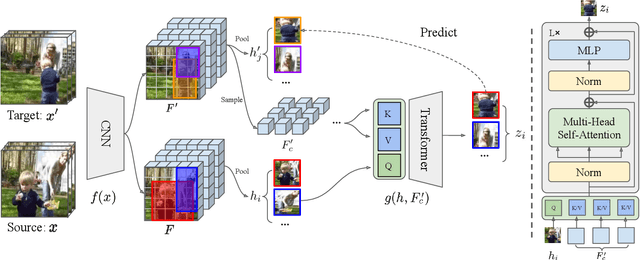
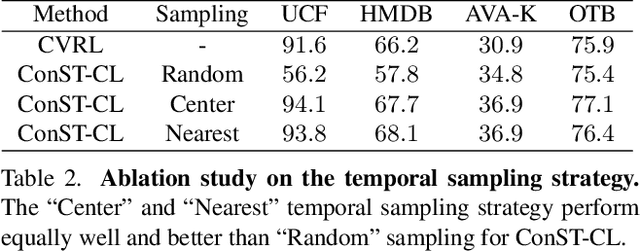
A modern self-supervised learning algorithm typically enforces persistency of the representations of an instance across views. While being very effective on learning holistic image and video representations, such an approach becomes sub-optimal for learning spatio-temporally fine-grained features in videos, where scenes and instances evolve through space and time. In this paper, we present the Contextualized Spatio-Temporal Contrastive Learning (ConST-CL) framework to effectively learn spatio-temporally fine-grained representations using self-supervision. We first design a region-based self-supervised pretext task which requires the model to learn to transform instance representations from one view to another guided by context features. Further, we introduce a simple network design that effectively reconciles the simultaneous learning process of both holistic and local representations. We evaluate our learned representations on a variety of downstream tasks and ConST-CL achieves state-of-the-art results on four datasets. For spatio-temporal action localization, ConST-CL achieves 39.4% mAP with ground-truth boxes and 30.5% mAP with detected boxes on the AVA-Kinetics validation set. For object tracking, ConST-CL achieves 78.1% precision and 55.2% success scores on OTB2015. Furthermore, ConST-CL achieves 94.8% and 71.9% top-1 fine-tuning accuracy on video action recognition datasets, UCF101 and HMDB51 respectively. We plan to release our code and models to the public.
Exploring Temporal Granularity in Self-Supervised Video Representation Learning
Dec 08, 2021



This work presents a self-supervised learning framework named TeG to explore Temporal Granularity in learning video representations. In TeG, we sample a long clip from a video and a short clip that lies inside the long clip. We then extract their dense temporal embeddings. The training objective consists of two parts: a fine-grained temporal learning objective to maximize the similarity between corresponding temporal embeddings in the short clip and the long clip, and a persistent temporal learning objective to pull together global embeddings of the two clips. Our study reveals the impact of temporal granularity with three major findings. 1) Different video tasks may require features of different temporal granularities. 2) Intriguingly, some tasks that are widely considered to require temporal awareness can actually be well addressed by temporally persistent features. 3) The flexibility of TeG gives rise to state-of-the-art results on 8 video benchmarks, outperforming supervised pre-training in most cases.
DeepLab2: A TensorFlow Library for Deep Labeling
Jun 17, 2021


DeepLab2 is a TensorFlow library for deep labeling, aiming to provide a state-of-the-art and easy-to-use TensorFlow codebase for general dense pixel prediction problems in computer vision. DeepLab2 includes all our recently developed DeepLab model variants with pretrained checkpoints as well as model training and evaluation code, allowing the community to reproduce and further improve upon the state-of-art systems. To showcase the effectiveness of DeepLab2, our Panoptic-DeepLab employing Axial-SWideRNet as network backbone achieves 68.0% PQ or 83.5% mIoU on Cityscaspes validation set, with only single-scale inference and ImageNet-1K pretrained checkpoints. We hope that publicly sharing our library could facilitate future research on dense pixel labeling tasks and envision new applications of this technology. Code is made publicly available at \url{https://github.com/google-research/deeplab2}.
MoViNets: Mobile Video Networks for Efficient Video Recognition
Apr 18, 2021



We present Mobile Video Networks (MoViNets), a family of computation and memory efficient video networks that can operate on streaming video for online inference. 3D convolutional neural networks (CNNs) are accurate at video recognition but require large computation and memory budgets and do not support online inference, making them difficult to work on mobile devices. We propose a three-step approach to improve computational efficiency while substantially reducing the peak memory usage of 3D CNNs. First, we design a video network search space and employ neural architecture search to generate efficient and diverse 3D CNN architectures. Second, we introduce the Stream Buffer technique that decouples memory from video clip duration, allowing 3D CNNs to embed arbitrary-length streaming video sequences for both training and inference with a small constant memory footprint. Third, we propose a simple ensembling technique to improve accuracy further without sacrificing efficiency. These three progressive techniques allow MoViNets to achieve state-of-the-art accuracy and efficiency on the Kinetics, Moments in Time, and Charades video action recognition datasets. For instance, MoViNet-A5-Stream achieves the same accuracy as X3D-XL on Kinetics 600 while requiring 80% fewer FLOPs and 65% less memory. Code will be made available at https://github.com/tensorflow/models/tree/master/official/vision.
Learning View-Disentangled Human Pose Representation by Contrastive Cross-View Mutual Information Maximization
Dec 02, 2020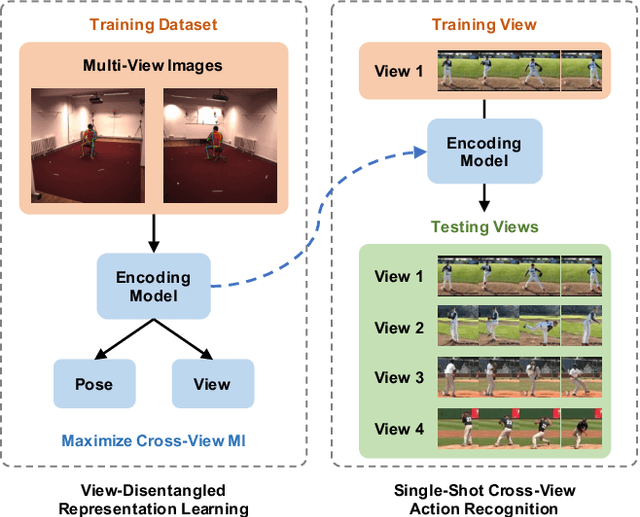
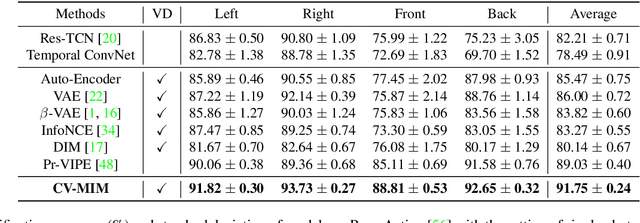
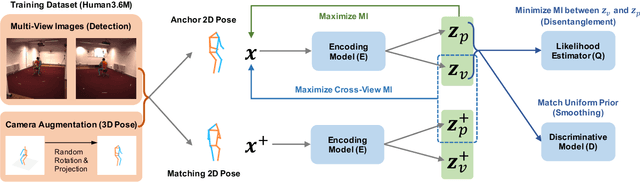
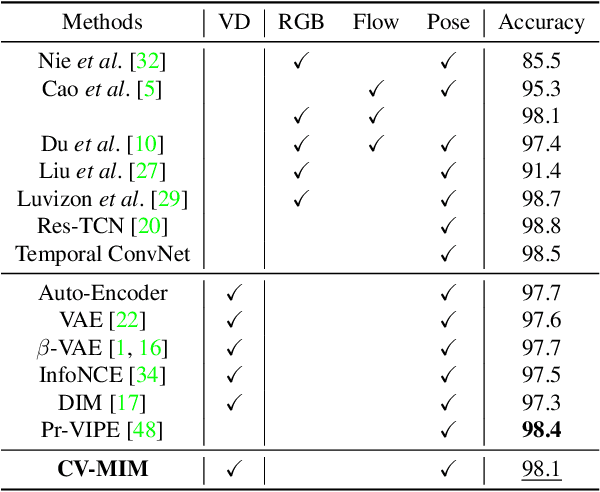
We introduce a novel representation learning method to disentangle pose-dependent as well as view-dependent factors from 2D human poses. The method trains a network using cross-view mutual information maximization (CV-MIM) which maximizes mutual information of the same pose performed from different viewpoints in a contrastive learning manner. We further propose two regularization terms to ensure disentanglement and smoothness of the learned representations. The resulting pose representations can be used for cross-view action recognition. To evaluate the power of the learned representations, in addition to the conventional fully-supervised action recognition settings, we introduce a novel task called single-shot cross-view action recognition. This task trains models with actions from only one single viewpoint while models are evaluated on poses captured from all possible viewpoints. We evaluate the learned representations on standard benchmarks for action recognition, and show that (i) CV-MIM performs competitively compared with the state-of-the-art models in the fully-supervised scenarios; (ii) CV-MIM outperforms other competing methods by a large margin in the single-shot cross-view setting; (iii) and the learned representations can significantly boost the performance when reducing the amount of supervised training data.
View-Invariant, Occlusion-Robust Probabilistic Embedding for Human Pose
Oct 23, 2020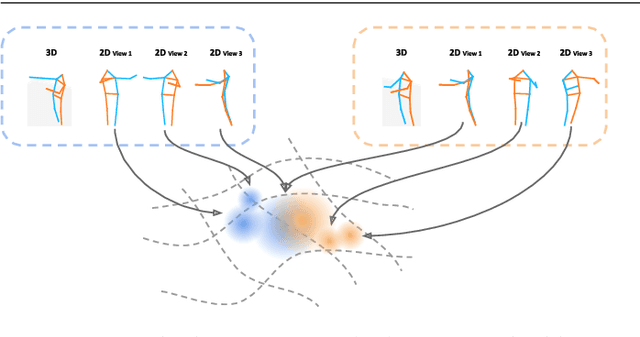
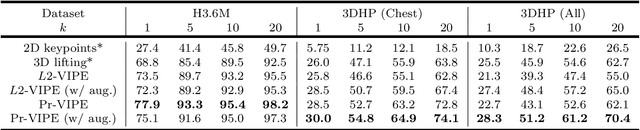
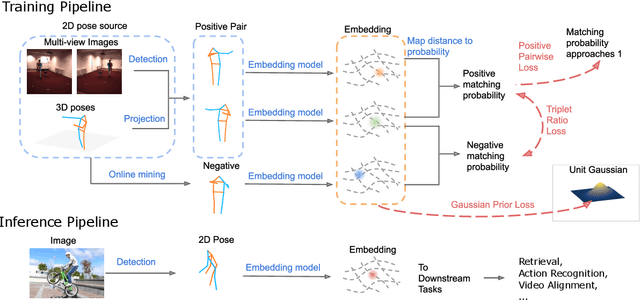

Recognition of human poses and activities is crucial for autonomous systems to interact smoothly with people. However, cameras generally capture human poses in 2D as images and videos, which can have significant appearance variations across viewpoints. To address this, we explore recognizing similarity in 3D human body poses from 2D information, which has not been well-studied in existing works. Here, we propose an approach to learning a compact view-invariant embedding space from 2D body joint keypoints, without explicitly predicting 3D poses. Input ambiguities of 2D poses from projection and occlusion are difficult to represent through a deterministic mapping, and therefore we use probabilistic embeddings. In order to enable our embeddings to work with partially visible input keypoints, we further investigate different keypoint occlusion augmentation strategies during training. Experimental results show that our embedding model achieves higher accuracy when retrieving similar poses across different camera views, in comparison with 3D pose estimation models. We further show that keypoint occlusion augmentation during training significantly improves retrieval performance on partial 2D input poses. Results on action recognition and video alignment demonstrate that our embeddings, without any additional training, achieves competitive performance relative to other models specifically trained for each task.
Unsupervised Event-based Learning of Optical Flow, Depth, and Egomotion
Dec 19, 2018
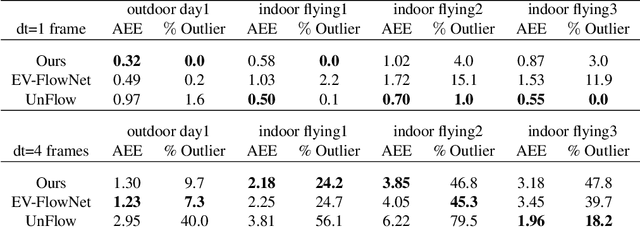
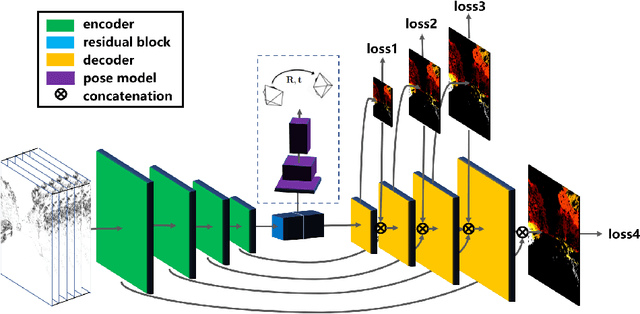
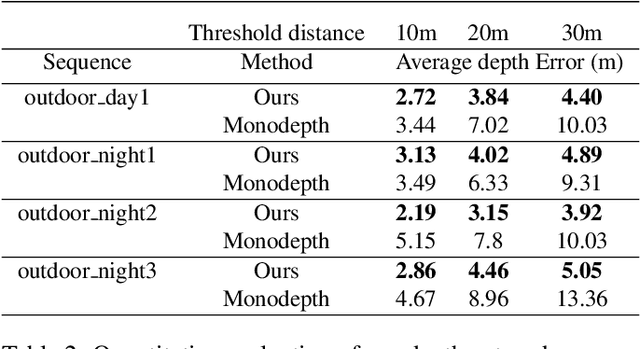
In this work, we propose a novel framework for unsupervised learning for event cameras that learns motion information from only the event stream. In particular, we propose an input representation of the events in the form of a discretized volume that maintains the temporal distribution of the events, which we pass through a neural network to predict the motion of the events. This motion is used to attempt to remove any motion blur in the event image. We then propose a loss function applied to the motion compensated event image that measures the motion blur in this image. We train two networks with this framework, one to predict optical flow, and one to predict egomotion and depths, and evaluate these networks on the Multi Vehicle Stereo Event Camera dataset, along with qualitative results from a variety of different scenes.
Zoom-In-to-Check: Boosting Video Interpolation via Instance-level Discrimination
Dec 04, 2018
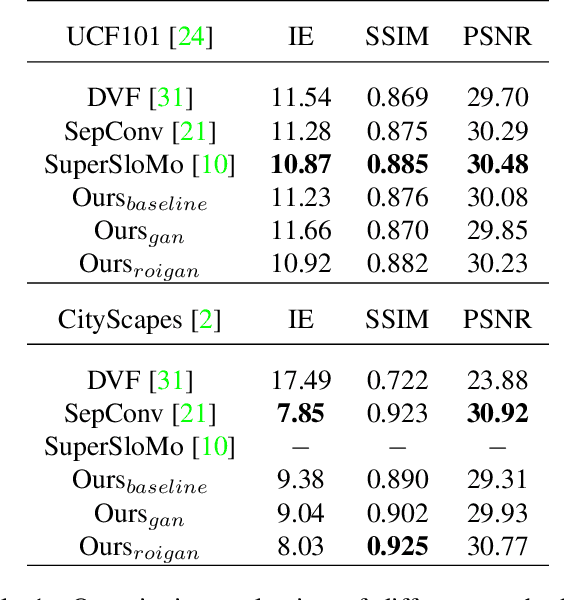
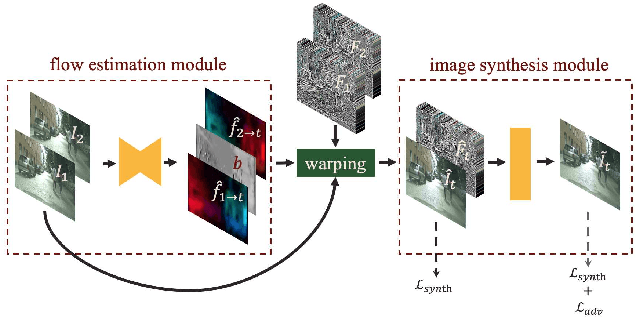
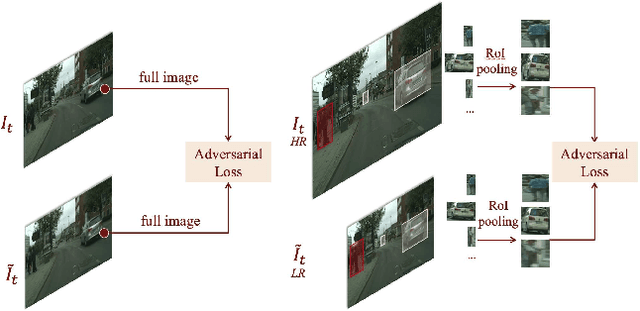
We propose a light-weight video frame interpolation algorithm. Our key innovation is an instance-level supervision that allows information to be learned from the high-resolution version of similar objects. Our experiment shows that the proposed method can generate state-of-art results across different datasets, with fractional computation resources (time and memory) with competing methods. Given two image frames, a cascade network creates an intermediate frame with 1) a flow-warping module that computes large bi-directional optical flow and creates an interpolated image via flow-based warping, followed by 2) an image synthesis module to make fine-scale corrections. In the learning stage, object detection proposals are generated on the interpolated image. Lower resolution objects are zoomed into, and the learning algorithms using an adversarial loss trained on high-resolution objects to guide the system towards the instance-level refinement corrects details of object shape and boundaries. As all our proposed network modules are fully convolutional, our proposed system can be trained end-to-end.
EV-FlowNet: Self-Supervised Optical Flow Estimation for Event-based Cameras
Aug 13, 2018

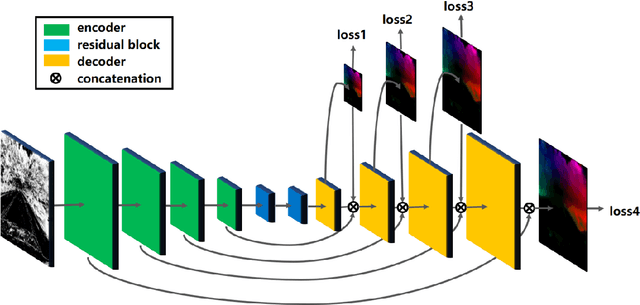

Event-based cameras have shown great promise in a variety of situations where frame based cameras suffer, such as high speed motions and high dynamic range scenes. However, developing algorithms for event measurements requires a new class of hand crafted algorithms. Deep learning has shown great success in providing model free solutions to many problems in the vision community, but existing networks have been developed with frame based images in mind, and there does not exist the wealth of labeled data for events as there does for images for supervised training. To these points, we present EV-FlowNet, a novel self-supervised deep learning pipeline for optical flow estimation for event based cameras. In particular, we introduce an image based representation of a given event stream, which is fed into a self-supervised neural network as the sole input. The corresponding grayscale images captured from the same camera at the same time as the events are then used as a supervisory signal to provide a loss function at training time, given the estimated flow from the network. We show that the resulting network is able to accurately predict optical flow from events only in a variety of different scenes, with performance competitive to image based networks. This method not only allows for accurate estimation of dense optical flow, but also provides a framework for the transfer of other self-supervised methods to the event-based domain.