 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More: Removing Text-regions Improves CLIP Training Efficiency and Robustness
May 08, 2023



The CLIP (Contrastive Language-Image Pre-training) model and its variants are becoming the de facto backbone in many applications. However, training a CLIP model from hundreds of millions of image-text pairs can be prohibitively expensive. Furthermore, the conventional CLIP model doesn't differentiate between the visual semantics and meaning of text regions embedded in images. This can lead to non-robustness when the text in the embedded region doesn't match the image's visual appearance. In this paper, we discuss two effective approaches to improve the efficiency and robustness of CLIP training: (1) augmenting the training dataset while maintaining the same number of optimization steps, and (2) filtering out samples that contain text regions in the image. By doing so, we significantly improve the classification and retrieval accuracy on public benchmarks like ImageNet and CoCo. Filtering out images with text regions also protects the model from typographic attacks. To verify this, we build a new dataset named ImageNet with Adversarial Text Regions (ImageNet-Attr). Our filter-based CLIP model demonstrates a top-1 accuracy of 68.78\%, outperforming previous models whose accuracy was all below 50\%.
STAIR: Learning Sparse Text and Image Representation in Grounded Tokens
Feb 08, 2023Image and text retrieval is one of the foundational tasks in the vision and language domain with multiple real-world applications. State-of-the-art approaches, e.g. CLIP, ALIGN, represent images and texts as dense embeddings and calculate the similarity in the dense embedding space as the matching score. On the other hand, sparse semantic features like bag-of-words models are more interpretable, but believed to suffer from inferior accuracy than dense representations. In this work, we show that it is possible to build a sparse semantic representation that is as powerful as, or even better than, dense presentations. We extend the CLIP model and build a sparse text and image representation (STAIR), where the image and text are mapped to a sparse token space. Each token in the space is a (sub-)word in the vocabulary, which is not only interpretable but also easy to integrate with existing information retrieval systems. STAIR model significantly outperforms a CLIP model with +$4.9\%$ and +$4.3\%$ absolute Recall@1 improvement on COCO-5k text$\rightarrow$image and image$\rightarrow$text retrieval respectively. It also achieved better performance on both of ImageNet zero-shot and linear probing compared to CLIP.
Exploiting Category Names for Few-Shot Classification with Vision-Language Models
Dec 04, 2022Vision-language foundation models pretrained on large-scale data provide a powerful tool for many visual understanding tasks. Notably, many vision-language models build two encoders (visual and textual) that can map two modalities into the same embedding space. As a result, the learned representations achieve good zero-shot performance on tasks like image classification. However, when there are only a few examples per category, the potential of large vision-language models is often underperformed, mainly due to the gap between a large number of parameters and a relatively small amount of training data. This paper shows that we can significantly improve the performance of few-shot classification by using the category names to initialize the classification head. More interestingly, we can borrow the non-perfect category names, or even names from a foreign language, to improve the few-shot classification performance compared with random initialization. With the proposed category name initialization method, our model obtains the state-of-the-art performance on a number of few-shot image classification benchmarks (e.g., 87.37\% on ImageNet and 96.08\% on Stanford Cars, both using five-shot learning). We also investigate and analyze when the benefit of category names diminishes and how to use distillation to improve the performance of smaller models, providing guidance for future research.
SurFit: Learning to Fit Surfaces Improves Few Shot Learning on Point Clouds
Dec 27, 2021

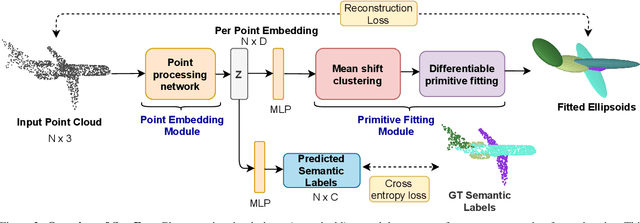
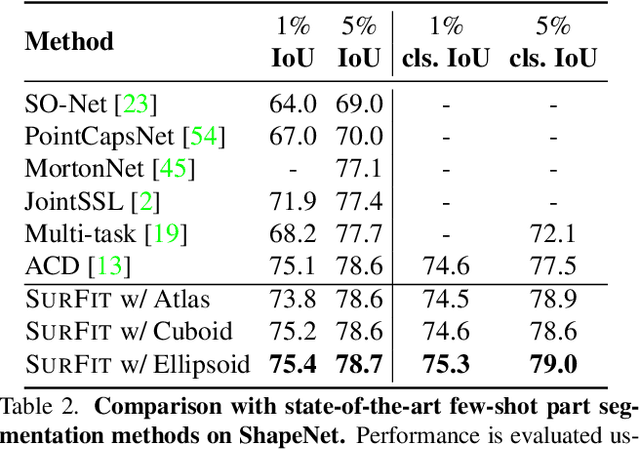
We present SurFit, a simple approach for label efficient learning of 3D shape segmentation networks. SurFit is based on a self-supervised task of decomposing the surface of a 3D shape into geometric primitives. It can be readily applied to existing network architectures for 3D shape segmentation and improves their performance in the few-shot setting, as we demonstrate in the widely used ShapeNet and PartNet benchmarks. SurFit outperforms the prior state-of-the-art in this setting, suggesting that decomposability into primitives is a useful prior for learning representations predictive of semantic parts. We present a number of experiments varying the choice of geometric primitives and downstream tasks to demonstrate the effectiveness of the method.
Input Length Matters: An Empirical Study Of RNN-T And MWER Training For Long-form Telephony Speech Recognition
Oct 08, 2021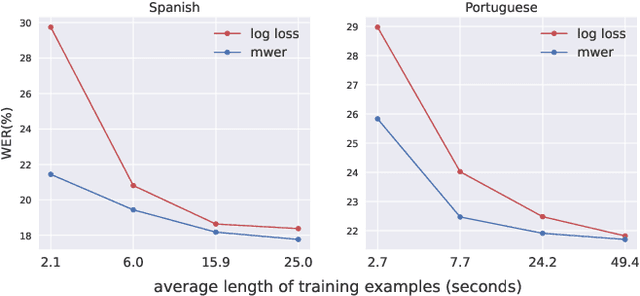
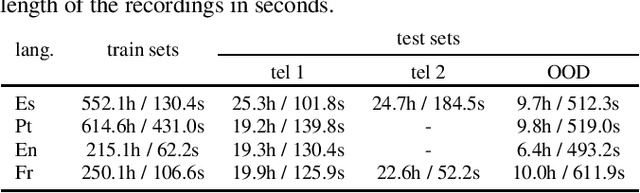


End-to-end models have achieved state-of-the-art results on several automatic speech recognition tasks. However, they perform poorly when evaluated on long-form data, e.g., minutes long conversational telephony audio. One reason the model fails on long-form speech is that it has only seen short utterances during training. This paper presents an empirical study on the effect of training utterance length on the word error rate (WER) for RNN-transducer (RNN-T) model. We compare two widely used training objectives, log loss (or RNN-T loss) and minimum word error rate (MWER) loss. We conduct experiments on telephony datasets in four languages. Our experiments show that for both losses, the WER on long-form speech reduces substantially as the training utterance length increases. The average relative WER gain is 15.7% for log loss and 8.8% for MWER loss. When training on short utterances, MWER loss leads to a lower WER than the log loss. Such difference between the two losses diminishes when the input length increases.
Improving Confidence Estimation on Out-of-Domain Data for End-to-End Speech Recognition
Oct 07, 2021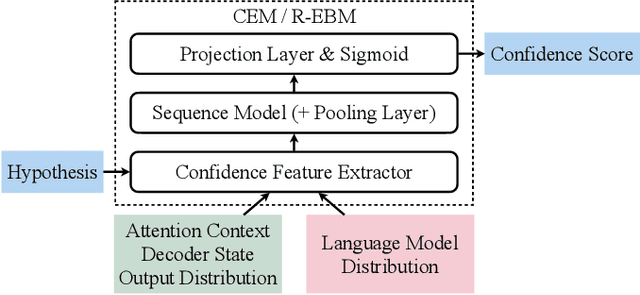
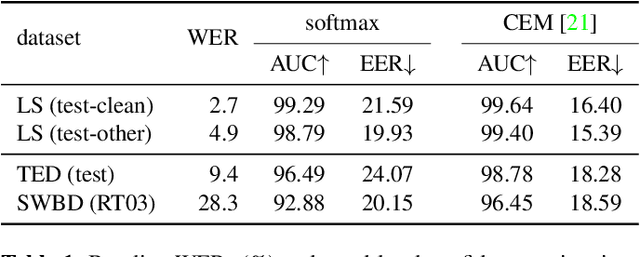
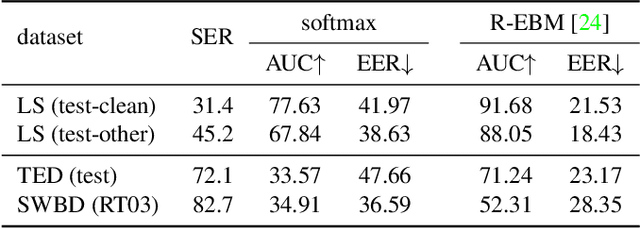
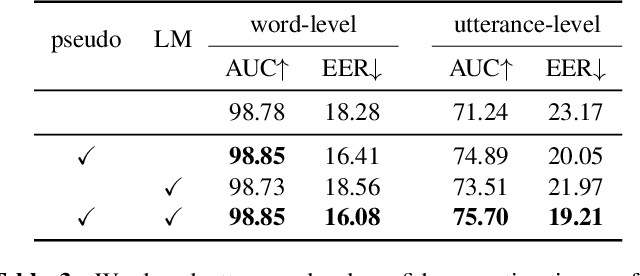
As end-to-end automatic speech recognition (ASR) models reach promising performance, various downstream tasks rely on good confidence estimators for these systems. Recent research has shown that model-based confidence estimators have a significant advantage over using the output softmax probabilities. If the input data to the speech recogniser is from mismatched acoustic and linguistic conditions, the ASR performance and the corresponding confidence estimators may exhibit severe degradation. Since confidence models are often trained on the same in-domain data as the ASR, generalising to out-of-domain (OOD) scenarios is challenging. By keeping the ASR model untouched, this paper proposes two approaches to improve the model-based confidence estimators on OOD data: using pseudo transcriptions and an additional OOD language model. With an ASR model trained on LibriSpeech, experiments show that the proposed methods can significantly improve the confidence metrics on TED-LIUM and Switchboard datasets while preserving in-domain performance. Furthermore, the improved confidence estimators are better calibrated on OOD data and can provide a much more reliable criterion for data selection.
BigSSL: Exploring the Frontier of Large-Scale Semi-Supervised Learning for Automatic Speech Recognition
Oct 01, 2021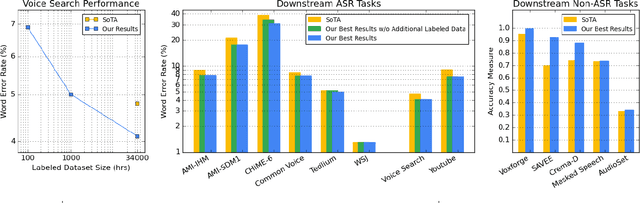
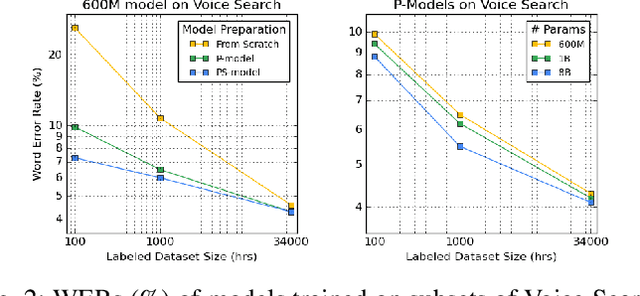
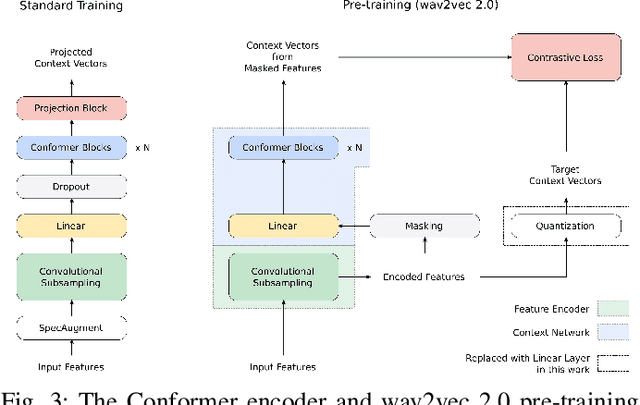
We summarize the results of a host of efforts using giant automatic speech recognition (ASR) models pre-trained using large, diverse unlabeled datasets containing approximately a million hours of audio. We find that the combination of pre-training, self-training and scaling up model size greatly increases data efficiency, even for extremely large tasks with tens of thousands of hours of labeled data. In particular, on an ASR task with 34k hours of labeled data, by fine-tuning an 8 billion parameter pre-trained Conformer model we can match state-of-the-art (SoTA) performance with only 3% of the training data and significantly improve SoTA with the full training set. We also report on the universal benefits gained from using big pre-trained and self-trained models for a large set of downstream tasks that cover a wide range of speech domains and span multiple orders of magnitudes of dataset sizes, including obtaining SoTA performance on many public benchmarks. In addition, we utilize the learned representation of pre-trained networks to achieve SoTA results on non-ASR tasks.
Multi-Task Learning for End-to-End ASR Word and Utterance Confidence with Deletion Prediction
Apr 26, 2021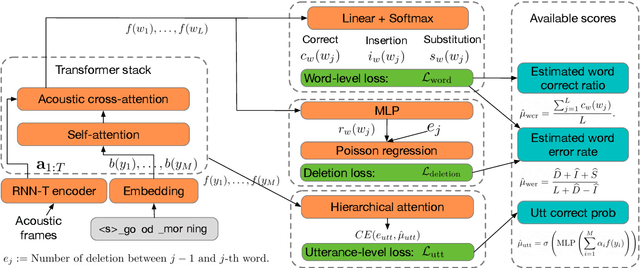
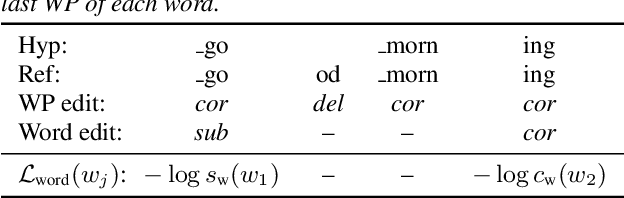
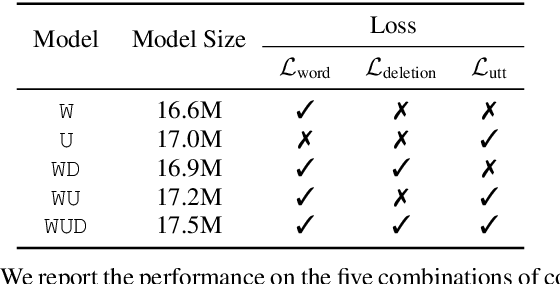
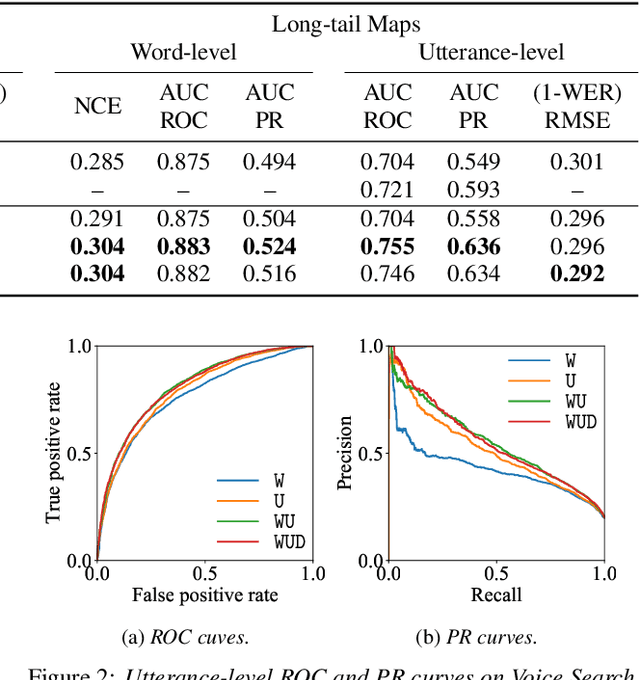
Confidence scores are very useful for downstream applications of automatic speech recognition (ASR) systems. Recent works have proposed using neural networks to learn word or utterance confidence scores for end-to-end ASR. In those studies, word confidence by itself does not model deletions, and utterance confidence does not take advantage of word-level training signals. This paper proposes to jointly learn word confidence, word deletion, and utterance confidence. Empirical results show that multi-task learning with all three objectives improves confidence metrics (NCE, AUC, RMSE) without the need for increasing the model size of the confidence estimation module. Using the utterance-level confidence for rescoring also decreases the word error rates on Google's Voice Search and Long-tail Maps datasets by 3-5% relative, without needing a dedicated neural rescorer.
Bridging the gap between streaming and non-streaming ASR systems bydistilling ensembles of CTC and RNN-T models
Apr 25, 2021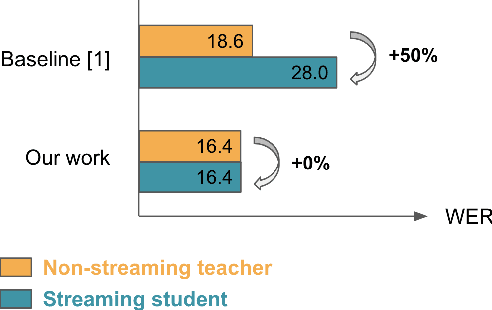
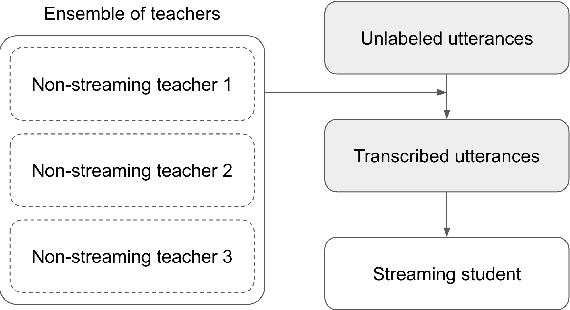

Streaming end-to-end automatic speech recognition (ASR) systems are widely used in everyday applications that require transcribing speech to text in real-time. Their minimal latency makes them suitable for such tasks. Unlike their non-streaming counterparts, streaming models are constrained to be causal with no future context and suffer from higher word error rates (WER). To improve streaming models, a recent study [1] proposed to distill a non-streaming teacher model on unsupervised utterances, and then train a streaming student using the teachers' predictions. However, the performance gap between teacher and student WERs remains high. In this paper, we aim to close this gap by using a diversified set of non-streaming teacher models and combining them using Recognizer Output Voting Error Reduction (ROVER). In particular, we show that, despite being weaker than RNN-T models, CTC models are remarkable teachers. Further, by fusing RNN-T and CTC models together, we build the strongest teachers. The resulting student models drastically improve upon streaming models of previous work [1]: the WER decreases by 41% on Spanish, 27% on Portuguese, and 13% on French.
Exploring Targeted Universal Adversarial Perturbations to End-to-end ASR Models
Apr 06, 2021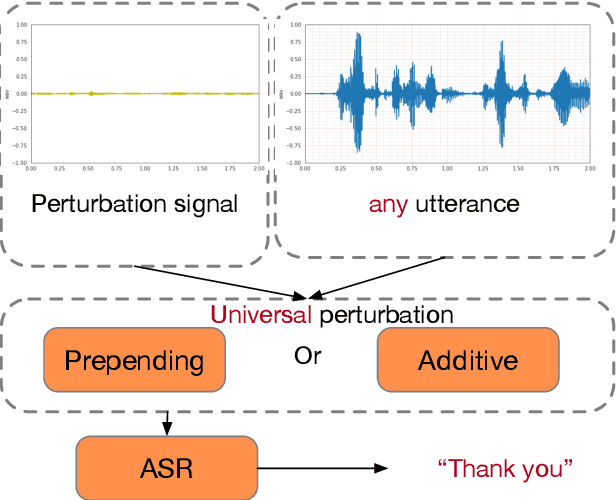
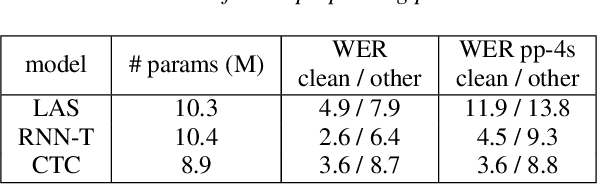
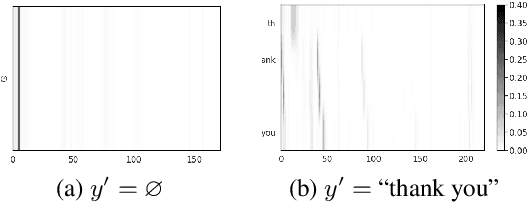
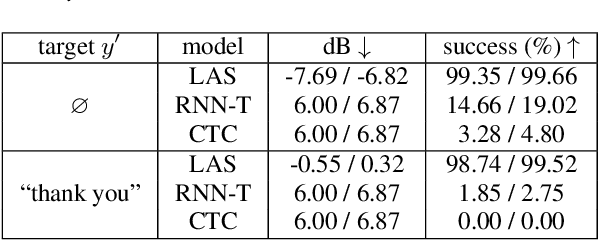
Although end-to-end automatic speech recognition (e2e ASR) models are widely deployed in many applications, there have been very few studies to understand models' robustness against adversarial perturbations. In this paper, we explore whether a targeted universal perturbation vector exists for e2e ASR models. Our goal is to find perturbations that can mislead the models to predict the given targeted transcript such as "thank you" or empty string on any input utterance. We study two different attacks, namely additive and prepending perturbations, and their performances on the state-of-the-art LAS, CTC and RNN-T models. We find that LAS is the most vulnerable to perturbations among the three models. RNN-T is more robust against additive perturbations, especially on long utterances. And CTC is robust against both additive and prepending perturbations. To attack RNN-T, we find prepending perturbation is more effective than the additive perturbation, and can mislead the models to predict the same short target on utterances of arbitrary length.