 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning in Big Model Era: Domain-Specific Multimodal Large Models
Aug 24, 2023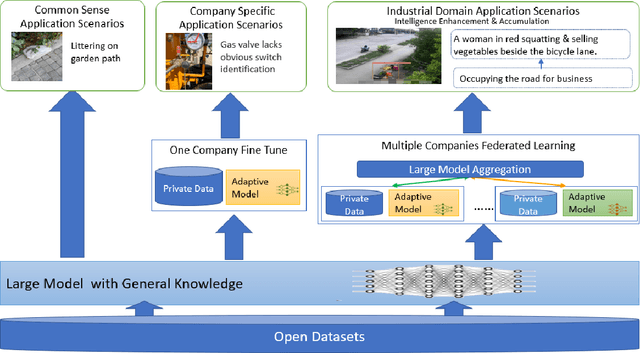
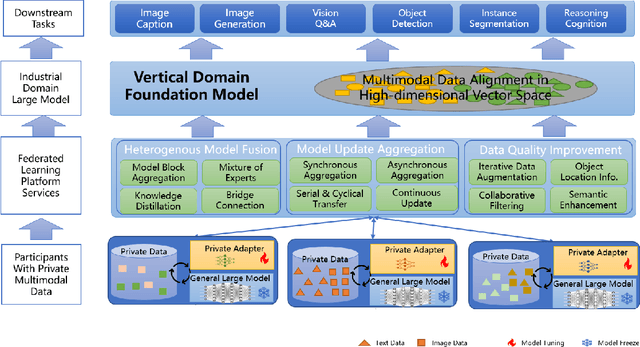
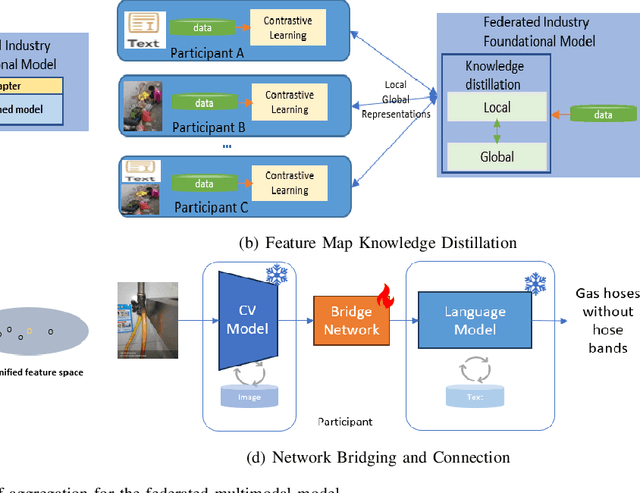
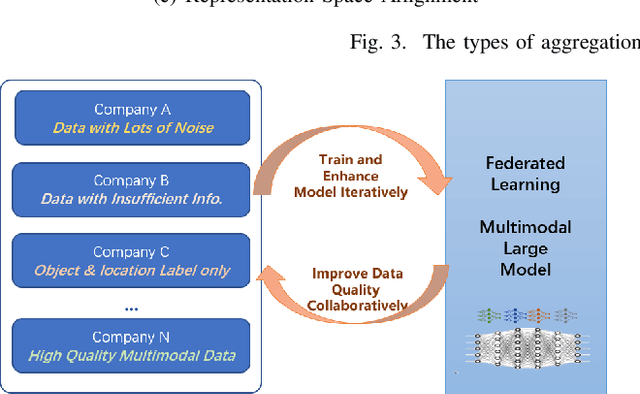
Multimodal data, which can comprehensively perceive and recognize the physical world, has become an essential path towards general artificial intelligence. However, multimodal large models trained on public datasets often underperform in specific industrial domains. This paper proposes a multimodal federated learning framework that enables multiple enterprises to utilize private domain data to collaboratively train large models for vertical domains, achieving intelligent services across scenarios. The authors discuss in-depth the strategic transformation of federated learning in terms of intelligence foundation and objectives in the era of big model, as well as the new challenges faced in heterogeneous data, model aggregation, performance and cost trade-off, data privacy, and incentive mechanism. The paper elaborates a case study of leading enterprises contributing multimodal data and expert knowledge to city safety operation management , including distributed deployment and efficient coordination of the federated learning platform, technical innovations on data quality improvement based on large model capabilities and efficient joint fine-tuning approaches. Preliminary experiments show that enterprises can enhance and accumulate intelligent capabilities through multimodal model federated learning, thereby jointly creating an smart city model that provides high-quality intelligent services covering energy infrastructure safety, residential community security, and urban operation management. The established federated learning cooperation ecosystem is expected to further aggregate industry, academia, and research resources, realize large models in multiple vertical domains, and promote the large-scale industrial application of artificial intelligence and cutting-edge research on multimodal federated learning.
SuperCLUE: A Comprehensive Chinese Large Language Model Benchmark
Jul 27, 2023Large language models (LLMs) have shown the potential to be integrated into human daily lives. Therefore, user preference is the most critical criterion for assessing LLMs' performance in real-world scenarios. However, existing benchmarks mainly focus on measuring models' accuracy using multi-choice questions, which limits the understanding of their capabilities in real applications. We fill this gap by proposing a comprehensive Chinese benchmark SuperCLUE, named after another popular Chinese LLM benchmark CLUE. SuperCLUE encompasses three sub-tasks: actual users' queries and ratings derived from an LLM battle platform (CArena), open-ended questions with single and multiple-turn dialogues (OPEN), and closed-ended questions with the same stems as open-ended single-turn ones (CLOSE). Our study shows that accuracy on closed-ended questions is insufficient to reflect human preferences achieved on open-ended ones. At the same time, they can complement each other to predict actual user preferences. We also demonstrate that GPT-4 is a reliable judge to automatically evaluate human preferences on open-ended questions in a Chinese context. Our benchmark will be released at https://www.CLUEbenchmarks.com
MCPA: Multi-scale Cross Perceptron Attention Network for 2D Medical Image Segmentation
Jul 27, 2023The UNet architecture, based on Convolutional Neural Networks (CNN), has demonstrated its remarkable performance in medical image analysis. However, it faces challenges in capturing long-range dependencies due to the limited receptive fields and inherent bias of convolutional operations. Recently, numerous transformer-based techniques have been incorporated into the UNet architecture to overcome this limitation by effectively capturing global feature correlations. However, the integration of the Transformer modules may result in the loss of local contextual information during the global feature fusion process. To overcome these challenges, we propose a 2D medical image segmentation model called Multi-scale Cross Perceptron Attention Network (MCPA). The MCPA consists of three main components: an encoder, a decoder, and a Cross Perceptron. The Cross Perceptron first captures the local correlations using multiple Multi-scale Cross Perceptron modules, facilitating the fusion of features across scales. The resulting multi-scale feature vectors are then spatially unfolded, concatenated, and fed through a Global Perceptron module to model global dependencies. Furthermore, we introduce a Progressive Dual-branch Structure to address the semantic segmentation of the image involving finer tissue structures. This structure gradually shifts the segmentation focus of MCPA network training from large-scale structural features to more sophisticated pixel-level features. We evaluate our proposed MCPA model on several publicly available medical image datasets from different tasks and devices, including the open large-scale dataset of CT (Synapse), MRI (ACDC), fundus camera (DRIVE, CHASE_DB1, HRF), and OCTA (ROSE). The experimental results show that our MCPA model achieves state-of-the-art performance. The code is available at https://github.com/simonustc/MCPA-for-2D-Medical-Image-Segmentation.
A Surrogate Data Assimilation Model for the Estimation of Dynamical System in a Limited Area
Jul 14, 2023We propose a novel learning-based surrogate data assimilation (DA) model for efficient state estimation in a limited area. Our model employs a feedforward neural network for online computation, eliminating the need for integrating high-dimensional limited-area models. This approach offers significant computational advantages over traditional DA algorithms. Furthermore, our method avoids the requirement of lateral boundary conditions for the limited-area model in both online and offline computations. The design of our surrogate DA model is built upon a robust theoretical framework that leverages two fundamental concepts: observability and effective region. The concept of observability enables us to quantitatively determine the optimal amount of observation data necessary for accurate DA. Meanwhile, the concept of effective region substantially reduces the computational burden associated with computing observability and generating training data.
P-vectors: A Parallel-Coupled TDNN/Transformer Network for Speaker Verification
May 25, 2023



Typically, the Time-Delay Neural Network (TDNN) and Transformer can serve as a backbone for Speaker Verification (SV). Both of them have advantages and disadvantages from the perspective of global and local feature modeling. How to effectively integrate these two style features is still an open issue. In this paper, we explore a Parallel-coupled TDNN/Transformer Network (p-vectors) to replace the serial hybrid networks. The p-vectors allows TDNN and Transformer to learn the complementary information from each other through Soft Feature Alignment Interaction (SFAI) under the premise of preserving local and global features. Also, p-vectors uses the Spatial Frequency-channel Attention (SFA) to enhance the spatial interdependence modeling for input features. Finally, the outputs of dual branches of p-vectors are combined by Embedding Aggregation Layer (EAL). Experiments show that p-vectors outperforms MACCIF-TDNN and MFA-Conformer with relative improvements of 11.5% and 13.9% in EER on VoxCeleb1-O.
Discovering A Variety of Objects in Spatio-Temporal Human-Object Interactions
Nov 18, 2022



Spatio-temporal Human-Object Interaction (ST-HOI) detection aims at detecting HOIs from videos, which is crucial for activity understanding. In daily HOIs, humans often interact with a variety of objects, e.g., holding and touching dozens of household items in cleaning. However, existing whole body-object interaction video benchmarks usually provide limited object classes. Here, we introduce a new benchmark based on AVA: Discovering Interacted Objects (DIO) including 51 interactions and 1,000+ objects. Accordingly, an ST-HOI learning task is proposed expecting vision systems to track human actors, detect interactions and simultaneously discover interacted objects. Even though today's detectors/trackers excel in object detection/tracking tasks, they perform unsatisfied to localize diverse/unseen objects in DIO. This profoundly reveals the limitation of current vision systems and poses a great challenge. Thus, how to leverage spatio-temporal cues to address object discovery is explored, and a Hierarchical Probe Network (HPN) is devised to discover interacted objects utilizing hierarchical spatio-temporal human/context cues. In extensive experiments, HPN demonstrates impressive performance. Data and code are available at https://github.com/DirtyHarryLYL/HAKE-AVA.
Phased Progressive Learning with Coupling-Regulation-Imbalance Loss for Imbalanced Classification
May 24, 2022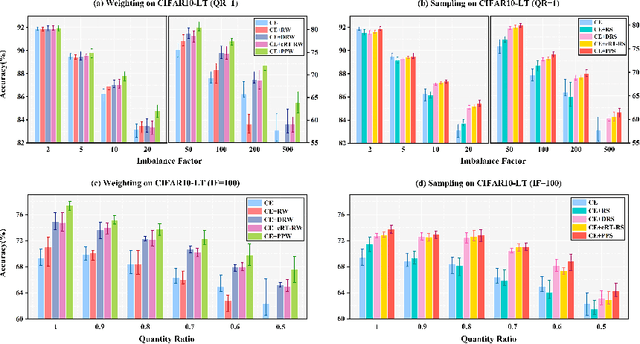
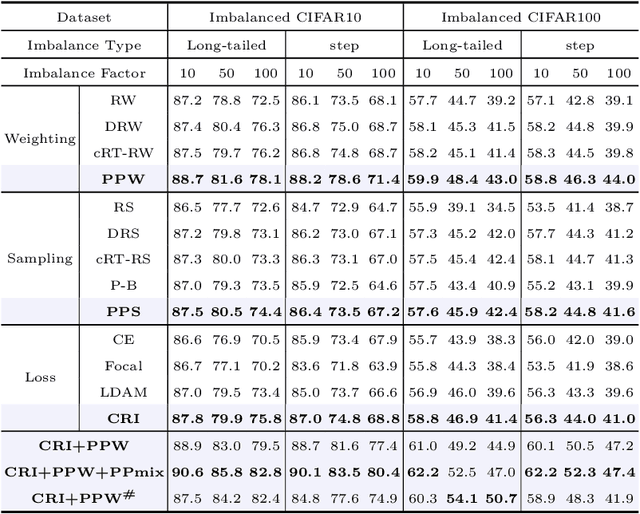
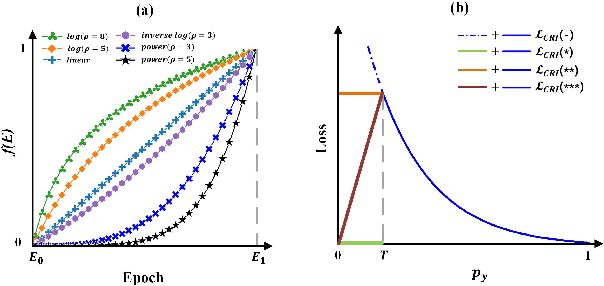
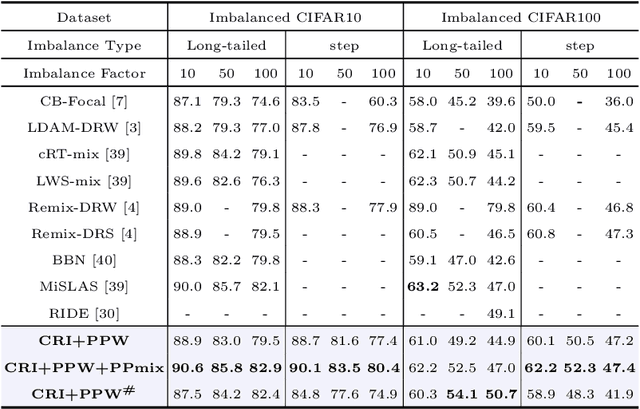
Deep neural networks generally perform poorly with datasets that suffer from quantity imbalance and classification difficulty imbalance between different classes. In order to alleviate the problem of dataset bias or domain shift in the existing two-stage approaches, a phased progressive learning schedule was proposed for smoothly transferring the training emphasis from representation learning to upper classifier training. This has greater effectivity on datasets that have more severe imbalances or smaller scales. A coupling-regulation-imbalance loss function was designed, coupling a correction term, Focal loss and LDAM loss. Coupling-regulation-imbalance loss can better deal with quantity imbalance and outliers, while regulating focus-of-attention of samples with a variety of classification difficulties. Excellent results were achieved on multiple benchmark datasets using these approaches and they can be easily generalized for other imbalanced classification models. Our code will be open source soon.
On Robust Classification using Contractive Hamiltonian Neural ODEs
Mar 22, 2022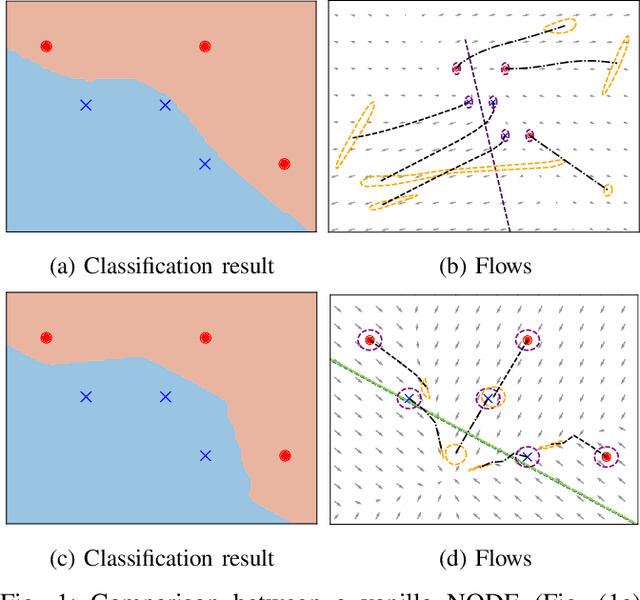

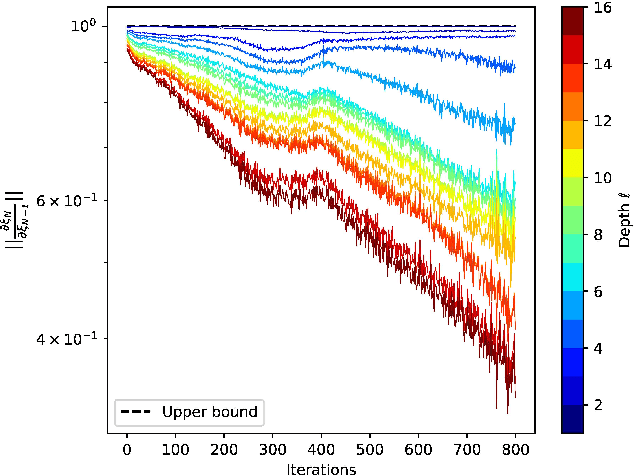
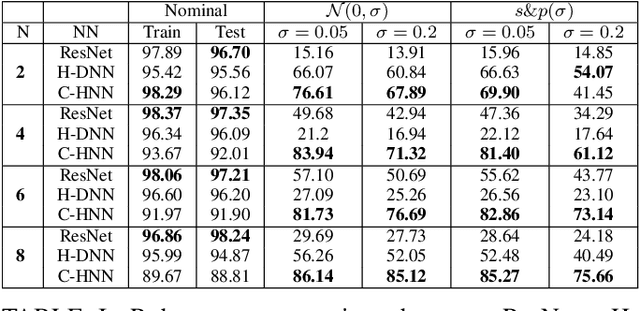
Deep neural networks can be fragile and sensitive to small input perturbations that might cause a significant change in the output. In this paper, we employ contraction theory to improve the robustness of neural ODEs (NODEs). A dynamical system is contractive if all solutions with different initial conditions converge to each other asymptotically. As a consequence, perturbations in initial conditions become less and less relevant over time. Since in NODEs, the input data corresponds to the initial condition of dynamical systems, we show contractivity can mitigate the effect of input perturbations. More precisely, inspired by NODEs with Hamiltonian dynamics, we propose a class of contractive Hamiltonian NODEs (CH-NODEs). By properly tuning a scalar parameter, CH-NODEs ensure contractivity by design and can be trained using standard backpropagation and gradient descent algorithms. Moreover, CH-NODEs enjoy built-in guarantees of non-exploding gradients, which ensures a well-posed training process. Finally, we demonstrate the robustness of CH-NODEs on the MNIST image classification problem with noisy test datasets.
HAKE: A Knowledge Engine Foundation for Human Activity Understanding
Feb 14, 2022



Human activity understanding is of widespread interest in artificial intelligence and spans diverse applications like health care and behavior analysis. Although there have been advances with deep learning, it remains challenging. The object recognition-like solutions usually try to map pixels to semantics directly, but activity patterns are much different from object patterns, thus hindering another success. In this work, we propose a novel paradigm to reformulate this task in two-stage: first mapping pixels to an intermediate space spanned by atomic activity primitives, then programming detected primitives with interpretable logic rules to infer semantics. To afford a representative primitive space, we build a knowledge base including 26+ M primitive labels and logic rules from human priors or automatic discovering. Our framework, Human Activity Knowledge Engine (HAKE), exhibits superior generalization ability and performance upon canonical methods on challenging benchmarks. Code and data are available at http://hake-mvig.cn/.
Data-Driven Computational Methods for the Domain of Attraction and Zubov's Equation
Dec 29, 2021

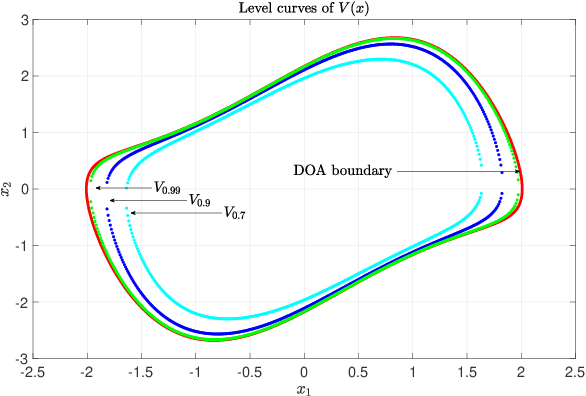
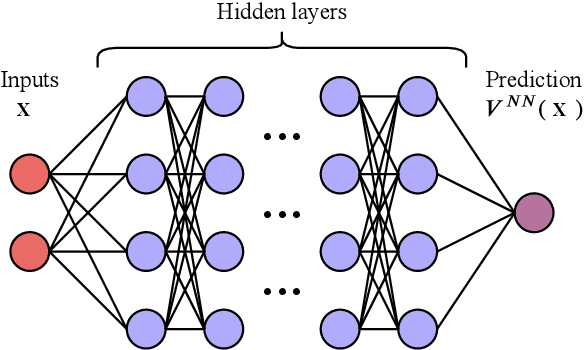
This paper deals with a special type of Lyapunov functions, namely the solution of Zubov's equation. Such a function can be used to characterize the domain of attraction for systems of ordinary differential equations. We derive and prove an integral form solution to Zubov's equation. For numerical computation, we develop two data-driven methods. One is based on the integration of an augmented system of differential equations; and the other one is based on deep learning. The former is effective for systems with a relatively low state space dimension and the latter is developed for high dimensional problems. The deep learning method is applied to a New England 10-generator power system model. We prove that a neural network approximation exists for the Lyapunov function of power systems such that the approximation error is a cubic polynomial of the number of generators. The error convergence rate as a function of n, the number of neurons, is proved.