 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Cardiac Latent Representations in Vectorcardiogram Space
May 29, 2026Electrocardiography (ECG) is a cornerstone of cardiac assessment, making the learning of informative ECG representations fundamental to tasks ranging from disease diagnosis to clinical report generation. However, existing methods operate almost exclusively in the observable ECG signal space. In practice, the standard twelve-lead ECG represents multiple projections of the same underlying cardiac electrical activity from different spatial orientations. Therefore, representation learning in the ECG space inevitably introduces substantial redundancy, which may lead to spurious correlations and increased risk of overfitting. To address this and motivated by the Frank vectorcardiogram (VCG) model, we propose learning a unified latent representation of cardiac electrical activity directly in the VCG space. We introduce LVCG, the first general self-supervised representation learning framework designed to operate in this physically grounded latent space. By learning view-invariant latent VCG representations rather than lead-specific artifacts, VCG minimizes redundancy and improves generalization. LVCG generally outperforms ECG-space baselines across tasks, demonstrating enhanced robustness and generalization, especially in domain shift settings.
Towards Universal Large-Scale Foundational Model for Natural Gas Demand Forecasting
Sep 24, 2024



In the context of global energy strategy, accurate natural gas demand forecasting is crucial for ensuring efficient resource allocation and operational planning. Traditional forecasting methods struggle to cope with the growing complexity and variability of gas consumption patterns across diverse industries and commercial sectors. To address these challenges, we propose the first foundation model specifically tailored for natural gas demand forecasting. Foundation models, known for their ability to generalize across tasks and datasets, offer a robust solution to the limitations of traditional methods, such as the need for separate models for different customer segments and their limited generalization capabilities. Our approach leverages contrastive learning to improve prediction accuracy in real-world scenarios, particularly by tackling issues such as noise in historical consumption data and the potential misclassification of similar data samples, which can lead to degradation in the quaility of the representation and thus the accuracy of downstream forecasting tasks. By integrating advanced noise filtering techniques within the contrastive learning framework, our model enhances the quality of learned representations, leading to more accurate predictions. Furthermore, the model undergoes industry-specific fine-tuning during pretraining, enabling it to better capture the unique characteristics of gas consumption across various sectors. We conducted extensive experiments using a large-scale dataset from ENN Group, which includes data from over 10,000 industrial, commercial, and welfare-related customers across multiple regions. Our model outperformed existing state-of-the-art methods, demonstrating a relative improvement in MSE by 3.68\% and in MASE by 6.15\% compared to the best available model.
Robust Model Aggregation for Heterogeneous Federated Learning: Analysis and Optimizations
May 11, 2024



Conventional synchronous federated learning (SFL) frameworks suffer from performance degradation in heterogeneous systems due to imbalanced local data size and diverse computing power on the client side. To address this problem, asynchronous FL (AFL) and semi-asynchronous FL have been proposed to recover the performance loss by allowing asynchronous aggregation. However, asynchronous aggregation incurs a new problem of inconsistency between local updates and global updates. Motivated by the issues of conventional SFL and AFL, we first propose a time-driven SFL (T-SFL) framework for heterogeneous systems. The core idea of T-SFL is that the server aggregates the models from different clients, each with varying numbers of iterations, at regular time intervals. To evaluate the learning performance of T-SFL, we provide an upper bound on the global loss function. Further, we optimize the aggregation weights to minimize the developed upper bound. Then, we develop a discriminative model selection (DMS) algorithm that removes local models from clients whose number of iterations falls below a predetermined threshold. In particular, this algorithm ensures that each client's aggregation weight accurately reflects its true contribution to the global model update, thereby improving the efficiency and robustness of the system. To validate the effectiveness of T-SFL with the DMS algorithm, we conduct extensive experiments using several popular datasets including MNIST, Cifar-10, Fashion-MNIST, and SVHN. The experimental results demonstrate that T-SFL with the DMS algorithm can reduce the latency of conventional SFL by 50\%, while achieving an average 3\% improvement in learning accuracy over state-of-the-art AFL algorithms.
Advances and Open Challenges in Federated Learning with Foundation Models
Apr 29, 2024



The integration of Foundation Models (FMs) with Federated Learning (FL) presents a transformative paradigm in Artificial Intelligence (AI), offering enhanced capabilities while addressing concerns of privacy, data decentralization, and computational efficiency. This paper provides a comprehensive survey of the emerging field of Federated Foundation Models (FedFM), elucidating their synergistic relationship and exploring novel methodologies, challenges, and future directions that the FL research field needs to focus on in order to thrive in the age of foundation models. A systematic multi-tiered taxonomy is proposed, categorizing existing FedFM approaches for model training, aggregation, trustworthiness, and incentivization. Key challenges, including how to enable FL to deal with high complexity of computational demands, privacy considerations, contribution evaluation, and communication efficiency, are thoroughly discussed. Moreover, the paper explores the intricate challenges of communication, scalability and security inherent in training/fine-tuning FMs via FL, highlighting the potential of quantum computing to revolutionize the training, inference, optimization and data encryption processes. This survey underscores the importance of further research to propel innovation in FedFM, emphasizing the need for developing trustworthy solutions. It serves as a foundational guide for researchers and practitioners interested in contributing to this interdisciplinary and rapidly advancing field.
STMGF: An Effective Spatial-Temporal Multi-Granularity Framework for Traffic Forecasting
Apr 08, 2024



Accurate Traffic Prediction is a challenging task in intelligent transportation due to the spatial-temporal aspects of road networks. The traffic of a road network can be affected by long-distance or long-term dependencies where existing methods fall short in modeling them. In this paper, we introduce a novel framework known as Spatial-Temporal Multi-Granularity Framework (STMGF) to enhance the capture of long-distance and long-term information of the road networks. STMGF makes full use of different granularity information of road networks and models the long-distance and long-term information by gathering information in a hierarchical interactive way. Further, it leverages the inherent periodicity in traffic sequences to refine prediction results by matching with recent traffic data. We conduct experiments on two real-world datasets, and the results demonstrate that STMGF outperforms all baseline models and achieves state-of-the-art performance.
HiMTM: Hierarchical Multi-Scale Masked Time Series Modeling for Long-Term Forecasting
Jan 10, 2024



Time series forecasting is crucial and challenging in the real world. The recent surge in interest regarding time series foundation models, which cater to a diverse array of downstream tasks, is noteworthy. However, existing methods often overlook the multi-scale nature of time series, an aspect crucial for precise forecasting. To bridge this gap, we propose HiMTM, a hierarchical multi-scale masked time series modeling method designed for long-term forecasting. Specifically, it comprises four integral components: (1) hierarchical multi-scale transformer (HMT) to capture temporal information at different scales; (2) decoupled encoder-decoder (DED) forces the encoder to focus on feature extraction, while the decoder to focus on pretext tasks; (3) multi-scale masked reconstruction (MMR) provides multi-stage supervision signals for pre-training; (4) cross-scale attention fine-tuning (CSA-FT) to capture dependencies between different scales for forecasting. Collectively, these components enhance multi-scale feature extraction capabilities in masked time series modeling and contribute to improved prediction accuracy. We conduct extensive experiments on 7 mainstream datasets to prove that HiMTM has obvious advantages over contemporary self-supervised and end-to-end learning methods. The effectiveness of HiMTM is further showcased by its application in the industry of natural gas demand forecasting.
Federated Learning in Big Model Era: Domain-Specific Multimodal Large Models
Aug 24, 2023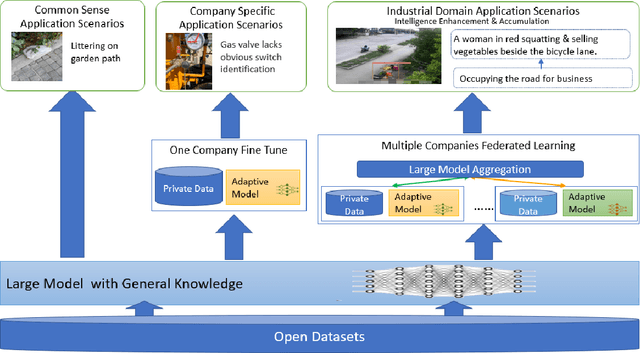
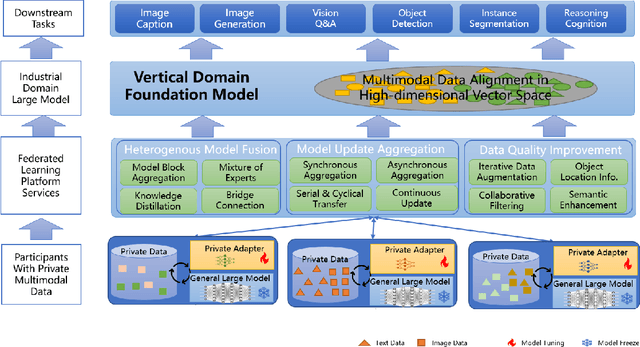
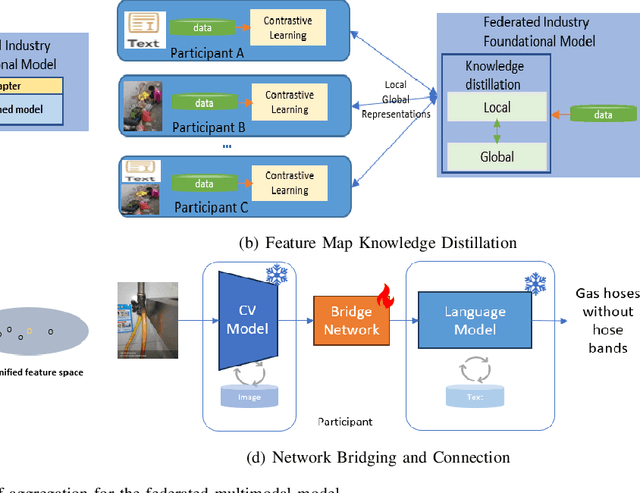
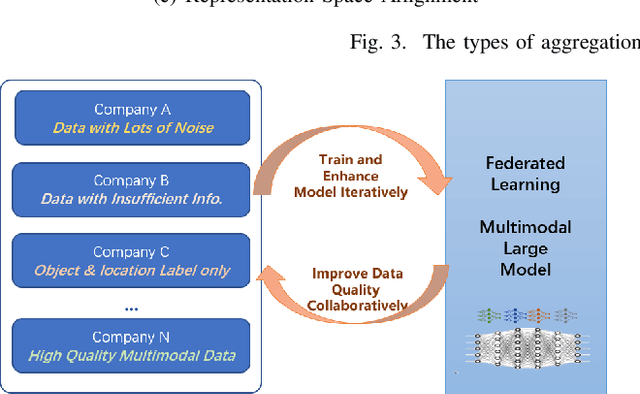
Multimodal data, which can comprehensively perceive and recognize the physical world, has become an essential path towards general artificial intelligence. However, multimodal large models trained on public datasets often underperform in specific industrial domains. This paper proposes a multimodal federated learning framework that enables multiple enterprises to utilize private domain data to collaboratively train large models for vertical domains, achieving intelligent services across scenarios. The authors discuss in-depth the strategic transformation of federated learning in terms of intelligence foundation and objectives in the era of big model, as well as the new challenges faced in heterogeneous data, model aggregation, performance and cost trade-off, data privacy, and incentive mechanism. The paper elaborates a case study of leading enterprises contributing multimodal data and expert knowledge to city safety operation management , including distributed deployment and efficient coordination of the federated learning platform, technical innovations on data quality improvement based on large model capabilities and efficient joint fine-tuning approaches. Preliminary experiments show that enterprises can enhance and accumulate intelligent capabilities through multimodal model federated learning, thereby jointly creating an smart city model that provides high-quality intelligent services covering energy infrastructure safety, residential community security, and urban operation management. The established federated learning cooperation ecosystem is expected to further aggregate industry, academia, and research resources, realize large models in multiple vertical domains, and promote the large-scale industrial application of artificial intelligence and cutting-edge research on multimodal federated learning.
The Prospect of Enhancing Large-Scale Heterogeneous Federated Learning with Transformers
Aug 22, 2023



Federated learning (FL) addresses data privacy concerns by enabling collaborative training of AI models across distributed data owners. Wide adoption of FL faces the fundamental challenges of data heterogeneity and the large scale of data owners involved. In this paper, we investigate the prospect of Transformer-based FL models for achieving generalization and personalization in this setting. We conduct extensive comparative experiments involving FL with Transformers, ResNet, and personalized ResNet-based FL approaches under various scenarios. These experiments consider varying numbers of data owners to demonstrate Transformers' advantages over deep neural networks in large-scale heterogeneous FL tasks. In addition, we analyze the superior performance of Transformers by comparing the Centered Kernel Alignment (CKA) representation similarity across different layers and FL models to gain insight into the reasons behind their promising capabilities.
Hierarchical Federated Learning Incentivization for Gas Usage Estimation
Jul 01, 2023



Accurately estimating gas usage is essential for the efficient functioning of gas distribution networks and saving operational costs. Traditional methods rely on centralized data processing, which poses privacy risks. Federated learning (FL) offers a solution to this problem by enabling local data processing on each participant, such as gas companies and heating stations. However, local training and communication overhead may discourage gas companies and heating stations from actively participating in the FL training process. To address this challenge, we propose a Hierarchical FL Incentive Mechanism for Gas Usage Estimation (HI-GAS), which has been testbedded in the ENN Group, one of the leading players in the natural gas and green energy industry. It is designed to support horizontal FL among gas companies, and vertical FL among each gas company and heating station within a hierarchical FL ecosystem, rewarding participants based on their contributions to FL. In addition, a hierarchical FL model aggregation approach is also proposed to improve the gas usage estimation performance by aggregating models at different levels of the hierarchy. The incentive scheme employs a multi-dimensional contribution-aware reward distribution function that combines the evaluation of data quality and model contribution to incentivize both gas companies and heating stations within their jurisdiction while maintaining fairness. Results of extensive experiments validate the effectiveness of the proposed mechanism.
Efficient Training of Large-scale Industrial Fault Diagnostic Models through Federated Opportunistic Block Dropout
Feb 22, 2023

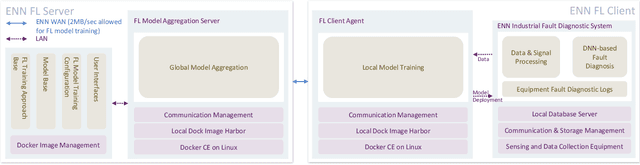

Artificial intelligence (AI)-empowered industrial fault diagnostics is important in ensuring the safe operation of industrial applications. Since complex industrial systems often involve multiple industrial plants (possibly belonging to different companies or subsidiaries) with sensitive data collected and stored in a distributed manner, collaborative fault diagnostic model training often needs to leverage federated learning (FL). As the scale of the industrial fault diagnostic models are often large and communication channels in such systems are often not exclusively used for FL model training, existing deployed FL model training frameworks cannot train such models efficiently across multiple institutions. In this paper, we report our experience developing and deploying the Federated Opportunistic Block Dropout (FEDOBD) approach for industrial fault diagnostic model training. By decomposing large-scale models into semantic blocks and enabling FL participants to opportunistically upload selected important blocks in a quantized manner, it significantly reduces the communication overhead while maintaining model performance. Since its deployment in ENN Group in February 2022, FEDOBD has served two coal chemical plants across two cities in China to build industrial fault prediction models. It helped the company reduce the training communication overhead by over 70% compared to its previous AI Engine, while maintaining model performance at over 85% test F1 score. To our knowledge, it is the first successfully deployed dropout-based FL approach.