 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Memory-Enhanced Improvement Heuristics for Flexible Job Shop Scheduling
Mar 03, 2026The rise of smart manufacturing under Industry 4.0 introduces mass customization and dynamic production, demanding more advanced and flexible scheduling techniques. The flexible job-shop scheduling problem (FJSP) has attracted significant attention due to its complex constraints and strong alignment with real-world production scenarios. Current deep reinforcement learning (DRL)-based approaches to FJSP predominantly employ constructive methods. While effective, they often fall short of reaching (near-)optimal solutions. In contrast, improvement-based methods iteratively explore the neighborhood of initial solutions and are more effective in approaching optimality. However, the flexible machine allocation in FJSP poses significant challenges to the application of this framework, including accurate state representation, effective policy learning, and efficient search strategies. To address these challenges, this paper proposes a Memory-enhanced Improvement Search framework with heterogeneous graph representation--MIStar. It employs a novel heterogeneous disjunctive graph that explicitly models the operation sequences on machines to accurately represent scheduling solutions. Moreover, a memoryenhanced heterogeneous graph neural network (MHGNN) is designed for feature extraction, leveraging historical trajectories to enhance the decision-making capability of the policy network. Finally, a parallel greedy search strategy is adopted to explore the solution space, enabling superior solutions with fewer iterations. Extensive experiments on synthetic data and public benchmarks demonstrate that MIStar significantly outperforms both traditional handcrafted improvement heuristics and state-of-the-art DRL-based constructive methods.
AgentIF-OneDay: A Task-level Instruction-Following Benchmark for General AI Agents in Daily Scenarios
Jan 28, 2026The capacity of AI agents to effectively handle tasks of increasing duration and complexity continues to grow, demonstrating exceptional performance in coding, deep research, and complex problem-solving evaluations. However, in daily scenarios, the perception of these advanced AI capabilities among general users remains limited. We argue that current evaluations prioritize increasing task difficulty without sufficiently addressing the diversity of agentic tasks necessary to cover the daily work, life, and learning activities of a broad demographic. To address this, we propose AgentIF-OneDay, aimed at determining whether general users can utilize natural language instructions and AI agents to complete a diverse array of daily tasks. These tasks require not only solving problems through dialogue but also understanding various attachment types and delivering tangible file-based results. The benchmark is structured around three user-centric categories: Open Workflow Execution, which assesses adherence to explicit and complex workflows; Latent Instruction, which requires agents to infer implicit instructions from attachments; and Iterative Refinement, which involves modifying or expanding upon ongoing work. We employ instance-level rubrics and a refined evaluation pipeline that aligns LLM-based verification with human judgment, achieving an 80.1% agreement rate using Gemini-3-Pro. AgentIF-OneDay comprises 104 tasks covering 767 scoring points. We benchmarked four leading general AI agents and found that agent products built based on APIs and ChatGPT agents based on agent RL remain in the first tier simultaneously. Leading LLM APIs and open-source models have internalized agentic capabilities, enabling AI application teams to develop cutting-edge Agent products.
Effective Code Membership Inference for Code Completion Models via Adversarial Prompts
Nov 19, 2025Membership inference attacks (MIAs) on code completion models offer an effective way to assess privacy risks by inferring whether a given code snippet was part of the training data. Existing black- and gray-box MIAs rely on expensive surrogate models or manually crafted heuristic rules, which limit their ability to capture the nuanced memorization patterns exhibited by over-parameterized code language models. To address these challenges, we propose AdvPrompt-MIA, a method specifically designed for code completion models, combining code-specific adversarial perturbations with deep learning. The core novelty of our method lies in designing a series of adversarial prompts that induce variations in the victim code model's output. By comparing these outputs with the ground-truth completion, we construct feature vectors to train a classifier that automatically distinguishes member from non-member samples. This design allows our method to capture richer memorization patterns and accurately infer training set membership. We conduct comprehensive evaluations on widely adopted models, such as Code Llama 7B, over the APPS and HumanEval benchmarks. The results show that our approach consistently outperforms state-of-the-art baselines, with AUC gains of up to 102%. In addition, our method exhibits strong transferability across different models and datasets, underscoring its practical utility and generalizability.
xbench: Tracking Agents Productivity Scaling with Profession-Aligned Real-World Evaluations
Jun 16, 2025


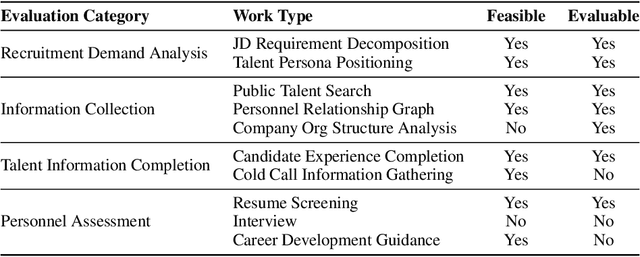
We introduce xbench, a dynamic, profession-aligned evaluation suite designed to bridge the gap between AI agent capabilities and real-world productivity. While existing benchmarks often focus on isolated technical skills, they may not accurately reflect the economic value agents deliver in professional settings. To address this, xbench targets commercially significant domains with evaluation tasks defined by industry professionals. Our framework creates metrics that strongly correlate with productivity value, enables prediction of Technology-Market Fit (TMF), and facilitates tracking of product capabilities over time. As our initial implementations, we present two benchmarks: Recruitment and Marketing. For Recruitment, we collect 50 tasks from real-world headhunting business scenarios to evaluate agents' abilities in company mapping, information retrieval, and talent sourcing. For Marketing, we assess agents' ability to match influencers with advertiser needs, evaluating their performance across 50 advertiser requirements using a curated pool of 836 candidate influencers. We present initial evaluation results for leading contemporary agents, establishing a baseline for these professional domains. Our continuously updated evalsets and evaluations are available at https://xbench.org.
Theoretical Investigation on Inductive Bias of Isolation Forest
May 19, 2025Isolation Forest (iForest) stands out as a widely-used unsupervised anomaly detector valued for its exceptional runtime efficiency and performance on large-scale tasks. Despite its widespread adoption, a theoretical foundation explaining iForest's success remains unclear. This paper theoretically investigates the conditions and extent of iForest's effectiveness by analyzing its inductive bias through the formulation of depth functions and growth processes. Since directly analyzing the depth function proves intractable due to iForest's random splitting mechanism, we model the growth process of iForest as a random walk, enabling us to derive the expected depth function using transition probabilities. Our case studies reveal key inductive biases: iForest exhibits lower sensitivity to central anomalies while demonstrating greater parameter adaptability compared to $k$-Nearest Neighbor anomaly detectors. Our study provides theoretical understanding of the effectiveness of iForest and establishes a foundation for further theoretical exploration.
Curriculum Abductive Learning
May 18, 2025Abductive Learning (ABL) integrates machine learning with logical reasoning in a loop: a learning model predicts symbolic concept labels from raw inputs, which are revised through abduction using domain knowledge and then fed back for retraining. However, due to the nondeterminism of abduction, the training process often suffers from instability, especially when the knowledge base is large and complex, resulting in a prohibitively large abduction space. While prior works focus on improving candidate selection within this space, they typically treat the knowledge base as a static black box. In this work, we propose Curriculum Abductive Learning (C-ABL), a method that explicitly leverages the internal structure of the knowledge base to address the ABL training challenges. C-ABL partitions the knowledge base into a sequence of sub-bases, progressively introduced during training. This reduces the abduction space throughout training and enables the model to incorporate logic in a stepwise, smooth way. Experiments across multiple tasks show that C-ABL outperforms previous ABL implementations, significantly improves training stability, convergence speed, and final accuracy, especially under complex knowledge setting.
GRAIN: Multi-Granular and Implicit Information Aggregation Graph Neural Network for Heterophilous Graphs
Apr 09, 2025



Graph neural networks (GNNs) have shown significant success in learning graph representations. However, recent studies reveal that GNNs often fail to outperform simple MLPs on heterophilous graph tasks, where connected nodes may differ in features or labels, challenging the homophily assumption. Existing methods addressing this issue often overlook the importance of information granularity and rarely consider implicit relationships between distant nodes. To overcome these limitations, we propose the Granular and Implicit Graph Network (GRAIN), a novel GNN model specifically designed for heterophilous graphs. GRAIN enhances node embeddings by aggregating multi-view information at various granularity levels and incorporating implicit data from distant, non-neighboring nodes. This approach effectively integrates local and global information, resulting in smoother, more accurate node representations. We also introduce an adaptive graph information aggregator that efficiently combines multi-granularity and implicit data, significantly improving node representation quality, as shown by experiments on 13 datasets covering varying homophily and heterophily. GRAIN consistently outperforms 12 state-of-the-art models, excelling on both homophilous and heterophilous graphs.
Enhancing High-Quality Code Generation in Large Language Models with Comparative Prefix-Tuning
Mar 12, 2025Large Language Models (LLMs) have been widely adopted in commercial code completion engines, significantly enhancing coding efficiency and productivity. However, LLMs may generate code with quality issues that violate coding standards and best practices, such as poor code style and maintainability, even when the code is functionally correct. This necessitates additional effort from developers to improve the code, potentially negating the efficiency gains provided by LLMs. To address this problem, we propose a novel comparative prefix-tuning method for controllable high-quality code generation. Our method introduces a single, property-specific prefix that is prepended to the activations of the LLM, serving as a lightweight alternative to fine-tuning. Unlike existing methods that require training multiple prefixes, our approach trains only one prefix and leverages pairs of high-quality and low-quality code samples, introducing a sequence-level ranking loss to guide the model's training. This comparative approach enables the model to better understand the differences between high-quality and low-quality code, focusing on aspects that impact code quality. Additionally, we design a data construction pipeline to collect and annotate pairs of high-quality and low-quality code, facilitating effective training. Extensive experiments on the Code Llama 7B model demonstrate that our method improves code quality by over 100% in certain task categories, while maintaining functional correctness. We also conduct ablation studies and generalization experiments, confirming the effectiveness of our method's components and its strong generalization capability.
An Efficient Diffusion-based Non-Autoregressive Solver for Traveling Salesman Problem
Jan 23, 2025



Recent advances in neural models have shown considerable promise in solving Traveling Salesman Problems (TSPs) without relying on much hand-crafted engineering. However, while non-autoregressive (NAR) approaches benefit from faster inference through parallelism, they typically deliver solutions of inferior quality compared to autoregressive ones. To enhance the solution quality while maintaining fast inference, we propose DEITSP, a diffusion model with efficient iterations tailored for TSP that operates in a NAR manner. Firstly, we introduce a one-step diffusion model that integrates the controlled discrete noise addition process with self-consistency enhancement, enabling optimal solution prediction through simultaneous denoising of multiple solutions. Secondly, we design a dual-modality graph transformer to bolster the extraction and fusion of features from node and edge modalities, while further accelerating the inference with fewer layers. Thirdly, we develop an efficient iterative strategy that alternates between adding and removing noise to improve exploration compared to previous diffusion methods. Additionally, we devise a scheduling framework to progressively refine the solution space by adjusting noise levels, facilitating a smooth search for optimal solutions. Extensive experiments on real-world and large-scale TSP instances demonstrate that DEITSP performs favorably against existing neural approaches in terms of solution quality, inference latency, and generalization ability. Our code is available at $\href{https://github.com/DEITSP/DEITSP}{https://github.com/DEITSP/DEITSP}$.
Efficient Rectification of Neuro-Symbolic Reasoning Inconsistencies by Abductive Reflection
Dec 11, 2024Neuro-Symbolic (NeSy) AI could be regarded as an analogy to human dual-process cognition, modeling the intuitive System 1 with neural networks and the algorithmic System 2 with symbolic reasoning. However, for complex learning targets, NeSy systems often generate outputs inconsistent with domain knowledge and it is challenging to rectify them. Inspired by the human Cognitive Reflection, which promptly detects errors in our intuitive response and revises them by invoking the System 2 reasoning, we propose to improve NeSy systems by introducing Abductive Reflection (ABL-Refl) based on the Abductive Learning (ABL) framework. ABL-Refl leverages domain knowledge to abduce a reflection vector during training, which can then flag potential errors in the neural network outputs and invoke abduction to rectify them and generate consistent outputs during inference. ABL-Refl is highly efficient in contrast to previous ABL implementations. Experiments show that ABL-Refl outperforms state-of-the-art NeSy methods, achieving excellent accuracy with fewer training resources and enhanced efficiency.