 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeDMRA: Federated Incremental Learning with Dynamic Memory Replay Allocation
Mar 30, 2026In federated healthcare systems, Federated Class-Incremental Learning (FCIL) has emerged as a key paradigm, enabling continuous adaptive model learning among distributed clients while safeguarding data privacy. However, in practical applications, data across agent nodes within the distributed framework often exhibits non-independent and identically distributed (non-IID) characteristics, rendering traditional continual learning methods inapplicable. To address these challenges, this paper covers more comprehensive incremental task scenarios and proposes a dynamic memory allocation strategy for exemplar storage based on the data replay mechanism. This strategy fully taps into the inherent potential of data heterogeneity, while taking into account the performance fairness of all participating clients, thereby establishing a balanced and adaptive solution to mitigate catastrophic forgetting. Unlike the fixed allocation of client exemplar memory, the proposed scheme emphasizes the rational allocation of limited storage resources among clients to improve model performance. Furthermore, extensive experiments are conducted on three medical image datasets, and the results demonstrate significant performance improvements compared to existing baseline models.
Human Video Generation from a Single Image with 3D Pose and View Control
Feb 24, 2026Recent diffusion methods have made significant progress in generating videos from single images due to their powerful visual generation capabilities. However, challenges persist in image-to-video synthesis, particularly in human video generation, where inferring view-consistent, motion-dependent clothing wrinkles from a single image remains a formidable problem. In this paper, we present Human Video Generation in 4D (HVG), a latent video diffusion model capable of generating high-quality, multi-view, spatiotemporally coherent human videos from a single image with 3D pose and view control. HVG achieves this through three key designs: (i) Articulated Pose Modulation, which captures the anatomical relationships of 3D joints via a novel dual-dimensional bone map and resolves self-occlusions across views by introducing 3D information; (ii) View and Temporal Alignment, which ensures multi-view consistency and alignment between a reference image and pose sequences for frame-to-frame stability; and (iii) Progressive Spatio-Temporal Sampling with temporal alignment to maintain smooth transitions in long multi-view animations. Extensive experiments on image-to-video tasks demonstrate that HVG outperforms existing methods in generating high-quality 4D human videos from diverse human images and pose inputs.
Effective Code Membership Inference for Code Completion Models via Adversarial Prompts
Nov 19, 2025Membership inference attacks (MIAs) on code completion models offer an effective way to assess privacy risks by inferring whether a given code snippet was part of the training data. Existing black- and gray-box MIAs rely on expensive surrogate models or manually crafted heuristic rules, which limit their ability to capture the nuanced memorization patterns exhibited by over-parameterized code language models. To address these challenges, we propose AdvPrompt-MIA, a method specifically designed for code completion models, combining code-specific adversarial perturbations with deep learning. The core novelty of our method lies in designing a series of adversarial prompts that induce variations in the victim code model's output. By comparing these outputs with the ground-truth completion, we construct feature vectors to train a classifier that automatically distinguishes member from non-member samples. This design allows our method to capture richer memorization patterns and accurately infer training set membership. We conduct comprehensive evaluations on widely adopted models, such as Code Llama 7B, over the APPS and HumanEval benchmarks. The results show that our approach consistently outperforms state-of-the-art baselines, with AUC gains of up to 102%. In addition, our method exhibits strong transferability across different models and datasets, underscoring its practical utility and generalizability.
Enhancing High-Quality Code Generation in Large Language Models with Comparative Prefix-Tuning
Mar 12, 2025Large Language Models (LLMs) have been widely adopted in commercial code completion engines, significantly enhancing coding efficiency and productivity. However, LLMs may generate code with quality issues that violate coding standards and best practices, such as poor code style and maintainability, even when the code is functionally correct. This necessitates additional effort from developers to improve the code, potentially negating the efficiency gains provided by LLMs. To address this problem, we propose a novel comparative prefix-tuning method for controllable high-quality code generation. Our method introduces a single, property-specific prefix that is prepended to the activations of the LLM, serving as a lightweight alternative to fine-tuning. Unlike existing methods that require training multiple prefixes, our approach trains only one prefix and leverages pairs of high-quality and low-quality code samples, introducing a sequence-level ranking loss to guide the model's training. This comparative approach enables the model to better understand the differences between high-quality and low-quality code, focusing on aspects that impact code quality. Additionally, we design a data construction pipeline to collect and annotate pairs of high-quality and low-quality code, facilitating effective training. Extensive experiments on the Code Llama 7B model demonstrate that our method improves code quality by over 100% in certain task categories, while maintaining functional correctness. We also conduct ablation studies and generalization experiments, confirming the effectiveness of our method's components and its strong generalization capability.
A Survey on Wi-Fi Sensing Generalizability: Taxonomy, Techniques, Datasets, and Future Research Prospects
Mar 11, 2025Wi-Fi sensing has emerged as a transformative technology that leverages ubiquitous wireless signals to enable a variety of applications ranging from activity and gesture recognition to indoor localization and health monitoring. However, the inherent dependency of Wi-Fi signals on environmental conditions introduces significant generalization challenges,variations in surroundings, human positions, and orientations often lead to inconsistent signal features, impeding robust action recognition. In this survey, we review over 200 studies on Wi-Fi sensing generalization, categorizing them along the entire sensing pipeline: device deployment, signal processing, feature learning, and model deployment. We systematically analyze state-of-the-art techniques, which are employed to mitigate the adverse effects of environmental variability. Moreover, we provide a comprehensive overview of open-source datasets such as Widar3.0, XRF55, and XRFv2, highlighting their unique characteristics and applicability for multimodal fusion and cross-modal tasks. Finally, we discuss emerging research directions, such as multimodal approaches and the integration of large language models,to inspire future advancements in this rapidly evolving field. Our survey aims to serve as a valuable resource for researchers, offering insights into current methodologies, available datasets, and promising avenues for further investigation.
WiDistill: Distilling Large-scale Wi-Fi Datasets with Trajectory Matching
Oct 05, 2024Wi-Fi based human activity recognition is a technology with immense potential in home automation, advanced caregiving, and enhanced security systems. It can distinguish human activity in environments with poor lighting and obstructions. However, most current Wi-Fi based human activity recognition methods are data-driven, leading to a continuous increase in the size of datasets. This results in a significant increase in the resources and time required to store and utilize these datasets. To address this issue, we propose WiDistill, a large-scale Wi-Fi datasets distillation method. WiDistill improves the distilled dataset by aligning the parameter trajectories of the distilled data with the recorded expert trajectories. WiDistill significantly reduces the need for the original large-scale Wi-Fi datasets and allows for faster training of models that approximate the performance of the original network, while also demonstrating robust performance in cross-network environments. Extensive experiments on the Widar3.0, XRF55, and MM-Fi datasets demonstrate that WiDistill outperforms other methods. The code can be found in https://github.com/the-sky001/WiDistill.
Towards 4D Human Video Stylization
Dec 07, 2023



We present a first step towards 4D (3D and time) human video stylization, which addresses style transfer, novel view synthesis and human animation within a unified framework. While numerous video stylization methods have been developed, they are often restricted to rendering images in specific viewpoints of the input video, lacking the capability to generalize to novel views and novel poses in dynamic scenes. To overcome these limitations, we leverage Neural Radiance Fields (NeRFs) to represent videos, conducting stylization in the rendered feature space. Our innovative approach involves the simultaneous representation of both the human subject and the surrounding scene using two NeRFs. This dual representation facilitates the animation of human subjects across various poses and novel viewpoints. Specifically, we introduce a novel geometry-guided tri-plane representation, significantly enhancing feature representation robustness compared to direct tri-plane optimization. Following the video reconstruction, stylization is performed within the NeRFs' rendered feature space. Extensive experiments demonstrate that the proposed method strikes a superior balance between stylized textures and temporal coherence, surpassing existing approaches. Furthermore, our framework uniquely extends its capabilities to accommodate novel poses and viewpoints, making it a versatile tool for creative human video stylization.
AMC-Net: An Effective Network for Automatic Modulation Classification
Apr 02, 2023Automatic modulation classification (AMC) is a crucial stage in the spectrum management, signal monitoring, and control of wireless communication systems. The accurate classification of the modulation format plays a vital role in the subsequent decoding of the transmitted data. End-to-end deep learning methods have been recently applied to AMC, outperforming traditional feature engineering techniques. However, AMC still has limitations in low signal-to-noise ratio (SNR) environments. To address the drawback, we propose a novel AMC-Net that improves recognition by denoising the input signal in the frequency domain while performing multi-scale and effective feature extraction. Experiments on two representative datasets demonstrate that our model performs better in efficiency and effectiveness than the most current methods.
Pixel2ISDF: Implicit Signed Distance Fields based Human Body Model from Multi-view and Multi-pose Images
Dec 06, 2022



In this report, we focus on reconstructing clothed humans in the canonical space given multiple views and poses of a human as the input. To achieve this, we utilize the geometric prior of the SMPLX model in the canonical space to learn the implicit representation for geometry reconstruction. Based on the observation that the topology between the posed mesh and the mesh in the canonical space are consistent, we propose to learn latent codes on the posed mesh by leveraging multiple input images and then assign the latent codes to the mesh in the canonical space. Specifically, we first leverage normal and geometry networks to extract the feature vector for each vertex on the SMPLX mesh. Normal maps are adopted for better generalization to unseen images compared to 2D images. Then, features for each vertex on the posed mesh from multiple images are integrated by MLPs. The integrated features acting as the latent code are anchored to the SMPLX mesh in the canonical space. Finally, latent code for each 3D point is extracted and utilized to calculate the SDF. Our work for reconstructing the human shape on canonical pose achieves 3rd performance on WCPA MVP-Human Body Challenge.
Animatable Neural Radiance Fields from Monocular RGB-D
Apr 04, 2022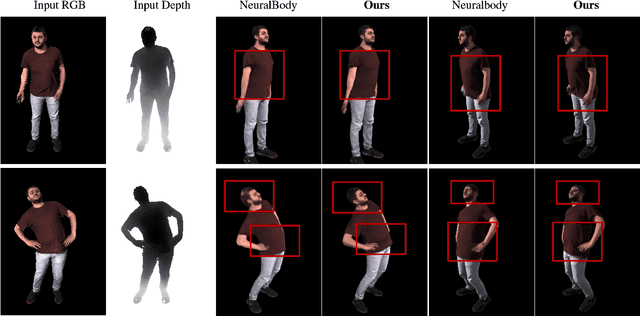
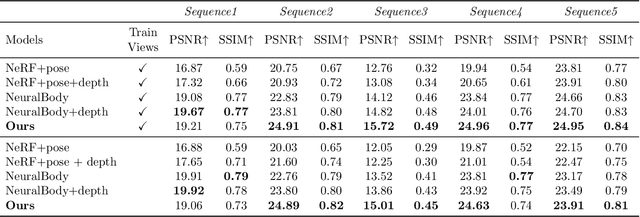
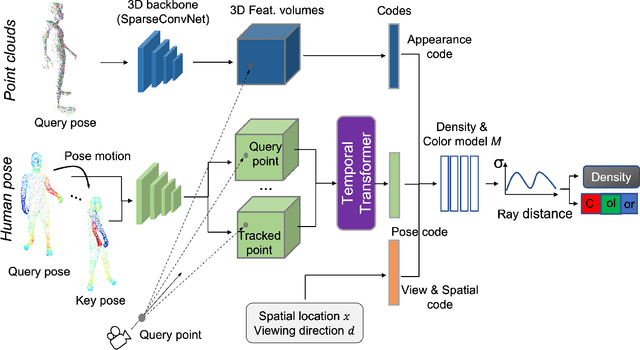

This paper aims at representing animatable photo-realistic humans under novel views and poses. Recent work has shown significant progress with dynamic scenes by exploring shared canonical neural radiance fields. However learning a user-controlled model for novel poses remains a challenging task. To tackle this problem, we introduce a novel method to integrate observations across frames and encode the appearance at each individual frame by utilizing the human pose that models the body shape and point clouds which cover partial part of the human as the input. Specifically, our method simultaneously learns a shared set of latent codes anchored to the human pose among frames, and learns an appearance-dependent code anchored to incomplete point clouds generated by monocular RGB-D at each frame. A human pose-based code models the shape of the performer whereas a point cloud based code predicts details and reasons about missing structures at the unseen poses. To further recover non-visible regions in query frames, we utilize a temporal transformer to integrate features of points in query frames and tracked body points from automatically-selected key frames. Experiments on various sequences of humans in motion show that our method significantly outperforms existing works under unseen poses and novel views given monocular RGB-D videos as input.