 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-Routed Visual Question Reasoning: Challenges for Deep Representation Embedding
Dec 14, 2020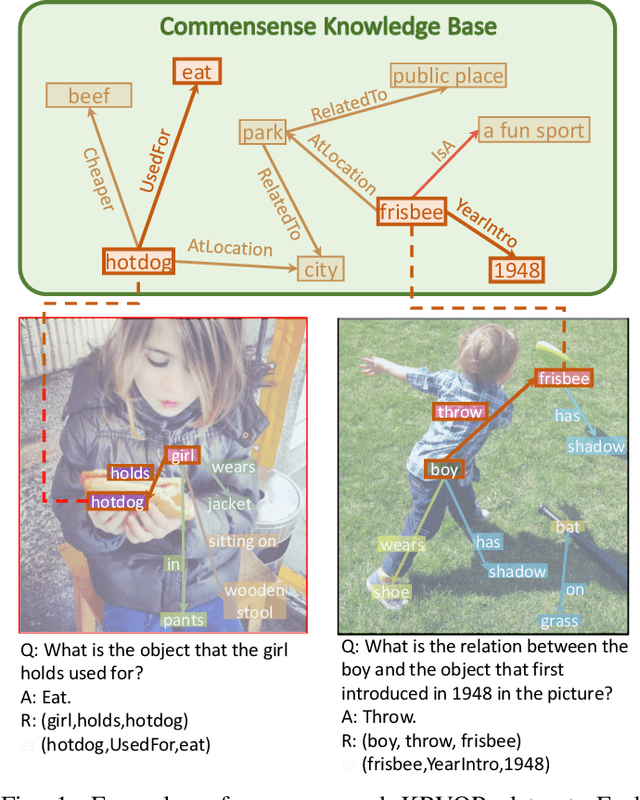
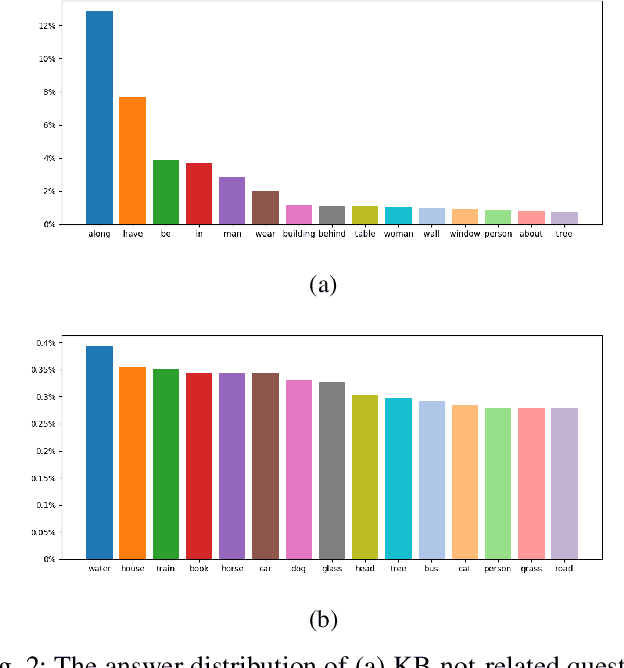
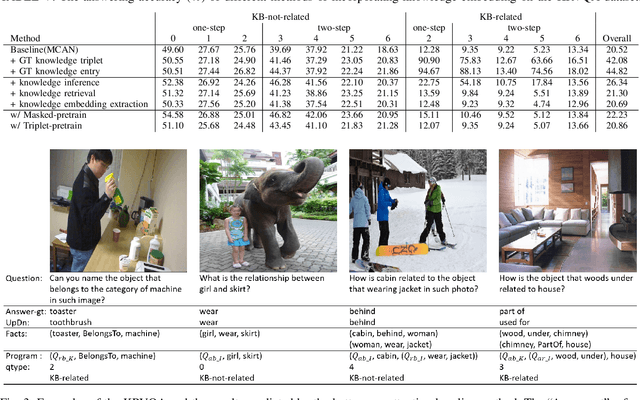
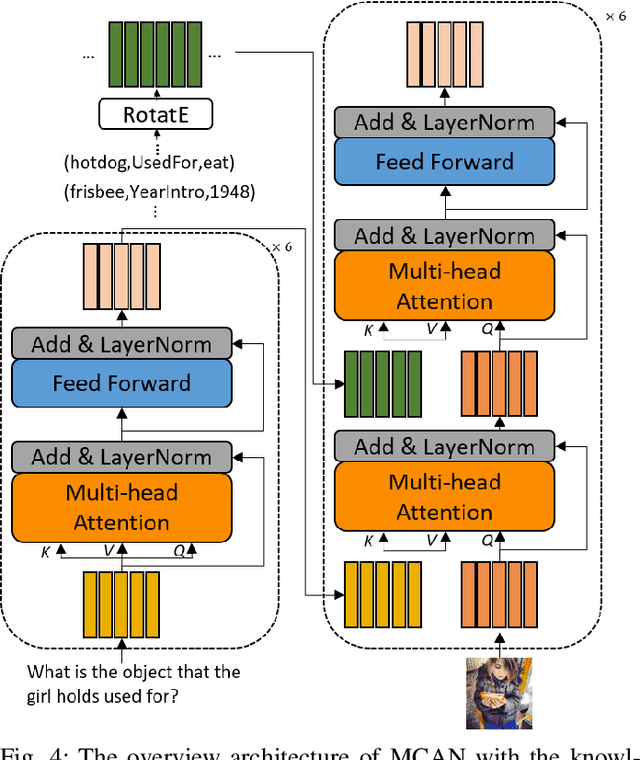
Though beneficial for encouraging the Visual Question Answering (VQA) models to discover the underlying knowledge by exploiting the input-output correlation beyond image and text contexts, the existing knowledge VQA datasets are mostly annotated in a crowdsource way, e.g., collecting questions and external reasons from different users via the internet. In addition to the challenge of knowledge reasoning, how to deal with the annotator bias also remains unsolved, which often leads to superficial over-fitted correlations between questions and answers. To address this issue, we propose a novel dataset named Knowledge-Routed Visual Question Reasoning for VQA model evaluation. Considering that a desirable VQA model should correctly perceive the image context, understand the question, and incorporate its learned knowledge, our proposed dataset aims to cutoff the shortcut learning exploited by the current deep embedding models and push the research boundary of the knowledge-based visual question reasoning. Specifically, we generate the question-answer pair based on both the Visual Genome scene graph and an external knowledge base with controlled programs to disentangle the knowledge from other biases. The programs can select one or two triplets from the scene graph or knowledge base to push multi-step reasoning, avoid answer ambiguity, and balanced the answer distribution. In contrast to the existing VQA datasets, we further imply the following two major constraints on the programs to incorporate knowledge reasoning: i) multiple knowledge triplets can be related to the question, but only one knowledge relates to the image object. This can enforce the VQA model to correctly perceive the image instead of guessing the knowledge based on the given question solely; ii) all questions are based on different knowledge, but the candidate answers are the same for both the training and test sets.
Cross-Modal Collaborative Representation Learning and a Large-Scale RGBT Benchmark for Crowd Counting
Dec 08, 2020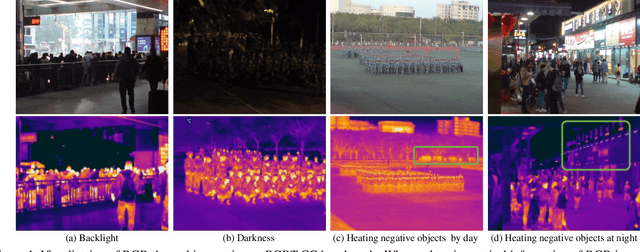
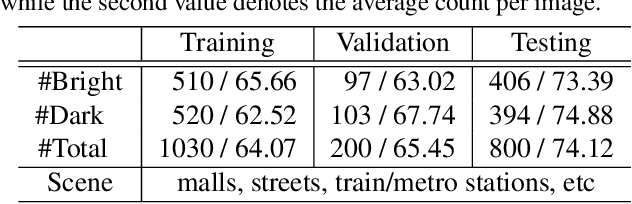
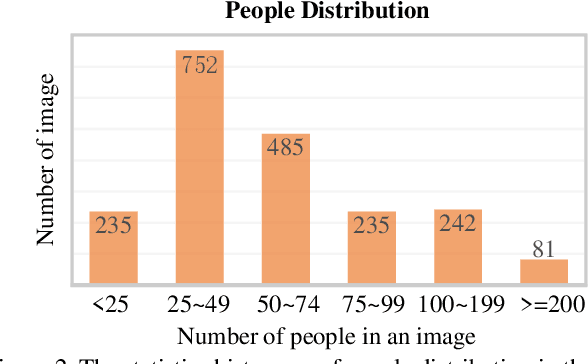
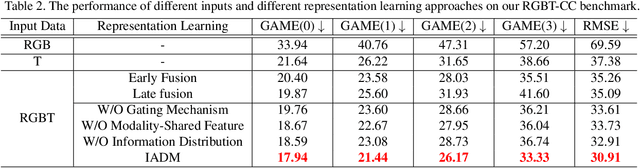
Crowd counting is a fundamental yet challenging problem, which desires rich information to generate pixel-wise crowd density maps. However, most previous methods only utilized the limited information of RGB images and may fail to discover the potential pedestrians in unconstrained environments. In this work, we find that incorporating optical and thermal information can greatly help to recognize pedestrians. To promote future researches in this field, we introduce a large-scale RGBT Crowd Counting (RGBT-CC) benchmark, which contains 2,030 pairs of RGB-thermal images with 138,389 annotated people. Furthermore, to facilitate the multimodal crowd counting, we propose a cross-modal collaborative representation learning framework, which consists of multiple modality-specific branches, a modality-shared branch, and an Information Aggregation-Distribution Module (IADM) to fully capture the complementary information of different modalities. Specifically, our IADM incorporates two collaborative information transfer components to dynamically enhance the modality-shared and modality-specific representations with a dual information propagation mechanism. Extensive experiments conducted on the RGBT-CC benchmark demonstrate the effectiveness of our framework for RGBT crowd counting. Moreover, the proposed approach is universal for multimodal crowd counting and is also capable to achieve superior performance on the ShanghaiTechRGBD dataset.
Continuous Transition: Improving Sample Efficiency for Continuous Control Problems via MixUp
Nov 30, 2020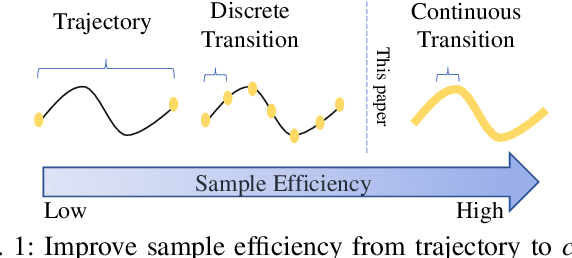
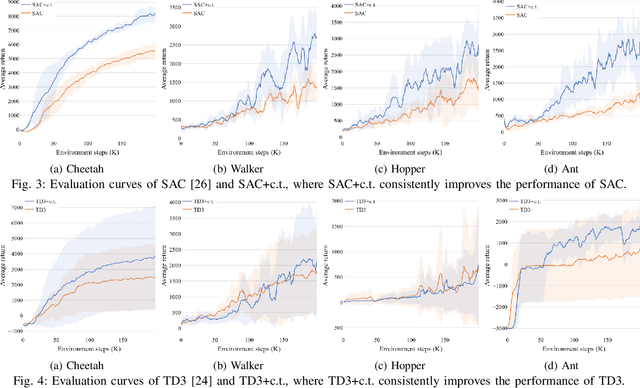
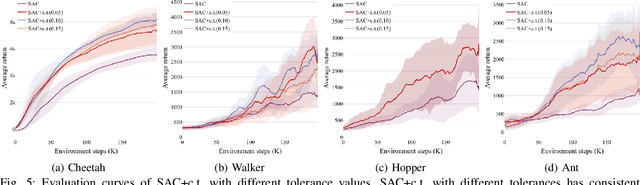
Although deep reinforcement learning~(RL) has been successfully applied to a variety of robotic control tasks, it's still challenging to apply it to real-world tasks, due to the poor sample efficiency. Attempting to overcome this shortcoming, several works focus on reusing the collected trajectory data during the training by decomposing them into a set of policy-irrelevant discrete transitions. However, their improvements are somewhat marginal since i) the amount of the transitions is usually small, and ii) the value assignment only happens in the joint states. To address these issues, this paper introduces a concise yet powerful method to construct \textit{Continuous Transition}, which exploits the trajectory information by exploiting the potential transitions along the trajectory. Specifically, we propose to synthesize new transitions for training by linearly interpolating the conjunctive transitions. To keep the constructed transitions authentic, we also develop a discriminator to guide the construction process automatically. Extensive experiments demonstrate that our proposed method achieves a significant improvement in sample efficiency on various complex continuous robotic control problems in MuJoCo and outperforms the advanced model-based / model-free RL methods.
Auto-Panoptic: Cooperative Multi-Component Architecture Search for Panoptic Segmentation
Oct 30, 2020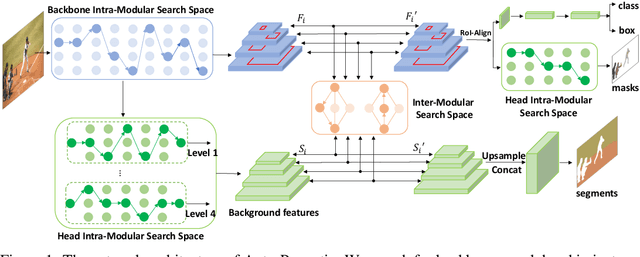

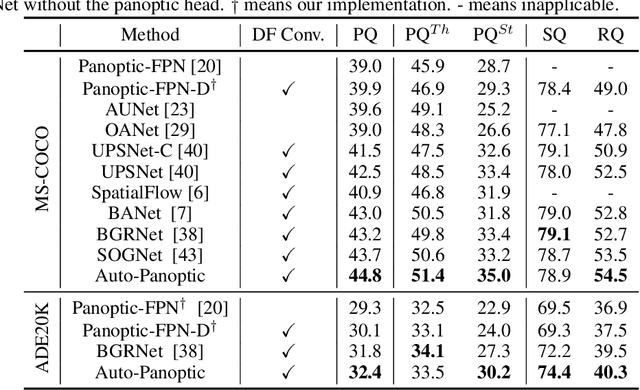
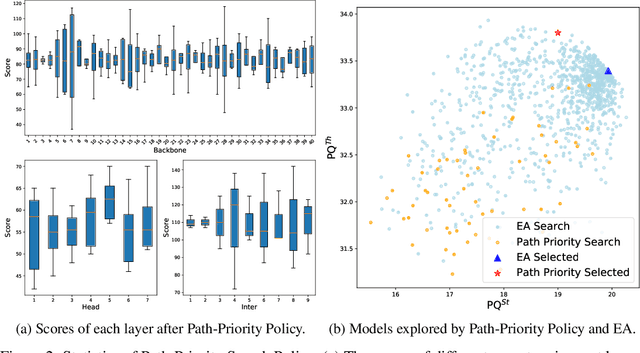
Panoptic segmentation is posed as a new popular test-bed for the state-of-the-art holistic scene understanding methods with the requirement of simultaneously segmenting both foreground things and background stuff. The state-of-the-art panoptic segmentation network exhibits high structural complexity in different network components, i.e. backbone, proposal-based foreground branch, segmentation-based background branch, and feature fusion module across branches, which heavily relies on expert knowledge and tedious trials. In this work, we propose an efficient, cooperative and highly automated framework to simultaneously search for all main components including backbone, segmentation branches, and feature fusion module in a unified panoptic segmentation pipeline based on the prevailing one-shot Network Architecture Search (NAS) paradigm. Notably, we extend the common single-task NAS into the multi-component scenario by taking the advantage of the newly proposed intra-modular search space and problem-oriented inter-modular search space, which helps us to obtain an optimal network architecture that not only performs well in both instance segmentation and semantic segmentation tasks but also be aware of the reciprocal relations between foreground things and background stuff classes. To relieve the vast computation burden incurred by applying NAS to complicated network architectures, we present a novel path-priority greedy search policy to find a robust, transferrable architecture with significantly reduced searching overhead. Our searched architecture, namely Auto-Panoptic, achieves the new state-of-the-art on the challenging COCO and ADE20K benchmarks. Moreover, extensive experiments are conducted to demonstrate the effectiveness of path-priority policy and transferability of Auto-Panoptic across different datasets. Codes and models are available at: https://github.com/Jacobew/AutoPanoptic.
A Hamiltonian Monte Carlo Method for Probabilistic Adversarial Attack and Learning
Oct 15, 2020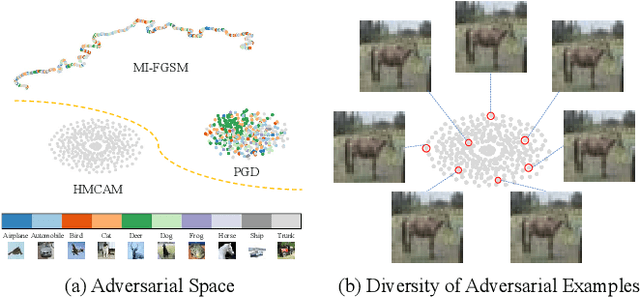

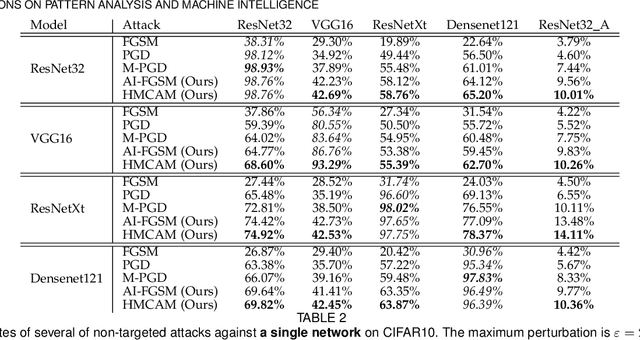
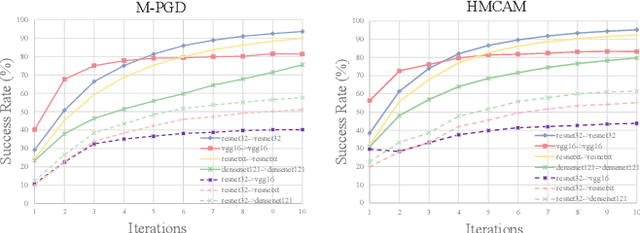
Although deep convolutional neural networks (CNNs) have demonstrated remarkable performance on multiple computer vision tasks, researches on adversarial learning have shown that deep models are vulnerable to adversarial examples, which are crafted by adding visually imperceptible perturbations to the input images. Most of the existing adversarial attack methods only create a single adversarial example for the input, which just gives a glimpse of the underlying data manifold of adversarial examples. An attractive solution is to explore the solution space of the adversarial examples and generate a diverse bunch of them, which could potentially improve the robustness of real-world systems and help prevent severe security threats and vulnerabilities. In this paper, we present an effective method, called Hamiltonian Monte Carlo with Accumulated Momentum (HMCAM), aiming to generate a sequence of adversarial examples. To improve the efficiency of HMC, we propose a new regime to automatically control the length of trajectories, which allows the algorithm to move with adaptive step sizes along the search direction at different positions. Moreover, we revisit the reason for high computational cost of adversarial training under the view of MCMC and design a new generative method called Contrastive Adversarial Training (CAT), which approaches equilibrium distribution of adversarial examples with only few iterations by building from small modifications of the standard Contrastive Divergence (CD) and achieve a trade-off between efficiency and accuracy. Both quantitative and qualitative analysis on several natural image datasets and practical systems have confirmed the superiority of the proposed algorithm.
Semantically-Aligned Universal Tree-Structured Solver for Math Word Problems
Oct 14, 2020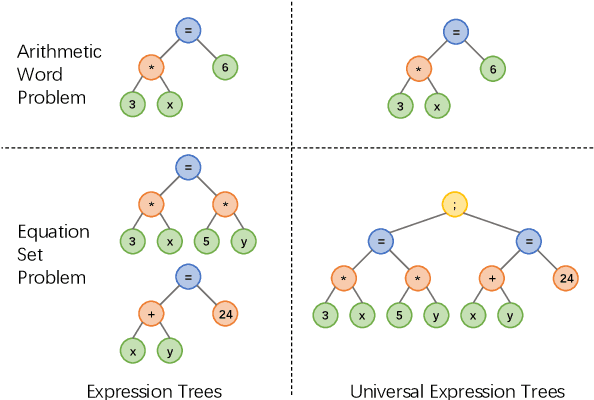

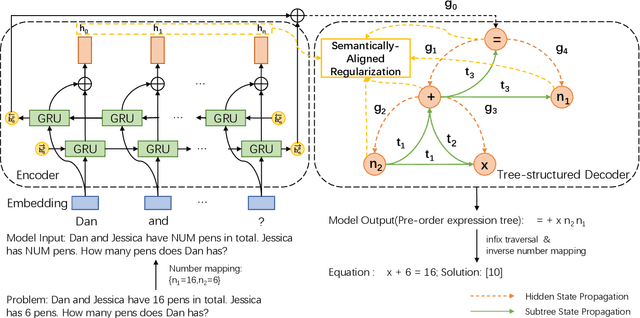
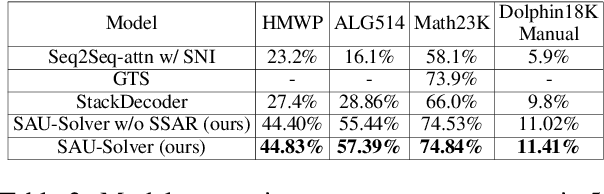
A practical automatic textual math word problems (MWPs) solver should be able to solve various textual MWPs while most existing works only focused on one-unknown linear MWPs. Herein, we propose a simple but efficient method called Universal Expression Tree (UET) to make the first attempt to represent the equations of various MWPs uniformly. Then a semantically-aligned universal tree-structured solver (SAU-Solver) based on an encoder-decoder framework is proposed to resolve multiple types of MWPs in a unified model, benefiting from our UET representation. Our SAU-Solver generates a universal expression tree explicitly by deciding which symbol to generate according to the generated symbols' semantic meanings like human solving MWPs. Besides, our SAU-Solver also includes a novel subtree-level semanticallyaligned regularization to further enforce the semantic constraints and rationality of the generated expression tree by aligning with the contextual information. Finally, to validate the universality of our solver and extend the research boundary of MWPs, we introduce a new challenging Hybrid Math Word Problems dataset (HMWP), consisting of three types of MWPs. Experimental results on several MWPs datasets show that our model can solve universal types of MWPs and outperforms several state-of-the-art models.
GRADE: Automatic Graph-Enhanced Coherence Metric for Evaluating Open-Domain Dialogue Systems
Oct 08, 2020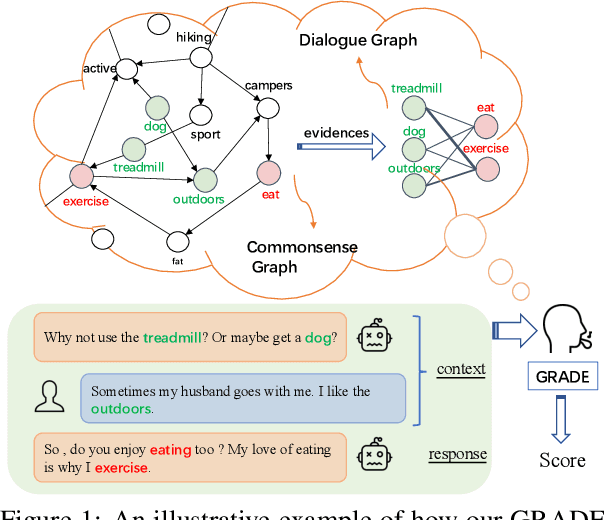
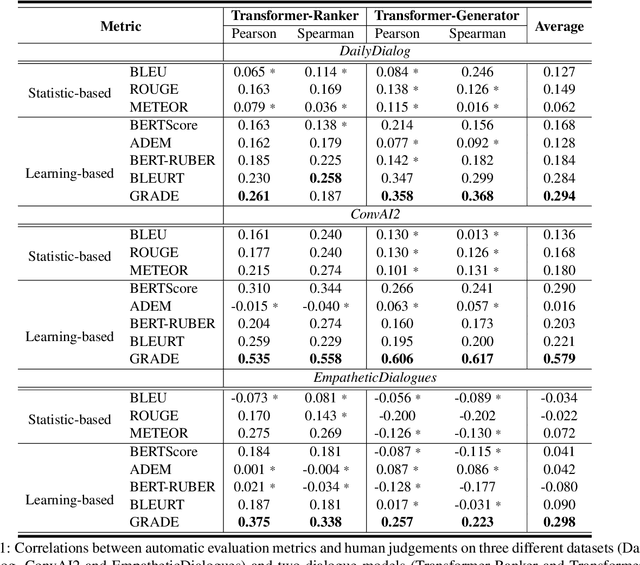
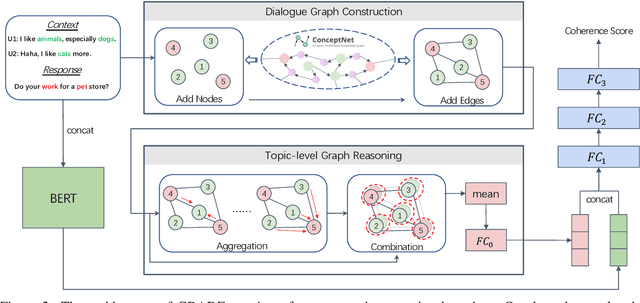
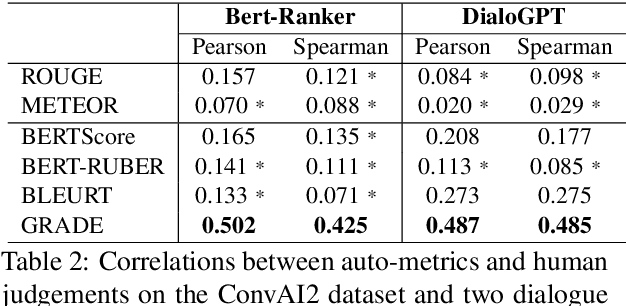
Automatically evaluating dialogue coherence is a challenging but high-demand ability for developing high-quality open-domain dialogue systems. However, current evaluation metrics consider only surface features or utterance-level semantics, without explicitly considering the fine-grained topic transition dynamics of dialogue flows. Here, we first consider that the graph structure constituted with topics in a dialogue can accurately depict the underlying communication logic, which is a more natural way to produce persuasive metrics. Capitalized on the topic-level dialogue graph, we propose a new evaluation metric GRADE, which stands for Graph-enhanced Representations for Automatic Dialogue Evaluation. Specifically, GRADE incorporates both coarse-grained utterance-level contextualized representations and fine-grained topic-level graph representations to evaluate dialogue coherence. The graph representations are obtained by reasoning over topic-level dialogue graphs enhanced with the evidence from a commonsense graph, including k-hop neighboring representations and hop-attention weights. Experimental results show that our GRADE significantly outperforms other state-of-the-art metrics on measuring diverse dialogue models in terms of the Pearson and Spearman correlations with human judgements. Besides, we release a new large-scale human evaluation benchmark to facilitate future research on automatic metrics.
AIM 2020 Challenge on Real Image Super-Resolution: Methods and Results
Sep 25, 2020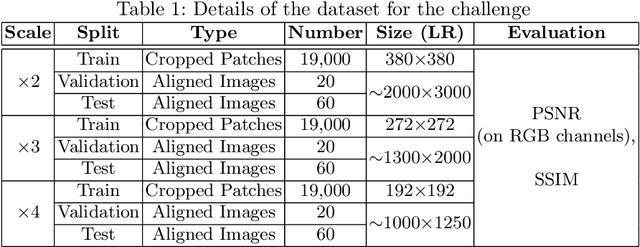
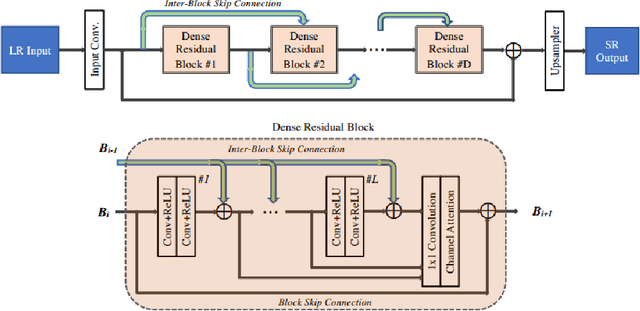
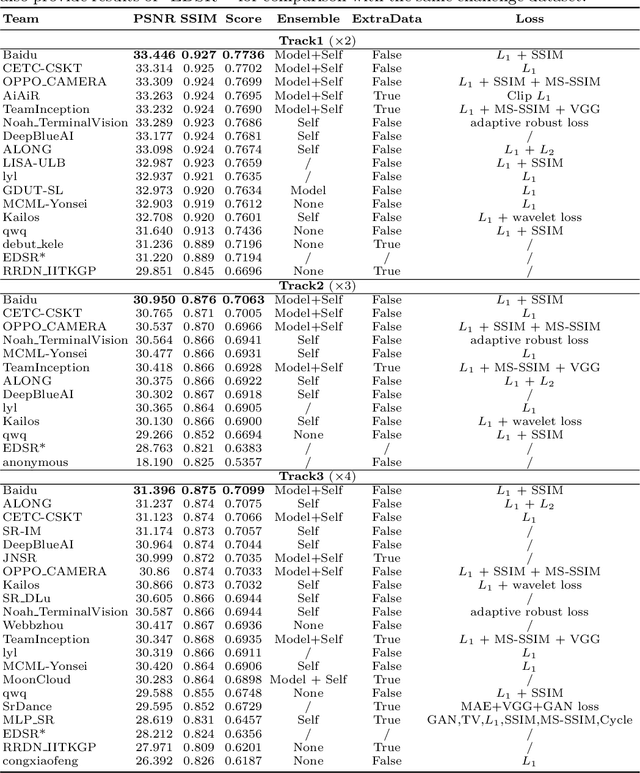
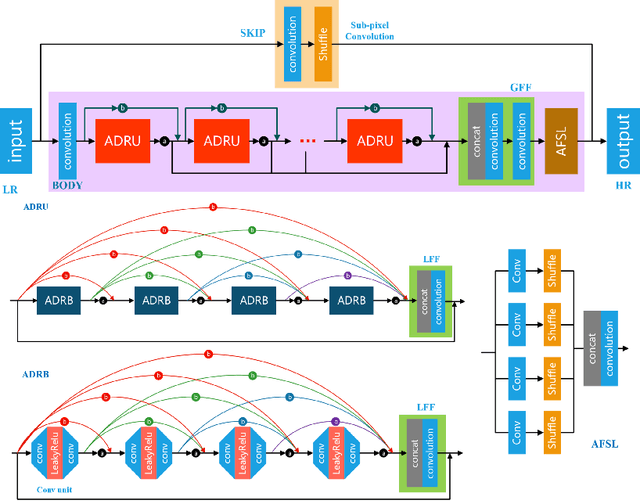
This paper introduces the real image Super-Resolution (SR) challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2020. This challenge involves three tracks to super-resolve an input image for $\times$2, $\times$3 and $\times$4 scaling factors, respectively. The goal is to attract more attention to realistic image degradation for the SR task, which is much more complicated and challenging, and contributes to real-world image super-resolution applications. 452 participants were registered for three tracks in total, and 24 teams submitted their results. They gauge the state-of-the-art approaches for real image SR in terms of PSNR and SSIM.
Knowledge-Guided Multi-Label Few-Shot Learning for General Image Recognition
Sep 20, 2020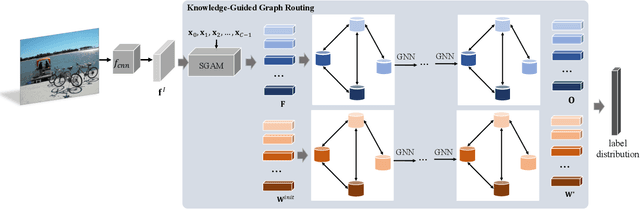
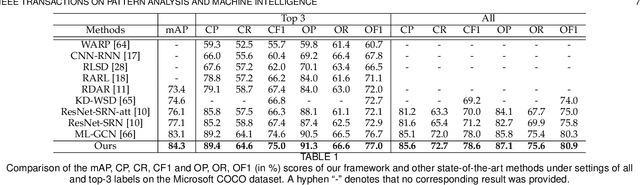
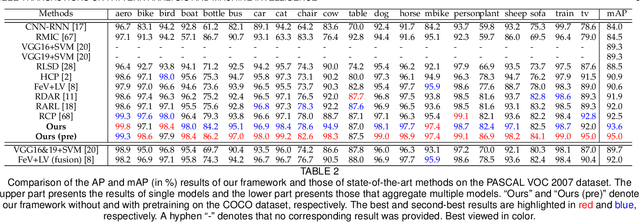
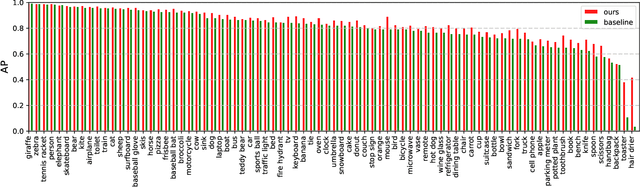
Recognizing multiple labels of an image is a practical yet challenging task, and remarkable progress has been achieved by searching for semantic regions and exploiting label dependencies. However, current works utilize RNN/LSTM to implicitly capture sequential region/label dependencies, which cannot fully explore mutual interactions among the semantic regions/labels and do not explicitly integrate label co-occurrences. In addition, these works require large amounts of training samples for each category, and they are unable to generalize to novel categories with limited samples. To address these issues, we propose a knowledge-guided graph routing (KGGR) framework, which unifies prior knowledge of statistical label correlations with deep neural networks. The framework exploits prior knowledge to guide adaptive information propagation among different categories to facilitate multi-label analysis and reduce the dependency of training samples. Specifically, it first builds a structured knowledge graph to correlate different labels based on statistical label co-occurrence. Then, it introduces the label semantics to guide learning semantic-specific features to initialize the graph, and it exploits a graph propagation network to explore graph node interactions, enabling learning contextualized image feature representations. Moreover, we initialize each graph node with the classifier weights for the corresponding label and apply another propagation network to transfer node messages through the graph. In this way, it can facilitate exploiting the information of correlated labels to help train better classifiers. We conduct extensive experiments on the traditional multi-label image recognition (MLR) and multi-label few-shot learning (ML-FSL) tasks and show that our KGGR framework outperforms the current state-of-the-art methods by sizable margins on the public benchmarks.
Collaborative Training between Region Proposal Localization and Classification for Domain Adaptive Object Detection
Sep 18, 2020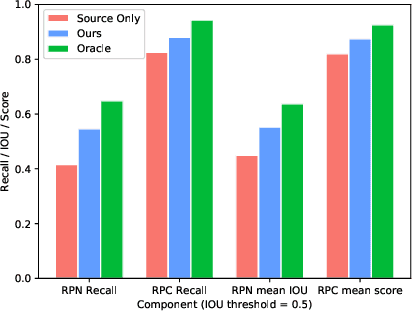

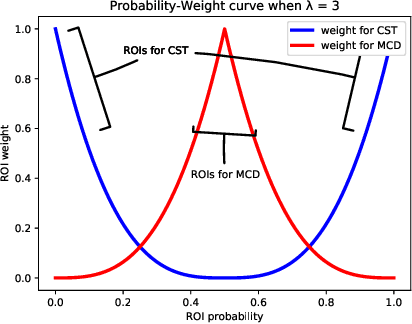

Object detectors are usually trained with large amount of labeled data, which is expensive and labor-intensive. Pre-trained detectors applied to unlabeled dataset always suffer from the difference of dataset distribution, also called domain shift. Domain adaptation for object detection tries to adapt the detector from labeled datasets to unlabeled ones for better performance. In this paper, we are the first to reveal that the region proposal network (RPN) and region proposal classifier~(RPC) in the endemic two-stage detectors (e.g., Faster RCNN) demonstrate significantly different transferability when facing large domain gap. The region classifier shows preferable performance but is limited without RPN's high-quality proposals while simple alignment in the backbone network is not effective enough for RPN adaptation. We delve into the consistency and the difference of RPN and RPC, treat them individually and leverage high-confidence output of one as mutual guidance to train the other. Moreover, the samples with low-confidence are used for discrepancy calculation between RPN and RPC and minimax optimization. Extensive experimental results on various scenarios have demonstrated the effectiveness of our proposed method in both domain-adaptive region proposal generation and object detection. Code is available at https://github.com/GanlongZhao/CST_DA_detection.