 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCET2: Modelling Topic Transitions for Coherent and Engaging Knowledge-Grounded Conversations
Mar 04, 2024



Knowledge-grounded dialogue systems aim to generate coherent and engaging responses based on the dialogue contexts and selected external knowledge. Previous knowledge selection methods tend to rely too heavily on the dialogue contexts or over-emphasize the new information in the selected knowledge, resulting in the selection of repetitious or incongruous knowledge and further generating repetitive or incoherent responses, as the generation of the response depends on the chosen knowledge. To address these shortcomings, we introduce a Coherent and Engaging Topic Transition (CET2) framework to model topic transitions for selecting knowledge that is coherent to the context of the conversations while providing adequate knowledge diversity for topic development. Our CET2 framework considers multiple factors for knowledge selection, including valid transition logic from dialogue contexts to the following topics and systematic comparisons between available knowledge candidates. Extensive experiments on two public benchmarks demonstrate the superiority and the better generalization ability of CET2 on knowledge selection. This is due to our well-designed transition features and comparative knowledge selection strategy, which are more transferable to conversations about unseen topics. Analysis of fine-grained knowledge selection accuracy also shows that CET2 can better balance topic entailment (contextual coherence) and development (knowledge diversity) in dialogue than existing approaches.
CorefDiffs: Co-referential and Differential Knowledge Flow in Document Grounded Conversations
Oct 05, 2022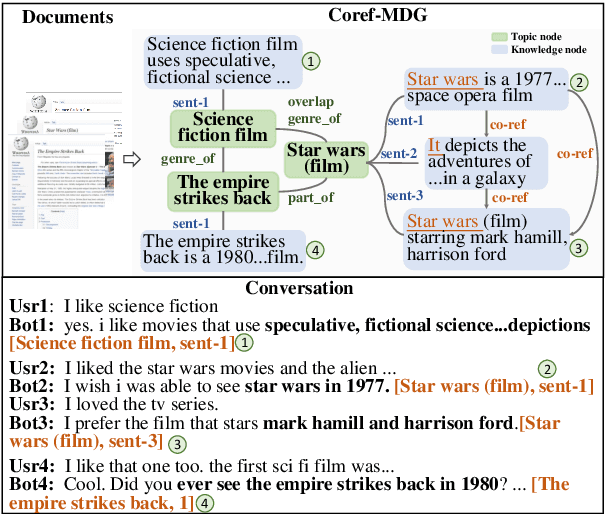

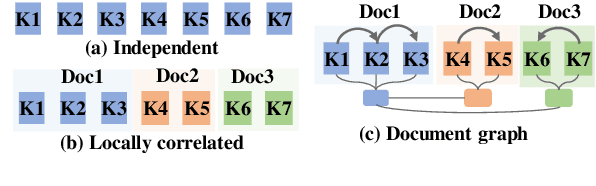
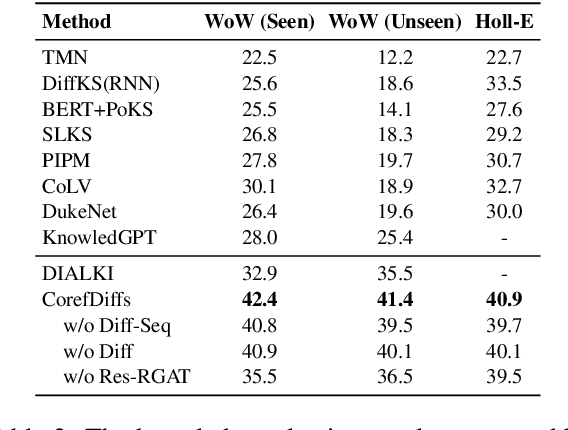
Knowledge-grounded dialog systems need to incorporate smooth transitions among knowledge selected for generating responses, to ensure that dialog flows naturally. For document-grounded dialog systems, the inter- and intra-document knowledge relations can be used to model such conversational flows. We develop a novel Multi-Document Co-Referential Graph (Coref-MDG) to effectively capture the inter-document relationships based on commonsense and similarity and the intra-document co-referential structures of knowledge segments within the grounding documents. We propose CorefDiffs, a Co-referential and Differential flow management method, to linearize the static Coref-MDG into conversational sequence logic. CorefDiffs performs knowledge selection by accounting for contextual graph structures and the knowledge difference sequences. CorefDiffs significantly outperforms the state-of-the-art by 9.5\%, 7.4\%, and 8.2\% on three public benchmarks. This demonstrates that the effective modeling of co-reference and knowledge difference for dialog flows are critical for transitions in document-grounded conversation
End-to-End Knowledge-Routed Relational Dialogue System for Automatic Diagnosis
Mar 18, 2019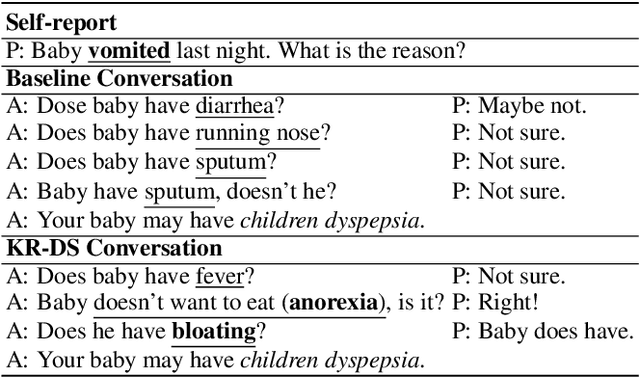
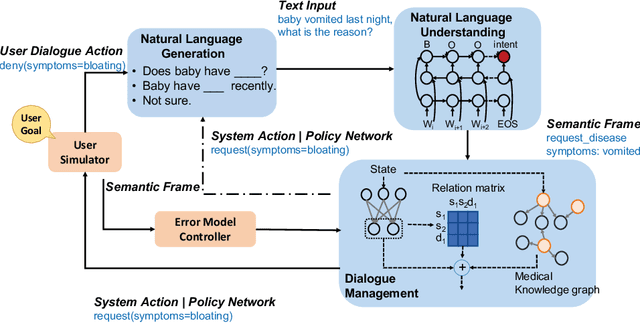
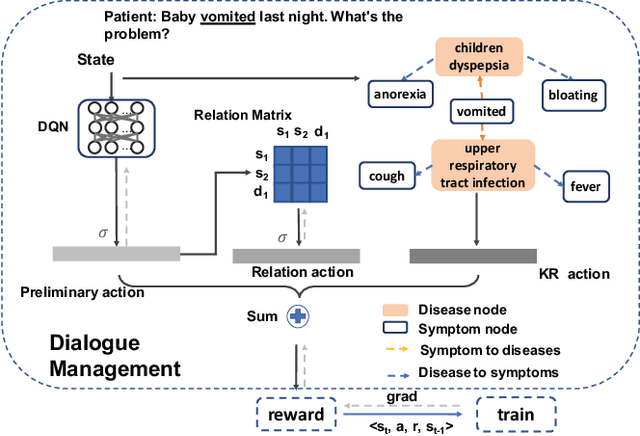

Beyond current conversational chatbots or task-oriented dialogue systems that have attracted increasing attention, we move forward to develop a dialogue system for automatic medical diagnosis that converses with patients to collect additional symptoms beyond their self-reports and automatically makes a diagnosis. Besides the challenges for conversational dialogue systems (e.g. topic transition coherency and question understanding), automatic medical diagnosis further poses more critical requirements for the dialogue rationality in the context of medical knowledge and symptom-disease relations. Existing dialogue systems (Madotto, Wu, and Fung 2018; Wei et al. 2018; Li et al. 2017) mostly rely on data-driven learning and cannot be able to encode extra expert knowledge graph. In this work, we propose an End-to-End Knowledge-routed Relational Dialogue System (KR-DS) that seamlessly incorporates rich medical knowledge graph into the topic transition in dialogue management, and makes it cooperative with natural language understanding and natural language generation. A novel Knowledge-routed Deep Q-network (KR-DQN) is introduced to manage topic transitions, which integrates a relational refinement branch for encoding relations among different symptoms and symptom-disease pairs, and a knowledge-routed graph branch for topic decision-making. Extensive experiments on a public medical dialogue dataset show our KR-DS significantly beats state-of-the-art methods (by more than 8% in diagnosis accuracy). We further show the superiority of our KR-DS on a newly collected medical dialogue system dataset, which is more challenging retaining original self-reports and conversational data between patients and doctors.
Adaptive Temporal Encoding Network for Video Instance-level Human Parsing
Aug 10, 2018
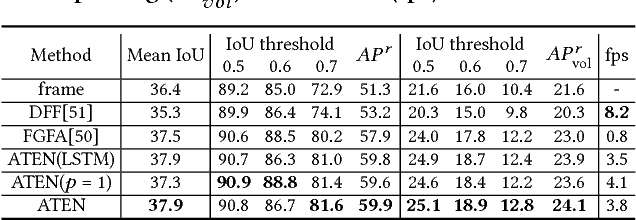
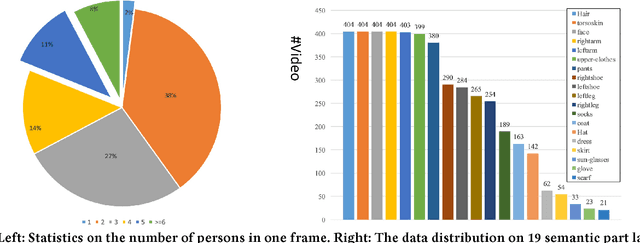
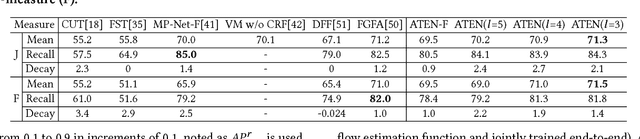
Beyond the existing single-person and multiple-person human parsing tasks in static images, this paper makes the first attempt to investigate a more realistic video instance-level human parsing that simultaneously segments out each person instance and parses each instance into more fine-grained parts (e.g., head, leg, dress). We introduce a novel Adaptive Temporal Encoding Network (ATEN) that alternatively performs temporal encoding among key frames and flow-guided feature propagation from other consecutive frames between two key frames. Specifically, ATEN first incorporates a Parsing-RCNN to produce the instance-level parsing result for each key frame, which integrates both the global human parsing and instance-level human segmentation into a unified model. To balance between accuracy and efficiency, the flow-guided feature propagation is used to directly parse consecutive frames according to their identified temporal consistency with key frames. On the other hand, ATEN leverages the convolution gated recurrent units (convGRU) to exploit temporal changes over a series of key frames, which are further used to facilitate the frame-level instance-level parsing. By alternatively performing direct feature propagation between consistent frames and temporal encoding network among key frames, our ATEN achieves a good balance between frame-level accuracy and time efficiency, which is a common crucial problem in video object segmentation research. To demonstrate the superiority of our ATEN, extensive experiments are conducted on the most popular video segmentation benchmark (DAVIS) and a newly collected Video Instance-level Parsing (VIP) dataset, which is the first video instance-level human parsing dataset comprised of 404 sequences and over 20k frames with instance-level and pixel-wise annotations.