 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Affordance Foresight: Planning Through What Can Be Done in the Future
Nov 17, 2020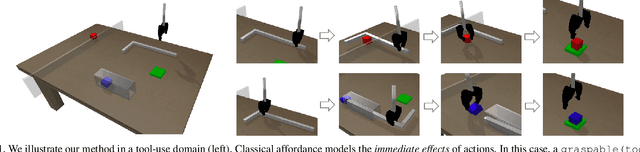
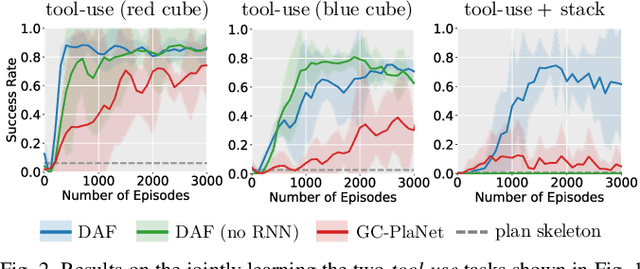
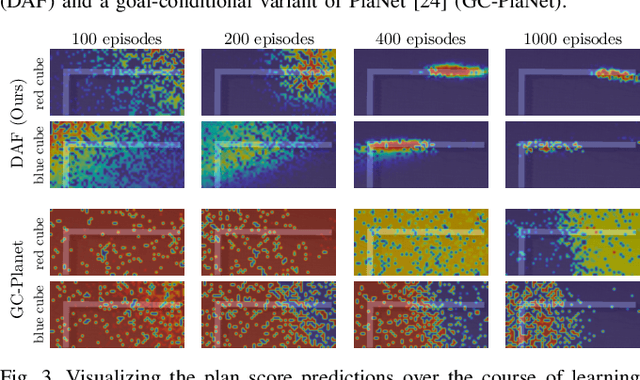
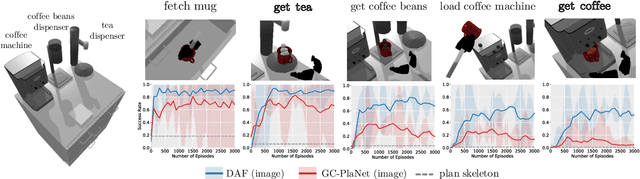
Planning in realistic environments requires searching in large planning spaces. Affordances are a powerful concept to simplify this search, because they model what actions can be successful in a given situation. However, the classical notion of affordance is not suitable for long horizon planning because it only informs the robot about the immediate outcome of actions instead of what actions are best for achieving a long-term goal. In this paper, we introduce a new affordance representation that enables the robot to reason about the long-term effects of actions through modeling what actions are afforded in the future, thereby informing the robot the best actions to take next to achieve a task goal. Based on the new representation, we develop a learning-to-plan method, Deep Affordance Foresight (DAF), that learns partial environment models of affordances of parameterized motor skills through trial-and-error. We evaluate DAF on two challenging manipulation domains and show that it can effectively learn to carry out multi-step tasks, share learned affordance representations among different tasks, and learn to plan with high-dimensional image inputs. Additional material is available at https://sites.google.com/stanford.edu/daf
Conceptual Metaphors Impact Perceptions of Human-AI Collaboration
Aug 05, 2020
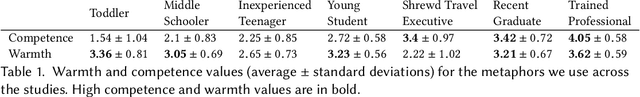
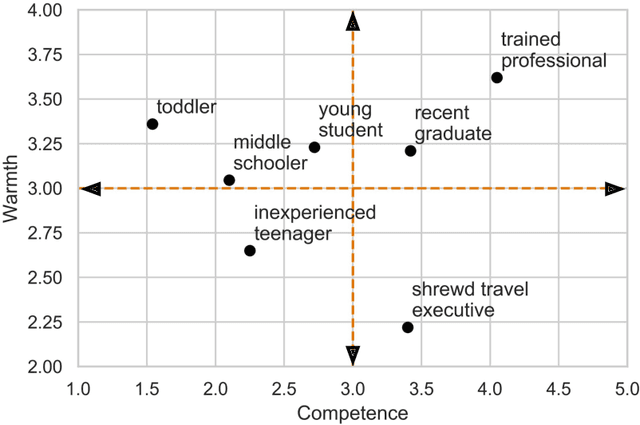
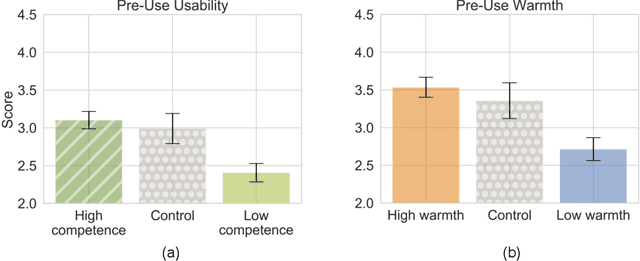
With the emergence of conversational artificial intelligence (AI) agents, it is important to understand the mechanisms that influence users' experiences of these agents. We study a common tool in the designer's toolkit: conceptual metaphors. Metaphors can present an agent as akin to a wry teenager, a toddler, or an experienced butler. How might a choice of metaphor influence our experience of the AI agent? Sampling metaphors along the dimensions of warmth and competence---defined by psychological theories as the primary axes of variation for human social perception---we perform a study (N=260) where we manipulate the metaphor, but not the behavior, of a Wizard-of-Oz conversational agent. Following the experience, participants are surveyed about their intention to use the agent, their desire to cooperate with the agent, and the agent's usability. Contrary to the current tendency of designers to use high competence metaphors to describe AI products, we find that metaphors that signal low competence lead to better evaluations of the agent than metaphors that signal high competence. This effect persists despite both high and low competence agents featuring human-level performance and the wizards being blind to condition. A second study confirms that intention to adopt decreases rapidly as competence projected by the metaphor increases. In a third study, we assess effects of metaphor choices on potential users' desire to try out the system and find that users are drawn to systems that project higher competence and warmth. These results suggest that projecting competence may help attract new users, but those users may discard the agent unless it can quickly correct with a lower competence metaphor. We close with a retrospective analysis that finds similar patterns between metaphors and user attitudes towards past conversational agents such as Xiaoice, Replika, Woebot, Mitsuku, and Tay.
* CSCW 2020
Vision-based Estimation of MDS-UPDRS Gait Scores for Assessing Parkinson's Disease Motor Severity
Jul 17, 2020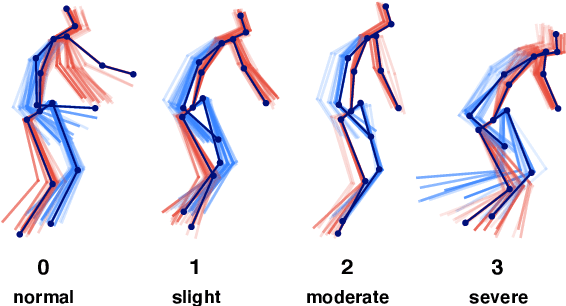
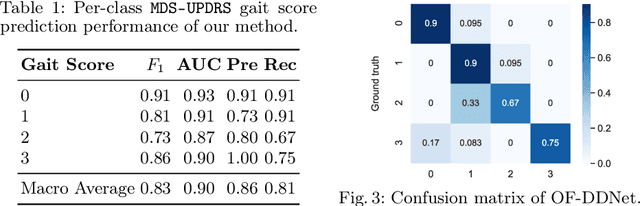
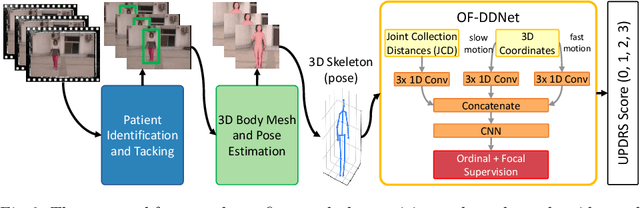
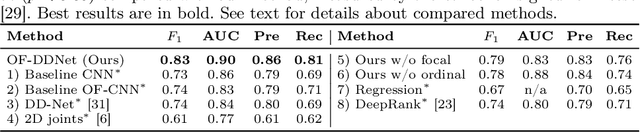
Parkinson's disease (PD) is a progressive neurological disorder primarily affecting motor function resulting in tremor at rest, rigidity, bradykinesia, and postural instability. The physical severity of PD impairments can be quantified through the Movement Disorder Society Unified Parkinson's Disease Rating Scale (MDS-UPDRS), a widely used clinical rating scale. Accurate and quantitative assessment of disease progression is critical to developing a treatment that slows or stops further advancement of the disease. Prior work has mainly focused on dopamine transport neuroimaging for diagnosis or costly and intrusive wearables evaluating motor impairments. For the first time, we propose a computer vision-based model that observes non-intrusive video recordings of individuals, extracts their 3D body skeletons, tracks them through time, and classifies the movements according to the MDS-UPDRS gait scores. Experimental results show that our proposed method performs significantly better than chance and competing methods with an F1-score of 0.83 and a balanced accuracy of 81%. This is the first benchmark for classifying PD patients based on MDS-UPDRS gait severity and could be an objective biomarker for disease severity. Our work demonstrates how computer-assisted technologies can be used to non-intrusively monitor patients and their motor impairments. The code is available at https://github.com/mlu355/PD-Motor-Severity-Estimation.
Adaptive Procedural Task Generation for Hard-Exploration Problems
Jul 01, 2020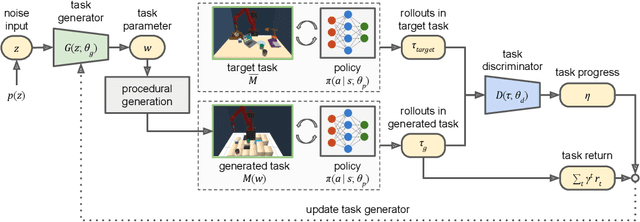
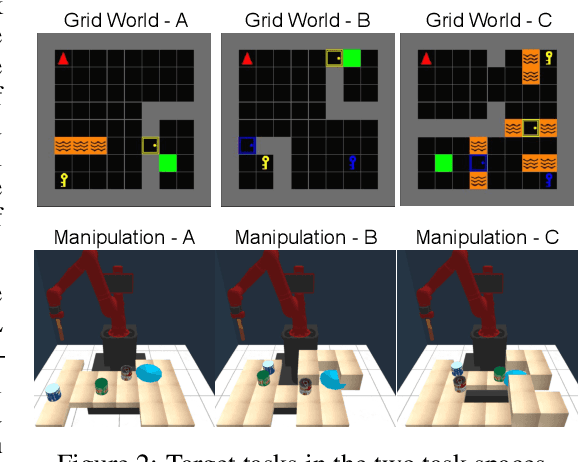
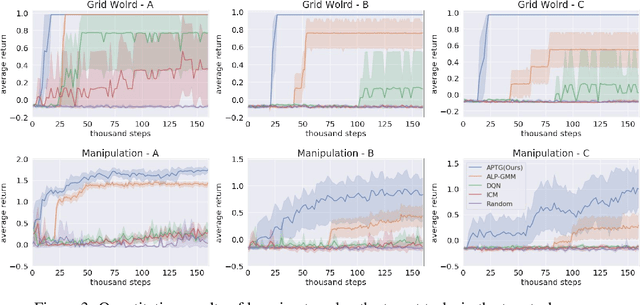
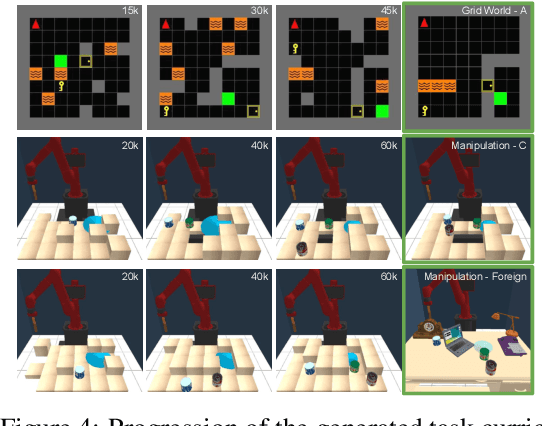
We introduce Adaptive Procedural Task Generation (APT-Gen), an approach for progressively generating a sequence of tasks as curricula to facilitate reinforcement learning in hard-exploration problems. At the heart of our approach, a task generator learns to create tasks via a black-box procedural generation module by adaptively sampling from the parameterized task space. To enable curriculum learning in the absence of a direct indicator of learning progress, the task generator is trained by balancing the agent's expected return in the generated tasks and their similarities to the target task. Through adversarial training, the similarity between the generated tasks and the target task is adaptively estimated by a task discriminator defined on the agent's behaviors. In this way, our approach can efficiently generate tasks of rich variations for target tasks of unknown parameterization or not covered by the predefined task space. Experiments demonstrate the effectiveness of our approach through quantitative and qualitative analysis in various scenarios.
Learning Physical Graph Representations from Visual Scenes
Jun 24, 2020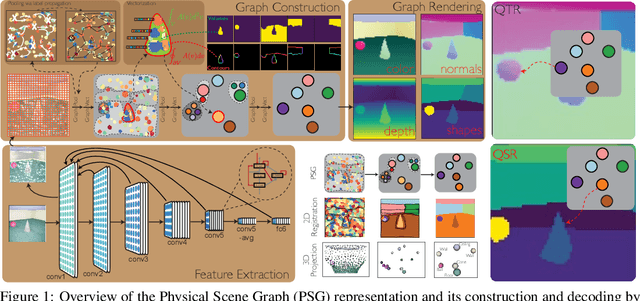
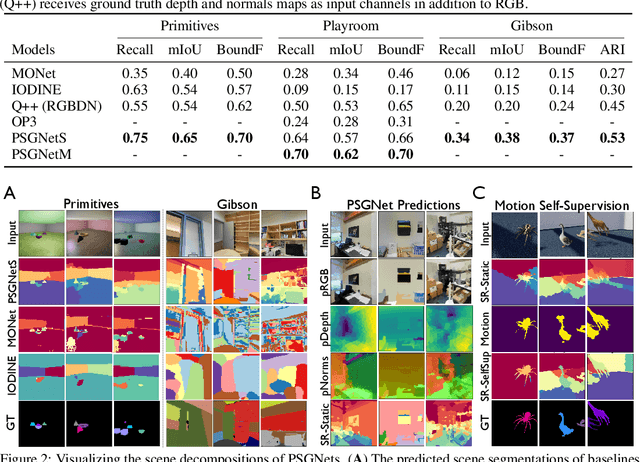
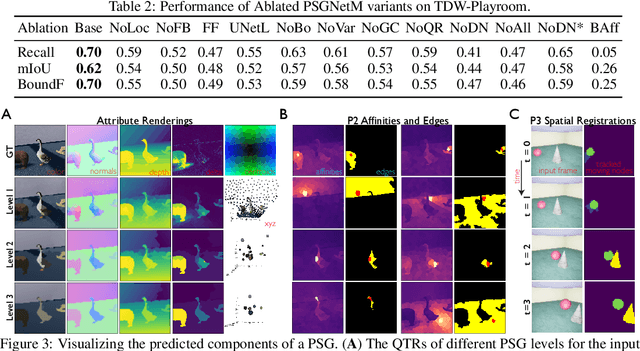

Convolutional Neural Networks (CNNs) have proved exceptional at learning representations for visual object categorization. However, CNNs do not explicitly encode objects, parts, and their physical properties, which has limited CNNs' success on tasks that require structured understanding of visual scenes. To overcome these limitations, we introduce the idea of Physical Scene Graphs (PSGs), which represent scenes as hierarchical graphs, with nodes in the hierarchy corresponding intuitively to object parts at different scales, and edges to physical connections between parts. Bound to each node is a vector of latent attributes that intuitively represent object properties such as surface shape and texture. We also describe PSGNet, a network architecture that learns to extract PSGs by reconstructing scenes through a PSG-structured bottleneck. PSGNet augments standard CNNs by including: recurrent feedback connections to combine low and high-level image information; graph pooling and vectorization operations that convert spatially-uniform feature maps into object-centric graph structures; and perceptual grouping principles to encourage the identification of meaningful scene elements. We show that PSGNet outperforms alternative self-supervised scene representation algorithms at scene segmentation tasks, especially on complex real-world images, and generalizes well to unseen object types and scene arrangements. PSGNet is also able learn from physical motion, enhancing scene estimates even for static images. We present a series of ablation studies illustrating the importance of each component of the PSGNet architecture, analyses showing that learned latent attributes capture intuitive scene properties, and illustrate the use of PSGs for compositional scene inference.
Learning to Generalize Across Long-Horizon Tasks from Human Demonstrations
Mar 13, 2020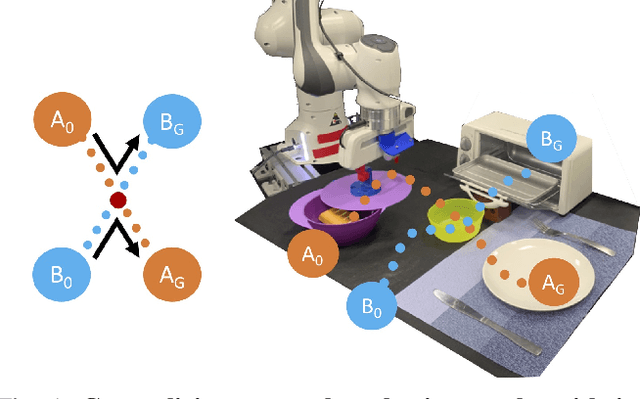
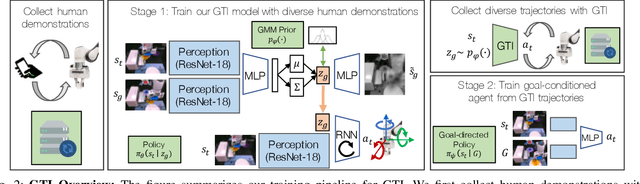

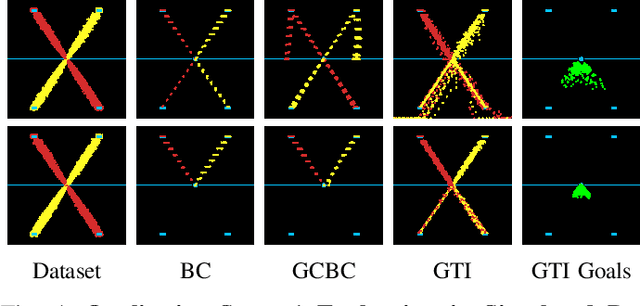
Imitation learning is an effective and safe technique to train robot policies in the real world because it does not depend on an expensive random exploration process. However, due to the lack of exploration, learning policies that generalize beyond the demonstrated behaviors is still an open challenge. We present a novel imitation learning framework to enable robots to 1) learn complex real world manipulation tasks efficiently from a small number of human demonstrations, and 2) synthesize new behaviors not contained in the collected demonstrations. Our key insight is that multi-task domains often present a latent structure, where demonstrated trajectories for different tasks intersect at common regions of the state space. We present Generalization Through Imitation (GTI), a two-stage offline imitation learning algorithm that exploits this intersecting structure to train goal-directed policies that generalize to unseen start and goal state combinations. In the first stage of GTI, we train a stochastic policy that leverages trajectory intersections to have the capacity to compose behaviors from different demonstration trajectories together. In the second stage of GTI, we collect a small set of rollouts from the unconditioned stochastic policy of the first stage, and train a goal-directed agent to generalize to novel start and goal configurations. We validate GTI in both simulated domains and a challenging long-horizon robotic manipulation domain in the real world. Additional results and videos are available at https://sites.google.com/view/gti2020/ .
Towards Fairer Datasets: Filtering and Balancing the Distribution of the People Subtree in the ImageNet Hierarchy
Dec 16, 2019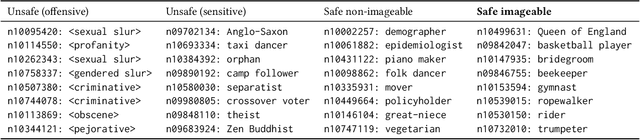
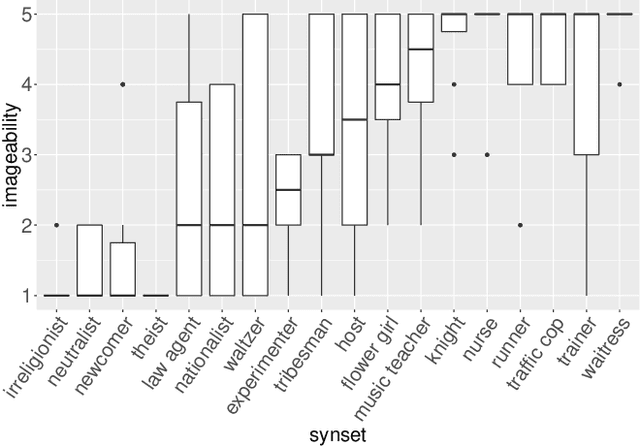
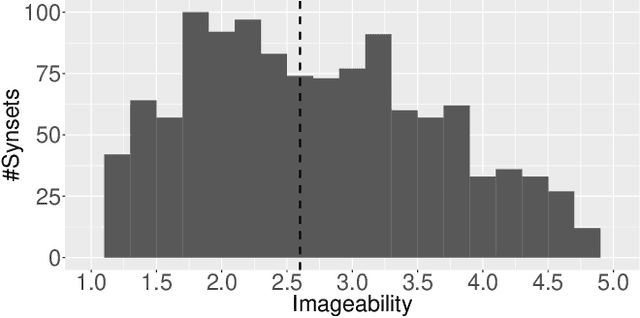
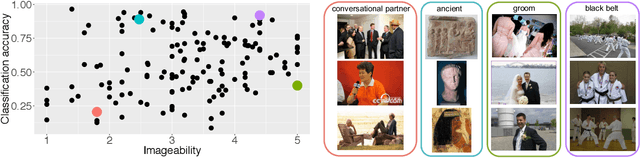
Computer vision technology is being used by many but remains representative of only a few. People have reported misbehavior of computer vision models, including offensive prediction results and lower performance for underrepresented groups. Current computer vision models are typically developed using datasets consisting of manually annotated images or videos; the data and label distributions in these datasets are critical to the models' behavior. In this paper, we examine ImageNet, a large-scale ontology of images that has spurred the development of many modern computer vision methods. We consider three key factors within the "person" subtree of ImageNet that may lead to problematic behavior in downstream computer vision technology: (1) the stagnant concept vocabulary of WordNet, (2) the attempt at exhaustive illustration of all categories with images, and (3) the inequality of representation in the images within concepts. We seek to illuminate the root causes of these concerns and take the first steps to mitigate them constructively.
Action Genome: Actions as Composition of Spatio-temporal Scene Graphs
Dec 15, 2019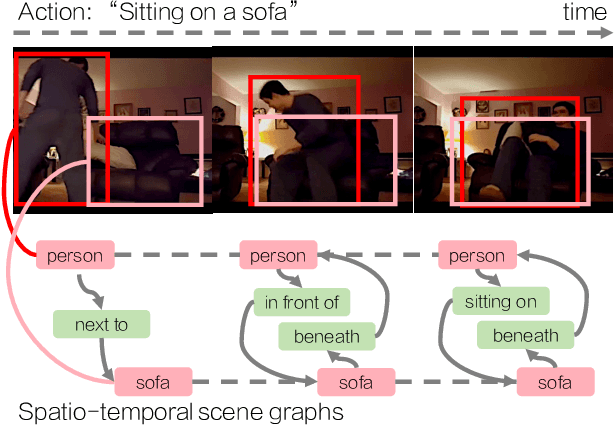

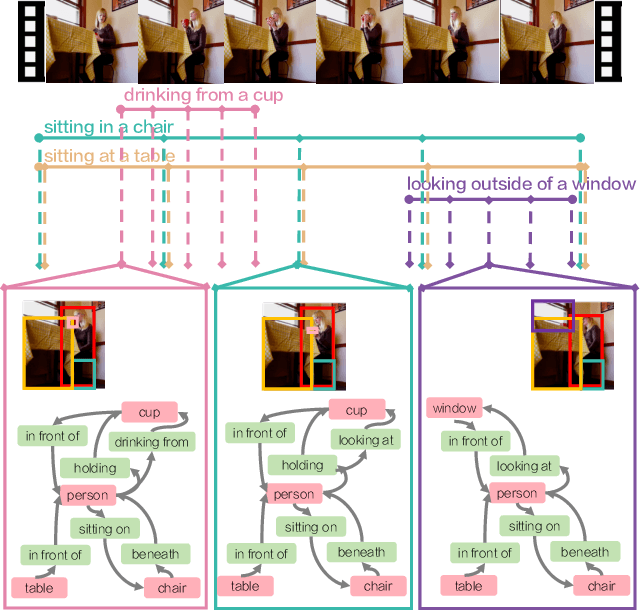

Action recognition has typically treated actions and activities as monolithic events that occur in videos. However, there is evidence from Cognitive Science and Neuroscience that people actively encode activities into consistent hierarchical part structures. However in Computer Vision, few explorations on representations encoding event partonomies have been made. Inspired by evidence that the prototypical unit of an event is an action-object interaction, we introduce Action Genome, a representation that decomposes actions into spatio-temporal scene graphs. Action Genome captures changes between objects and their pairwise relationships while an action occurs. It contains 10K videos with 0.4M objects and 1.7M visual relationships annotated. With Action Genome, we extend an existing action recognition model by incorporating scene graphs as spatio-temporal feature banks to achieve better performance on the Charades dataset. Next, by decomposing and learning the temporal changes in visual relationships that result in an action, we demonstrate the utility of a hierarchical event decomposition by enabling few-shot action recognition, achieving 42.7% mAP using as few as 10 examples. Finally, we benchmark existing scene graph models on the new task of spatio-temporal scene graph prediction.
Deep Bayesian Active Learning for Multiple Correct Outputs
Dec 08, 2019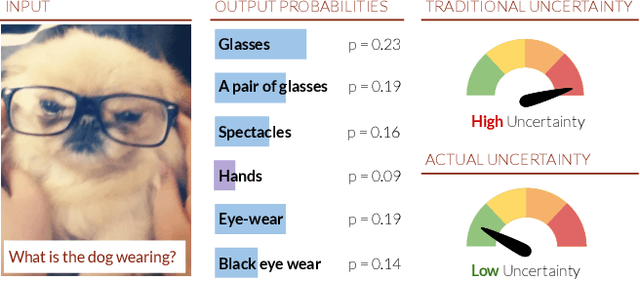
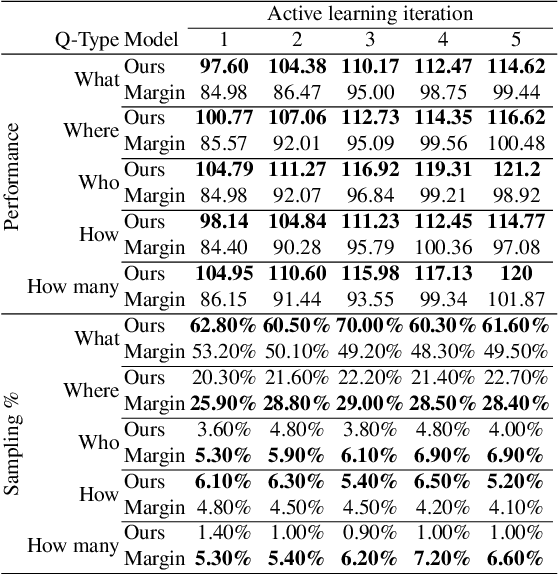
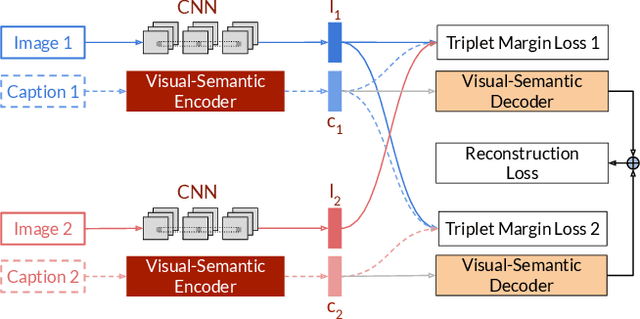
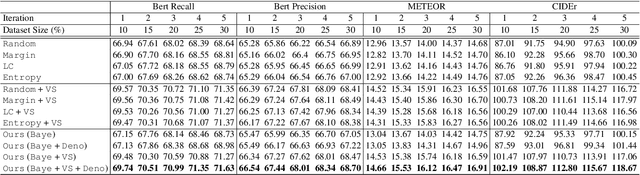
Typical active learning strategies are designed for tasks, such as classification, with the assumption that the output space is mutually exclusive. The assumption that these tasks always have exactly one correct answer has resulted in the creation of numerous uncertainty-based measurements, such as entropy and least confidence, which operate over a model's outputs. Unfortunately, many real-world vision tasks, like visual question answering and image captioning, have multiple correct answers, causing these measurements to overestimate uncertainty and sometimes perform worse than a random sampling baseline. In this paper, we propose a new paradigm that estimates uncertainty in the model's internal hidden space instead of the model's output space. We specifically study a manifestation of this problem for visual question answer generation (VQA), where the aim is not to classify the correct answer but to produce a natural language answer, given an image and a question. Our method overcomes the paraphrastic nature of language. It requires a semantic space that structures the model's output concepts and that enables the usage of techniques like dropout-based Bayesian uncertainty. We build a visual-semantic space that embeds paraphrases close together for any existing VQA model. We empirically show state-of-art active learning results on the task of VQA on two datasets, being 5 times more cost-efficient on Visual Genome and 3 times more cost-efficient on VQA 2.0.
Motion Reasoning for Goal-Based Imitation Learning
Nov 13, 2019
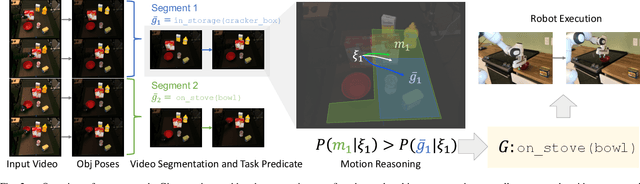
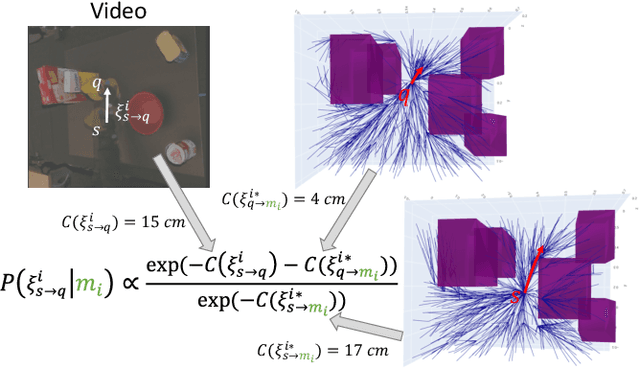

We address goal-based imitation learning, where the aim is to output the symbolic goal from a third-person video demonstration. This enables the robot to plan for execution and reproduce the same goal in a completely different environment. The key challenge is that the goal of a video demonstration is often ambiguous at the level of semantic actions. The human demonstrators might unintentionally achieve certain subgoals in the demonstrations with their actions. Our main contribution is to propose a motion reasoning framework that combines task and motion planning to disambiguate the true intention of the demonstrator in the video demonstration. This allows us to robustly recognize the goals that cannot be disambiguated by previous action-based approaches. We evaluate our approach by collecting a dataset of 96 video demonstrations in a mockup kitchen environment. We show that our motion reasoning plays an important role in recognizing the actual goal of the demonstrator and improves the success rate by over 20%. We further show that by using the automatically inferred goal from the video demonstration, our robot is able to reproduce the same task in a real kitchen environment.