 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgospeak, Hiding in the Open: The Trade-off Between Legible Meaning and Detection Avoidance
May 07, 2026As large language models (LLMs) increasingly mediate both content generation and moderation, linguistic evasion strategies known as Algospeak have intensified the coevolution between evaders and detectors. This research formalizes the underlying dynamics grounded in a joint action model: when Algospeak increases, detectability and understandability decrease. Further, the concept of Majority Understandable Modulation (MUM) is introduced and defined as the modulation level at which additional evasive alteration increases detector evasion but loses comprehension for the majority of recipients. To empirically probe this trade-off, we introduce a reproducible framework that can be used to create meaning-preserving, Algospeak-style variants, based on an existing taxonomy and with tunable modulation levels. Using COVID-19 disinformation as a first proof-by-example setting, we construct a reference dataset of 700 modulated items, drawn from twenty base sentences across five modulation levels and seven strategies. We then run two linked evaluations with seven different language models: one testing for interpretation through meaning recovery and one for disinformation detection through classification. Curve fitting over modulation levels yields an estimate of the Majority Understandable Modulation threshold and enables sensitivity analyses across strategies and models, see Figure 1. Results reveal the characteristic relationships between understandability and modulation. This study lays the groundwork for understanding the dynamics behind Algospeak and provides the framework, dataset, and experimental setups described.
From tools to thieves: Measuring and understanding public perceptions of AI through crowdsourced metaphors
Jan 29, 2025



How has the public responded to the increasing prevalence of artificial intelligence (AI)-based technologies? We investigate public perceptions of AI by collecting over 12,000 responses over 12 months from a nationally representative U.S. sample. Participants provided open-ended metaphors reflecting their mental models of AI, a methodology that overcomes the limitations of traditional self-reported measures. Using a mixed-methods approach combining quantitative clustering and qualitative coding, we identify 20 dominant metaphors shaping public understanding of AI. To analyze these metaphors systematically, we present a scalable framework integrating language modeling (LM)-based techniques to measure key dimensions of public perception: anthropomorphism (attribution of human-like qualities), warmth, and competence. We find that Americans generally view AI as warm and competent, and that over the past year, perceptions of AI's human-likeness and warmth have significantly increased ($+34\%, r = 0.80, p < 0.01; +41\%, r = 0.62, p < 0.05$). Furthermore, these implicit perceptions, along with the identified dominant metaphors, strongly predict trust in and willingness to adopt AI ($r^2 = 0.21, 0.18, p < 0.001$). We further explore how differences in metaphors and implicit perceptions--such as the higher propensity of women, older individuals, and people of color to anthropomorphize AI--shed light on demographic disparities in trust and adoption. In addition to our dataset and framework for tracking evolving public attitudes, we provide actionable insights on using metaphors for inclusive and responsible AI development.
Human Heuristics for AI-Generated Language Are Flawed
Jun 15, 2022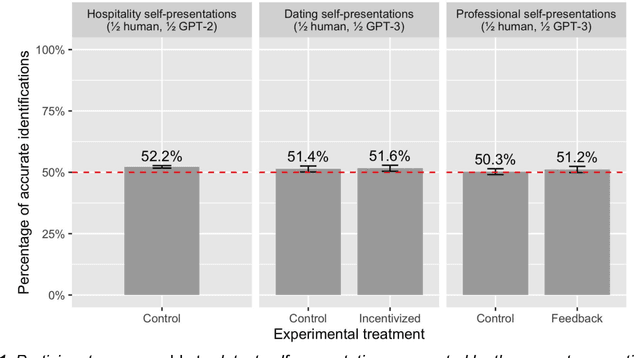
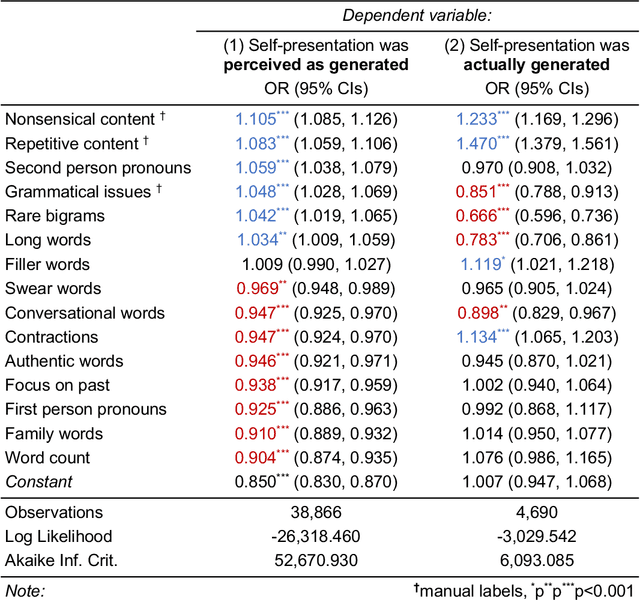
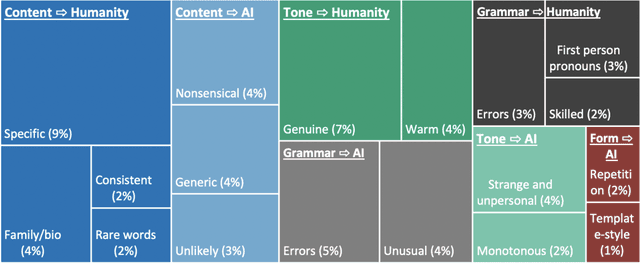
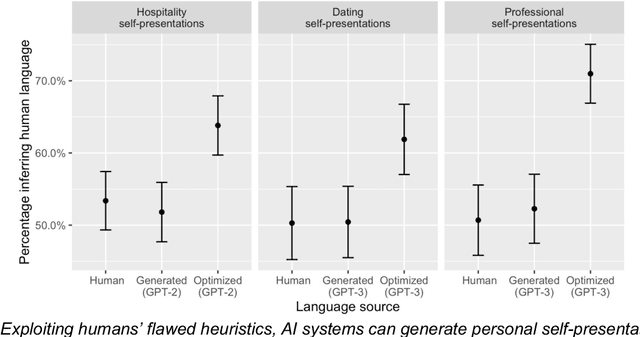
Human communication is increasingly intermixed with language generated by AI. Across chat, email, and social media, AI systems produce smart replies, autocompletes, and translations. AI-generated language is often not identified as such but poses as human language, raising concerns about novel forms of deception and manipulation. Here, we study how humans discern whether one of the most personal and consequential forms of language - a self-presentation - was generated by AI. Across six experiments, participants (N = 4,650) tried to identify self-presentations generated by state-of-the-art language models. Across professional, hospitality, and romantic settings, we find that humans are unable to identify AI-generated self-presentations. Combining qualitative analyses with language feature engineering, we find that human judgments of AI-generated language are handicapped by intuitive but flawed heuristics such as associating first-person pronouns, authentic words, or family topics with humanity. We show that these heuristics make human judgment of generated language predictable and manipulable, allowing AI systems to produce language perceived as more human than human. We conclude by discussing solutions - such as AI accents or fair use policies - to reduce the deceptive potential of generated language, limiting the subversion of human intuition.
Conceptual Metaphors Impact Perceptions of Human-AI Collaboration
Aug 05, 2020
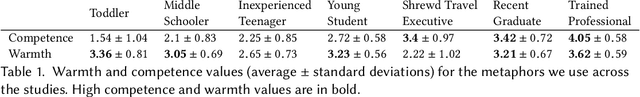
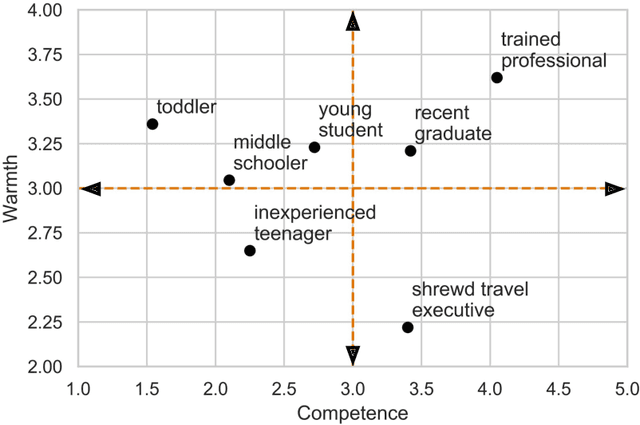
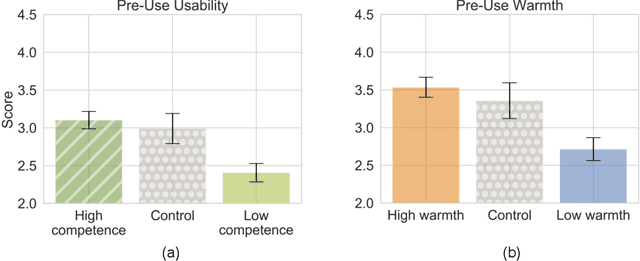
With the emergence of conversational artificial intelligence (AI) agents, it is important to understand the mechanisms that influence users' experiences of these agents. We study a common tool in the designer's toolkit: conceptual metaphors. Metaphors can present an agent as akin to a wry teenager, a toddler, or an experienced butler. How might a choice of metaphor influence our experience of the AI agent? Sampling metaphors along the dimensions of warmth and competence---defined by psychological theories as the primary axes of variation for human social perception---we perform a study (N=260) where we manipulate the metaphor, but not the behavior, of a Wizard-of-Oz conversational agent. Following the experience, participants are surveyed about their intention to use the agent, their desire to cooperate with the agent, and the agent's usability. Contrary to the current tendency of designers to use high competence metaphors to describe AI products, we find that metaphors that signal low competence lead to better evaluations of the agent than metaphors that signal high competence. This effect persists despite both high and low competence agents featuring human-level performance and the wizards being blind to condition. A second study confirms that intention to adopt decreases rapidly as competence projected by the metaphor increases. In a third study, we assess effects of metaphor choices on potential users' desire to try out the system and find that users are drawn to systems that project higher competence and warmth. These results suggest that projecting competence may help attract new users, but those users may discard the agent unless it can quickly correct with a lower competence metaphor. We close with a retrospective analysis that finds similar patterns between metaphors and user attitudes towards past conversational agents such as Xiaoice, Replika, Woebot, Mitsuku, and Tay.
* CSCW 2020