 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMastering Visual Continuous Control: Improved Data-Augmented Reinforcement Learning
Jul 20, 2021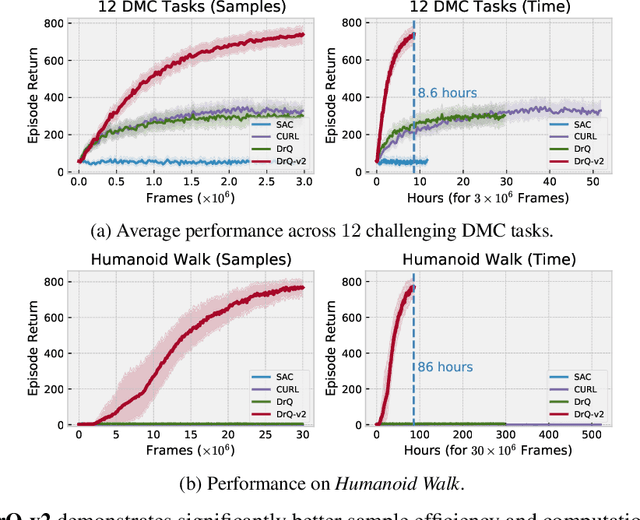
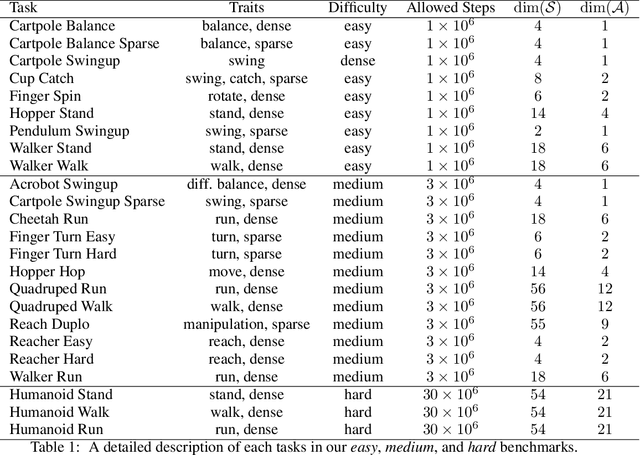
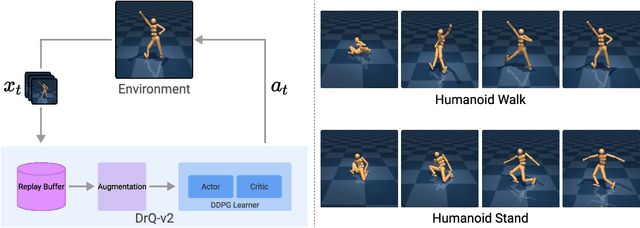

We present DrQ-v2, a model-free reinforcement learning (RL) algorithm for visual continuous control. DrQ-v2 builds on DrQ, an off-policy actor-critic approach that uses data augmentation to learn directly from pixels. We introduce several improvements that yield state-of-the-art results on the DeepMind Control Suite. Notably, DrQ-v2 is able to solve complex humanoid locomotion tasks directly from pixel observations, previously unattained by model-free RL. DrQ-v2 is conceptually simple, easy to implement, and provides significantly better computational footprint compared to prior work, with the majority of tasks taking just 8 hours to train on a single GPU. Finally, we publicly release DrQ-v2's implementation to provide RL practitioners with a strong and computationally efficient baseline.
Playful Interactions for Representation Learning
Jul 19, 2021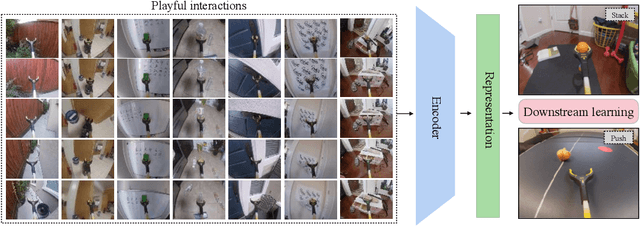


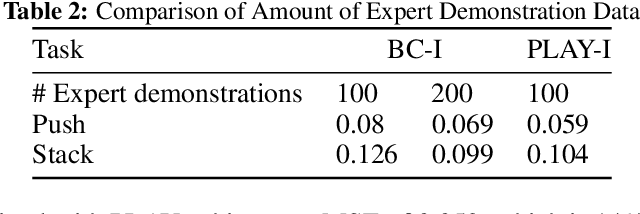
One of the key challenges in visual imitation learning is collecting large amounts of expert demonstrations for a given task. While methods for collecting human demonstrations are becoming easier with teleoperation methods and the use of low-cost assistive tools, we often still require 100-1000 demonstrations for every task to learn a visual representation and policy. To address this, we turn to an alternate form of data that does not require task-specific demonstrations -- play. Playing is a fundamental method children use to learn a set of skills and behaviors and visual representations in early learning. Importantly, play data is diverse, task-agnostic, and relatively cheap to obtain. In this work, we propose to use playful interactions in a self-supervised manner to learn visual representations for downstream tasks. We collect 2 hours of playful data in 19 diverse environments and use self-predictive learning to extract visual representations. Given these representations, we train policies using imitation learning for two downstream tasks: Pushing and Stacking. We demonstrate that our visual representations generalize better than standard behavior cloning and can achieve similar performance with only half the number of required demonstrations. Our representations, which are trained from scratch, compare favorably against ImageNet pretrained representations. Finally, we provide an experimental analysis on the effects of different pretraining modes on downstream task learning.
GEM: Group Enhanced Model for Learning Dynamical Control Systems
Apr 07, 2021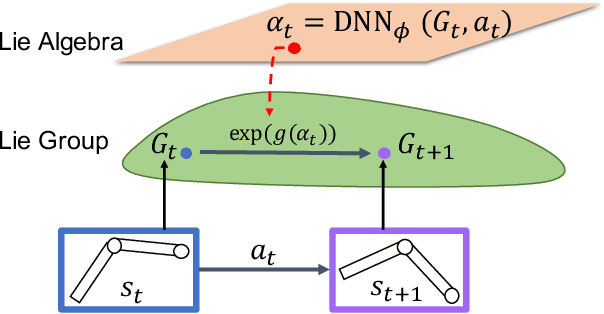
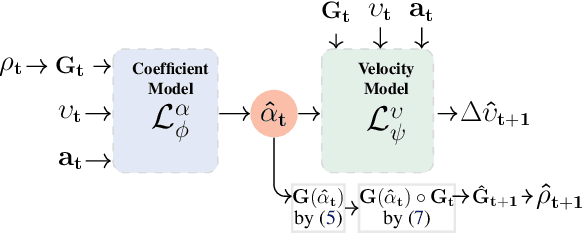
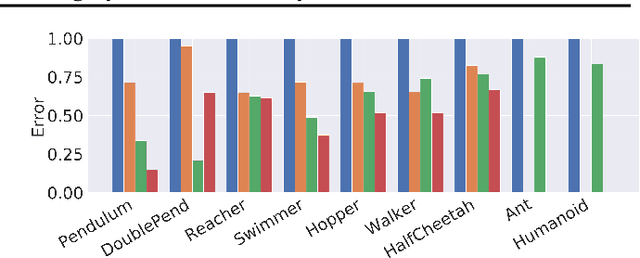
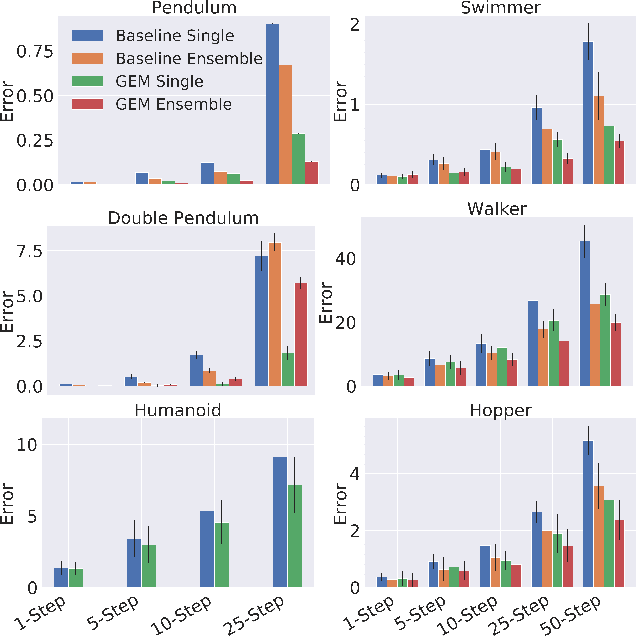
Learning the dynamics of a physical system wherein an autonomous agent operates is an important task. Often these systems present apparent geometric structures. For instance, the trajectories of a robotic manipulator can be broken down into a collection of its transitional and rotational motions, fully characterized by the corresponding Lie groups and Lie algebras. In this work, we take advantage of these structures to build effective dynamical models that are amenable to sample-based learning. We hypothesize that learning the dynamics on a Lie algebra vector space is more effective than learning a direct state transition model. To verify this hypothesis, we introduce the Group Enhanced Model (GEM). GEMs significantly outperform conventional transition models on tasks of long-term prediction, planning, and model-based reinforcement learning across a diverse suite of standard continuous-control environments, including Walker, Hopper, Reacher, Half-Cheetah, Inverted Pendulums, Ant, and Humanoid. Furthermore, plugging GEM into existing state of the art systems enhances their performance, which we demonstrate on the PETS system. This work sheds light on a connection between learning of dynamics and Lie group properties, which opens doors for new research directions and practical applications along this direction. Our code is publicly available at: https://tinyurl.com/GEMMBRL.
Simultaneous Navigation and Construction Benchmarking Environments
Mar 31, 2021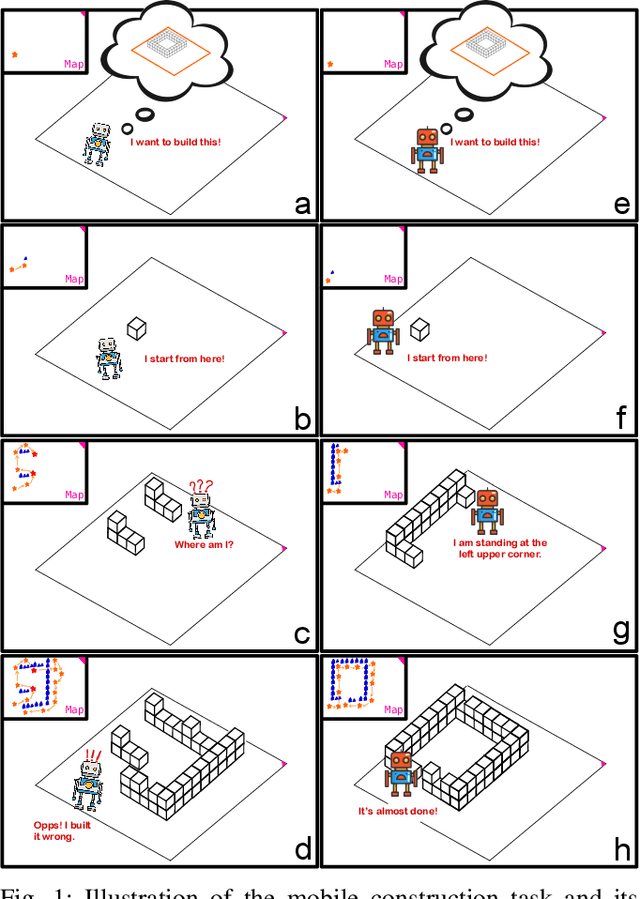
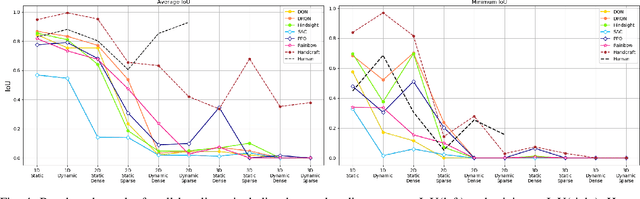
We need intelligent robots for mobile construction, the process of navigating in an environment and modifying its structure according to a geometric design. In this task, a major robot vision and learning challenge is how to exactly achieve the design without GPS, due to the difficulty caused by the bi-directional coupling of accurate robot localization and navigation together with strategic environment manipulation. However, many existing robot vision and learning tasks such as visual navigation and robot manipulation address only one of these two coupled aspects. To stimulate the pursuit of a generic and adaptive solution, we reasonably simplify mobile construction as a partially observable Markov decision process (POMDP) in 1/2/3D grid worlds and benchmark the performance of a handcrafted policy with basic localization and planning, and state-of-the-art deep reinforcement learning (RL) methods. Our extensive experiments show that the coupling makes this problem very challenging for those methods, and emphasize the need for novel task-specific solutions.
Task-Agnostic Morphology Evolution
Feb 25, 2021

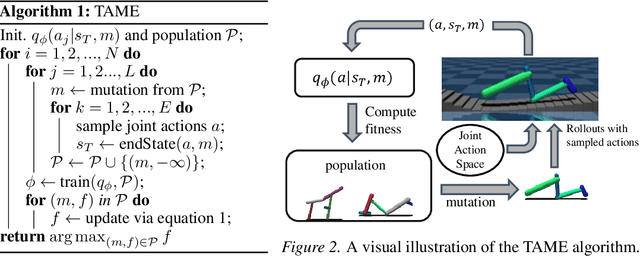
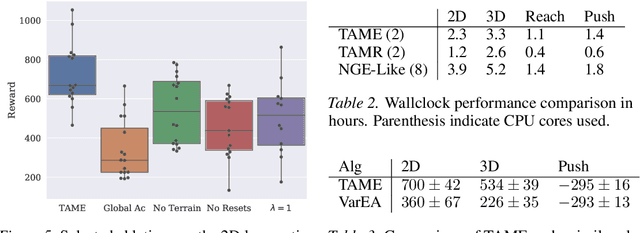
Deep reinforcement learning primarily focuses on learning behavior, usually overlooking the fact that an agent's function is largely determined by form. So, how should one go about finding a morphology fit for solving tasks in a given environment? Current approaches that co-adapt morphology and behavior use a specific task's reward as a signal for morphology optimization. However, this often requires expensive policy optimization and results in task-dependent morphologies that are not built to generalize. In this work, we propose a new approach, Task-Agnostic Morphology Evolution (TAME), to alleviate both of these issues. Without any task or reward specification, TAME evolves morphologies by only applying randomly sampled action primitives on a population of agents. This is accomplished using an information-theoretic objective that efficiently ranks agents by their ability to reach diverse states in the environment and the causality of their actions. Finally, we empirically demonstrate that across 2D, 3D, and manipulation environments TAME can evolve morphologies that match the multi-task performance of those learned with task supervised algorithms. Our code and videos can be found at https://sites.google.com/view/task-agnostic-evolution.
Reinforcement Learning with Prototypical Representations
Feb 22, 2021
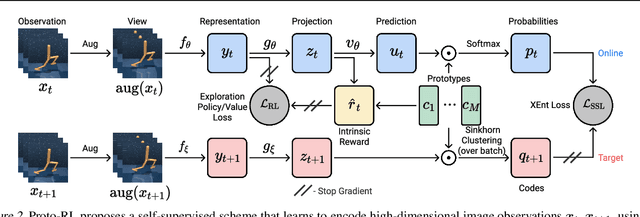
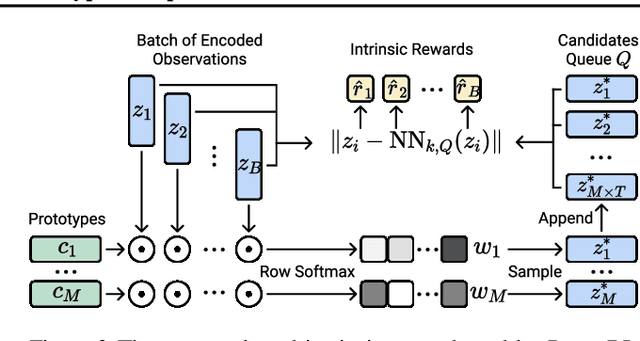
Learning effective representations in image-based environments is crucial for sample efficient Reinforcement Learning (RL). Unfortunately, in RL, representation learning is confounded with the exploratory experience of the agent -- learning a useful representation requires diverse data, while effective exploration is only possible with coherent representations. Furthermore, we would like to learn representations that not only generalize across tasks but also accelerate downstream exploration for efficient task-specific training. To address these challenges we propose Proto-RL, a self-supervised framework that ties representation learning with exploration through prototypical representations. These prototypes simultaneously serve as a summarization of the exploratory experience of an agent as well as a basis for representing observations. We pre-train these task-agnostic representations and prototypes on environments without downstream task information. This enables state-of-the-art downstream policy learning on a set of difficult continuous control tasks.
Learning Cross-Domain Correspondence for Control with Dynamics Cycle-Consistency
Dec 17, 2020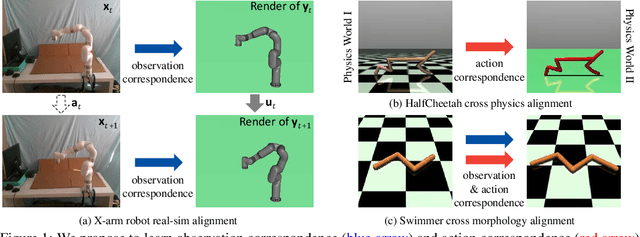
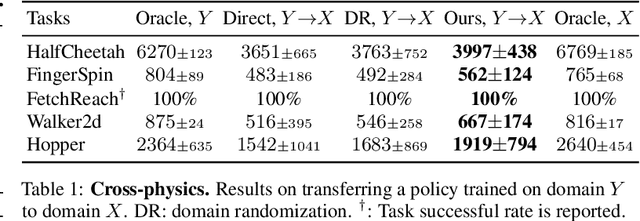
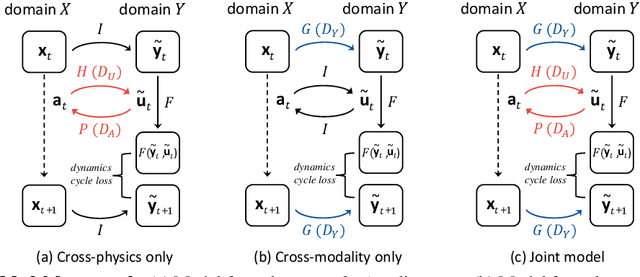

At the heart of many robotics problems is the challenge of learning correspondences across domains. For instance, imitation learning requires obtaining correspondence between humans and robots; sim-to-real requires correspondence between physics simulators and the real world; transfer learning requires correspondences between different robotics environments. This paper aims to learn correspondence across domains differing in representation (vision vs. internal state), physics parameters (mass and friction), and morphology (number of limbs). Importantly, correspondences are learned using unpaired and randomly collected data from the two domains. We propose \textit{dynamics cycles} that align dynamic robot behavior across two domains using a cycle-consistency constraint. Once this correspondence is found, we can directly transfer the policy trained on one domain to the other, without needing any additional fine-tuning on the second domain. We perform experiments across a variety of problem domains, both in simulation and on real robot. Our framework is able to align uncalibrated monocular video of a real robot arm to dynamic state-action trajectories of a simulated arm without paired data. Video demonstrations of our results are available at: https://sjtuzq.github.io/cycle_dynamics.html .
A Framework for Efficient Robotic Manipulation
Dec 14, 2020
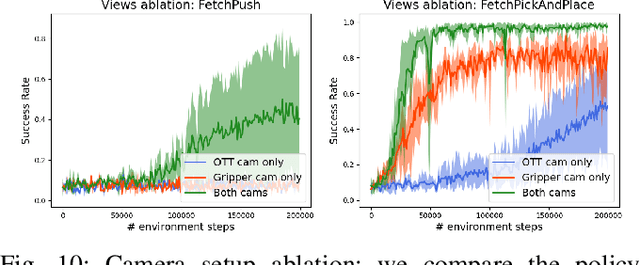
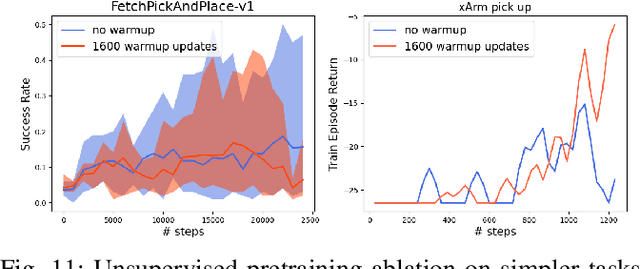
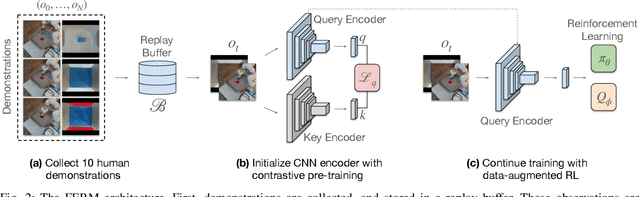
Data-efficient learning of manipulation policies from visual observations is an outstanding challenge for real-robot learning. While deep reinforcement learning (RL) algorithms have shown success learning policies from visual observations, they still require an impractical number of real-world data samples to learn effective policies. However, recent advances in unsupervised representation learning and data augmentation significantly improved the sample efficiency of training RL policies on common simulated benchmarks. Building on these advances, we present a Framework for Efficient Robotic Manipulation (FERM) that utilizes data augmentation and unsupervised learning to achieve extremely sample-efficient training of robotic manipulation policies with sparse rewards. We show that, given only 10 demonstrations, a single robotic arm can learn sparse-reward manipulation policies from pixels, such as reaching, picking, moving, pulling a large object, flipping a switch, and opening a drawer in just 15-50 minutes of real-world training time. We include videos, code, and additional information on the project website -- https://sites.google.com/view/efficient-robotic-manipulation.
Robust Policies via Mid-Level Visual Representations: An Experimental Study in Manipulation and Navigation
Nov 13, 2020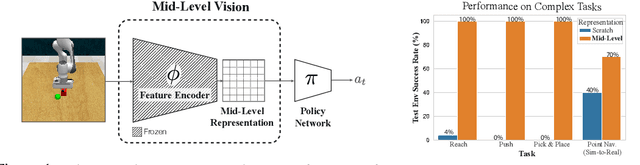
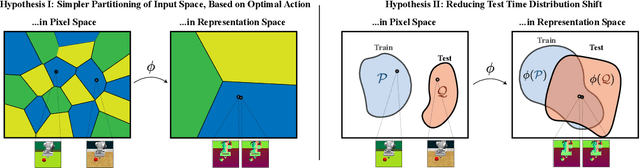
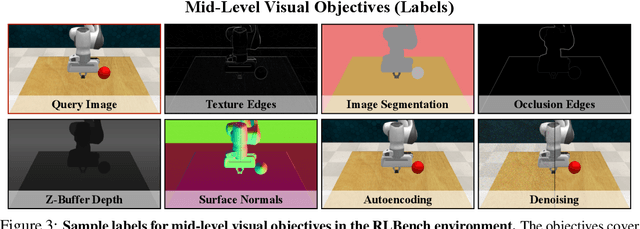
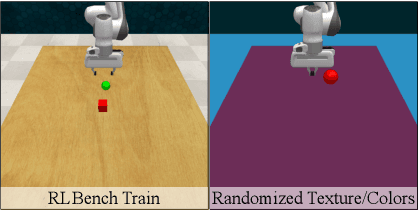
Vision-based robotics often separates the control loop into one module for perception and a separate module for control. It is possible to train the whole system end-to-end (e.g. with deep RL), but doing it "from scratch" comes with a high sample complexity cost and the final result is often brittle, failing unexpectedly if the test environment differs from that of training. We study the effects of using mid-level visual representations (features learned asynchronously for traditional computer vision objectives), as a generic and easy-to-decode perceptual state in an end-to-end RL framework. Mid-level representations encode invariances about the world, and we show that they aid generalization, improve sample complexity, and lead to a higher final performance. Compared to other approaches for incorporating invariances, such as domain randomization, asynchronously trained mid-level representations scale better: both to harder problems and to larger domain shifts. In practice, this means that mid-level representations could be used to successfully train policies for tasks where domain randomization and learning-from-scratch failed. We report results on both manipulation and navigation tasks, and for navigation include zero-shot sim-to-real experiments on real robots.
Visual Imitation Made Easy
Aug 11, 2020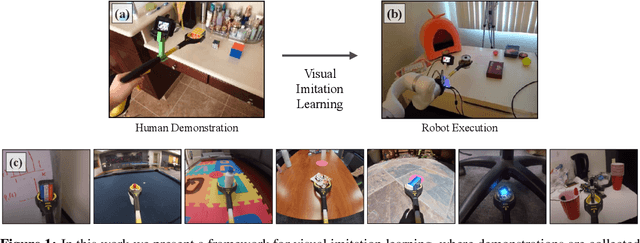



Visual imitation learning provides a framework for learning complex manipulation behaviors by leveraging human demonstrations. However, current interfaces for imitation such as kinesthetic teaching or teleoperation prohibitively restrict our ability to efficiently collect large-scale data in the wild. Obtaining such diverse demonstration data is paramount for the generalization of learned skills to novel scenarios. In this work, we present an alternate interface for imitation that simplifies the data collection process while allowing for easy transfer to robots. We use commercially available reacher-grabber assistive tools both as a data collection device and as the robot's end-effector. To extract action information from these visual demonstrations, we use off-the-shelf Structure from Motion (SfM) techniques in addition to training a finger detection network. We experimentally evaluate on two challenging tasks: non-prehensile pushing and prehensile stacking, with 1000 diverse demonstrations for each task. For both tasks, we use standard behavior cloning to learn executable policies from the previously collected offline demonstrations. To improve learning performance, we employ a variety of data augmentations and provide an extensive analysis of its effects. Finally, we demonstrate the utility of our interface by evaluating on real robotic scenarios with previously unseen objects and achieve a 87% success rate on pushing and a 62% success rate on stacking. Robot videos are available at https://dhiraj100892.github.io/Visual-Imitation-Made-Easy.