 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThat Sounds Right: Auditory Self-Supervision for Dynamic Robot Manipulation
Oct 03, 2022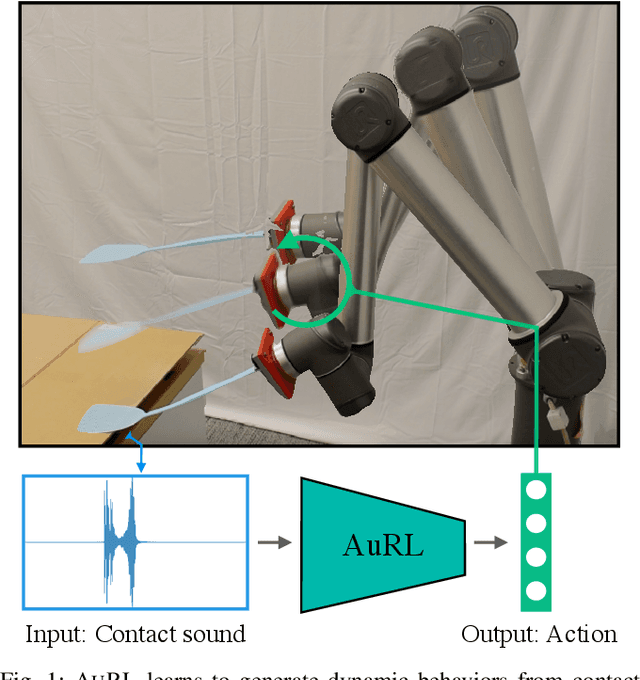

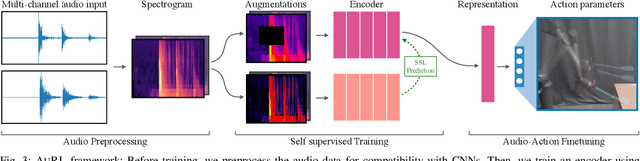
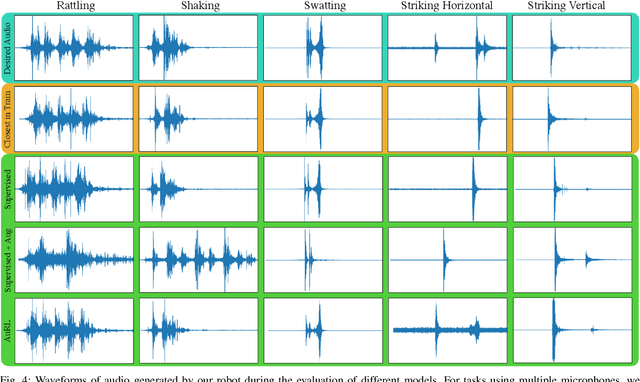
Learning to produce contact-rich, dynamic behaviors from raw sensory data has been a longstanding challenge in robotics. Prominent approaches primarily focus on using visual or tactile sensing, where unfortunately one fails to capture high-frequency interaction, while the other can be too delicate for large-scale data collection. In this work, we propose a data-centric approach to dynamic manipulation that uses an often ignored source of information: sound. We first collect a dataset of 25k interaction-sound pairs across five dynamic tasks using commodity contact microphones. Then, given this data, we leverage self-supervised learning to accelerate behavior prediction from sound. Our experiments indicate that this self-supervised 'pretraining' is crucial to achieving high performance, with a 34.5% lower MSE than plain supervised learning and a 54.3% lower MSE over visual training. Importantly, we find that when asked to generate desired sound profiles, online rollouts of our models on a UR10 robot can produce dynamic behavior that achieves an average of 11.5% improvement over supervised learning on audio similarity metrics.
Human Decision Makings on Curriculum Reinforcement Learning with Difficulty Adjustment
Aug 04, 2022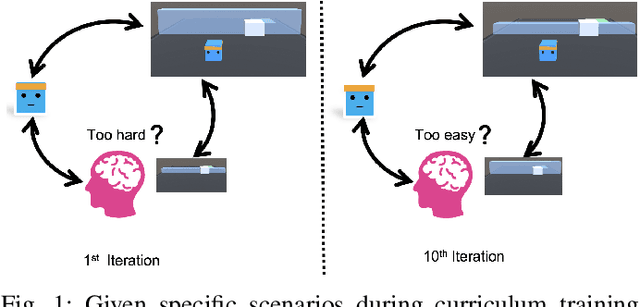
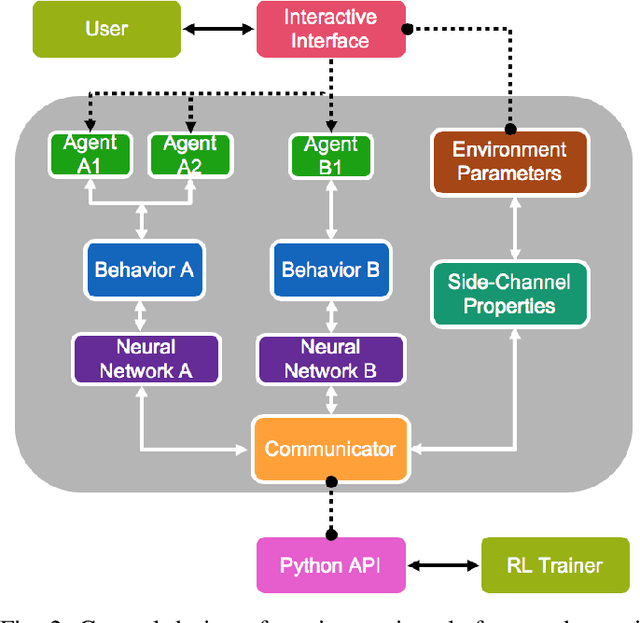
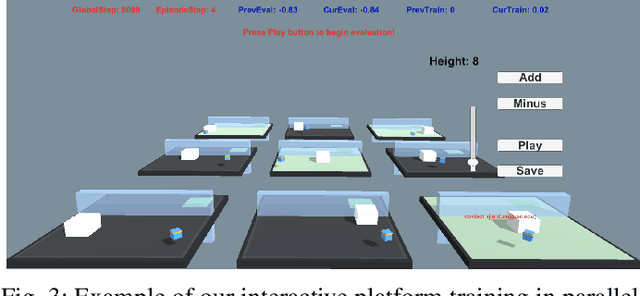
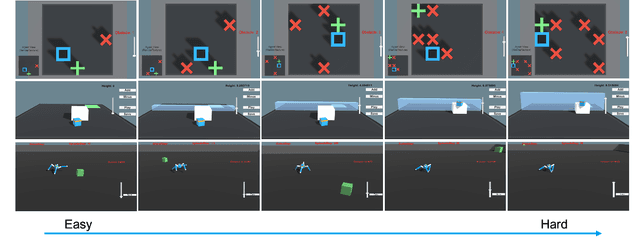
Human-centered AI considers human experiences with AI performance. While abundant research has been helping AI achieve superhuman performance either by fully automatic or weak supervision learning, fewer endeavors are experimenting with how AI can tailor to humans' preferred skill level given fine-grained input. In this work, we guide the curriculum reinforcement learning results towards a preferred performance level that is neither too hard nor too easy via learning from the human decision process. To achieve this, we developed a portable, interactive platform that enables the user to interact with agents online via manipulating the task difficulty, observing performance, and providing curriculum feedback. Our system is highly parallelizable, making it possible for a human to train large-scale reinforcement learning applications that require millions of samples without a server. The result demonstrates the effectiveness of an interactive curriculum for reinforcement learning involving human-in-the-loop. It shows reinforcement learning performance can successfully adjust in sync with the human desired difficulty level. We believe this research will open new doors for achieving flow and personalized adaptive difficulties.
Watch and Match: Supercharging Imitation with Regularized Optimal Transport
Jun 30, 2022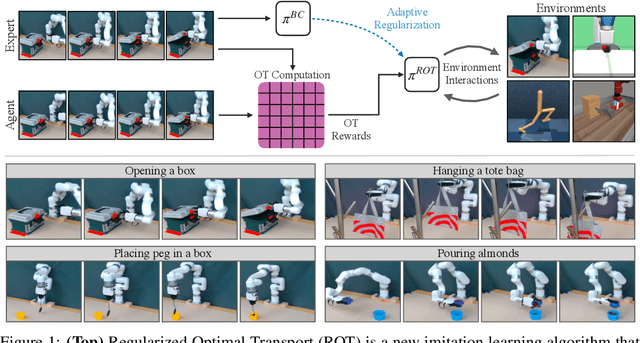
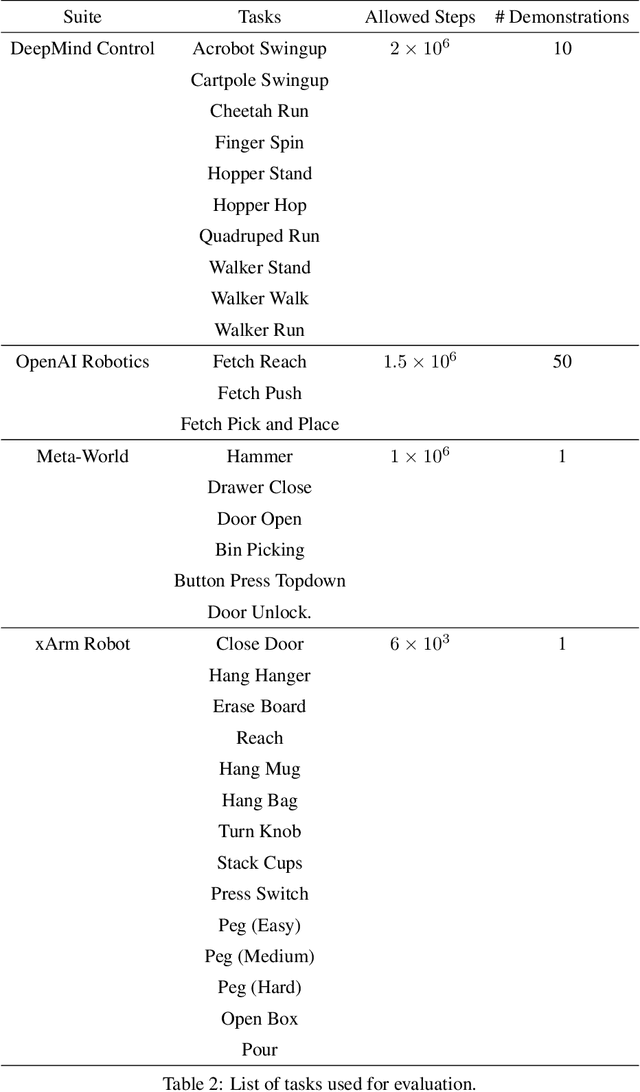
Imitation learning holds tremendous promise in learning policies efficiently for complex decision making problems. Current state-of-the-art algorithms often use inverse reinforcement learning (IRL), where given a set of expert demonstrations, an agent alternatively infers a reward function and the associated optimal policy. However, such IRL approaches often require substantial online interactions for complex control problems. In this work, we present Regularized Optimal Transport (ROT), a new imitation learning algorithm that builds on recent advances in optimal transport based trajectory-matching. Our key technical insight is that adaptively combining trajectory-matching rewards with behavior cloning can significantly accelerate imitation even with only a few demonstrations. Our experiments on 20 visual control tasks across the DeepMind Control Suite, the OpenAI Robotics Suite, and the Meta-World Benchmark demonstrate an average of 7.8X faster imitation to reach 90% of expert performance compared to prior state-of-the-art methods. On real-world robotic manipulation, with just one demonstration and an hour of online training, ROT achieves an average success rate of 90.1% across 14 tasks.
Behavior Transformers: Cloning $k$ modes with one stone
Jun 22, 2022
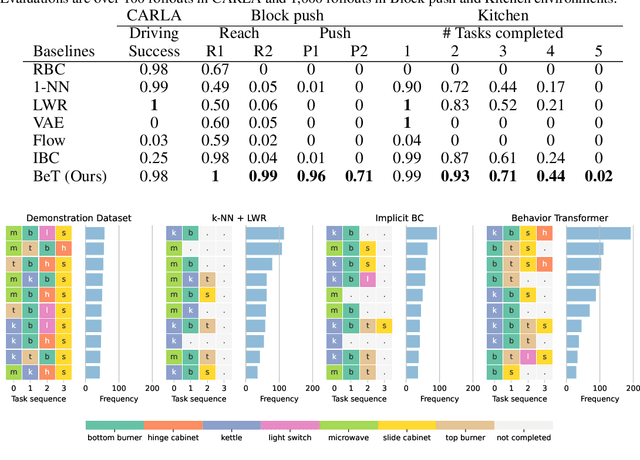
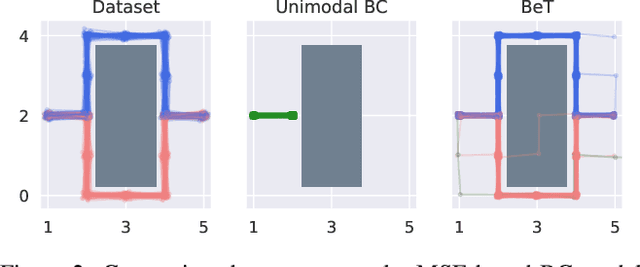
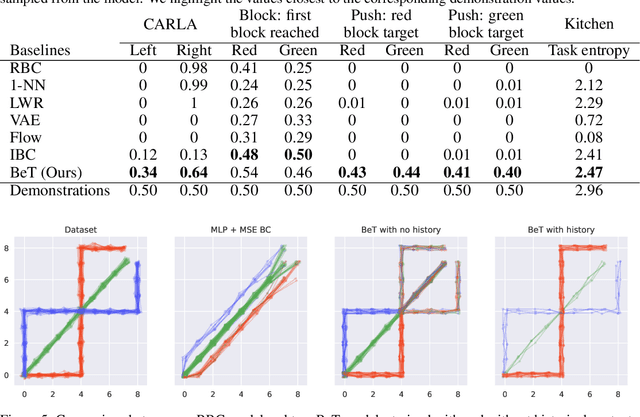
While behavior learning has made impressive progress in recent times, it lags behind computer vision and natural language processing due to its inability to leverage large, human-generated datasets. Human behaviors have wide variance, multiple modes, and human demonstrations typically do not come with reward labels. These properties limit the applicability of current methods in Offline RL and Behavioral Cloning to learn from large, pre-collected datasets. In this work, we present Behavior Transformer (BeT), a new technique to model unlabeled demonstration data with multiple modes. BeT retrofits standard transformer architectures with action discretization coupled with a multi-task action correction inspired by offset prediction in object detection. This allows us to leverage the multi-modal modeling ability of modern transformers to predict multi-modal continuous actions. We experimentally evaluate BeT on a variety of robotic manipulation and self-driving behavior datasets. We show that BeT significantly improves over prior state-of-the-art work on solving demonstrated tasks while capturing the major modes present in the pre-collected datasets. Finally, through an extensive ablation study, we analyze the importance of every crucial component in BeT. Videos of behavior generated by BeT are available at https://notmahi.github.io/bet
Dexterous Imitation Made Easy: A Learning-Based Framework for Efficient Dexterous Manipulation
Mar 24, 2022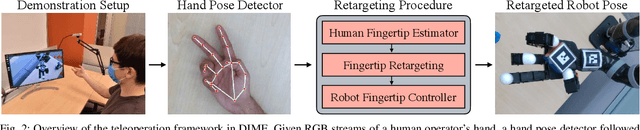

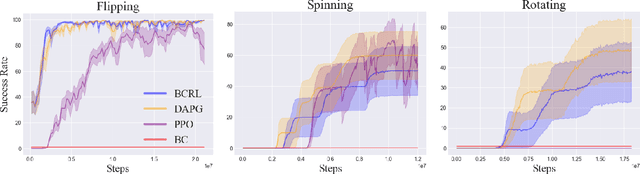

Optimizing behaviors for dexterous manipulation has been a longstanding challenge in robotics, with a variety of methods from model-based control to model-free reinforcement learning having been previously explored in literature. Perhaps one of the most powerful techniques to learn complex manipulation strategies is imitation learning. However, collecting and learning from demonstrations in dexterous manipulation is quite challenging. The complex, high-dimensional action-space involved with multi-finger control often leads to poor sample efficiency of learning-based methods. In this work, we propose 'Dexterous Imitation Made Easy' (DIME) a new imitation learning framework for dexterous manipulation. DIME only requires a single RGB camera to observe a human operator and teleoperate our robotic hand. Once demonstrations are collected, DIME employs standard imitation learning methods to train dexterous manipulation policies. On both simulation and real robot benchmarks we demonstrate that DIME can be used to solve complex, in-hand manipulation tasks such as 'flipping', 'spinning', and 'rotating' objects with the Allegro hand. Our framework along with pre-collected demonstrations is publicly available at https://nyu-robot-learning.github.io/dime.
One After Another: Learning Incremental Skills for a Changing World
Mar 21, 2022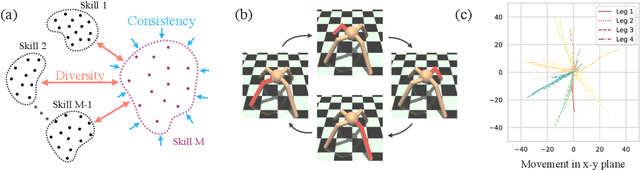
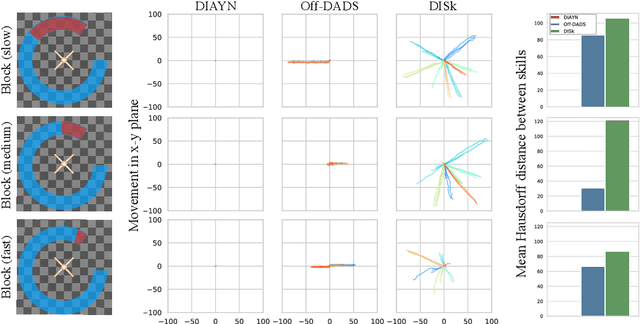
Reward-free, unsupervised discovery of skills is an attractive alternative to the bottleneck of hand-designing rewards in environments where task supervision is scarce or expensive. However, current skill pre-training methods, like many RL techniques, make a fundamental assumption - stationary environments during training. Traditional methods learn all their skills simultaneously, which makes it difficult for them to both quickly adapt to changes in the environment, and to not forget earlier skills after such adaptation. On the other hand, in an evolving or expanding environment, skill learning must be able to adapt fast to new environment situations while not forgetting previously learned skills. These two conditions make it difficult for classic skill discovery to do well in an evolving environment. In this work, we propose a new framework for skill discovery, where skills are learned one after another in an incremental fashion. This framework allows newly learned skills to adapt to new environment or agent dynamics, while the fixed old skills ensure the agent doesn't forget a learned skill. We demonstrate experimentally that in both evolving and static environments, incremental skills significantly outperform current state-of-the-art skill discovery methods on both skill quality and the ability to solve downstream tasks. Videos for learned skills and code are made public on https://notmahi.github.io/disk
RB2: Robotic Manipulation Benchmarking with a Twist
Mar 15, 2022
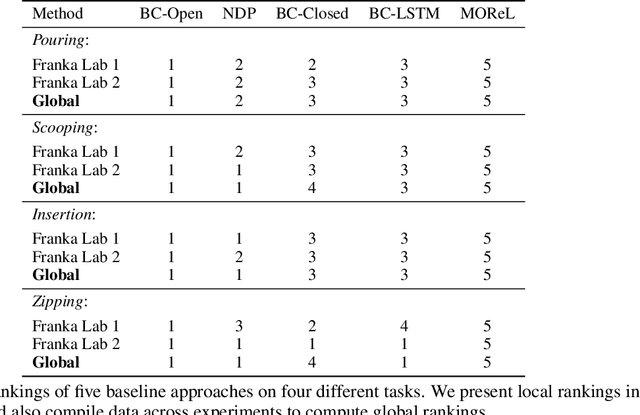


Benchmarks offer a scientific way to compare algorithms using objective performance metrics. Good benchmarks have two features: (a) they should be widely useful for many research groups; (b) and they should produce reproducible findings. In robotic manipulation research, there is a trade-off between reproducibility and broad accessibility. If the benchmark is kept restrictive (fixed hardware, objects), the numbers are reproducible but the setup becomes less general. On the other hand, a benchmark could be a loose set of protocols (e.g. object sets) but the underlying variation in setups make the results non-reproducible. In this paper, we re-imagine benchmarking for robotic manipulation as state-of-the-art algorithmic implementations, alongside the usual set of tasks and experimental protocols. The added baseline implementations will provide a way to easily recreate SOTA numbers in a new local robotic setup, thus providing credible relative rankings between existing approaches and new work. However, these local rankings could vary between different setups. To resolve this issue, we build a mechanism for pooling experimental data between labs, and thus we establish a single global ranking for existing (and proposed) SOTA algorithms. Our benchmark, called Ranking-Based Robotics Benchmark (RB2), is evaluated on tasks that are inspired from clinically validated Southampton Hand Assessment Procedures. Our benchmark was run across two different labs and reveals several surprising findings. For example, extremely simple baselines like open-loop behavior cloning, outperform more complicated models (e.g. closed loop, RNN, Offline-RL, etc.) that are preferred by the field. We hope our fellow researchers will use RB2 to improve their research's quality and rigor.
Context is Everything: Implicit Identification for Dynamics Adaptation
Mar 10, 2022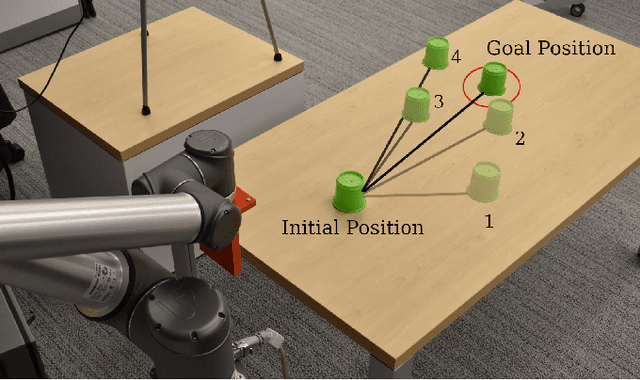
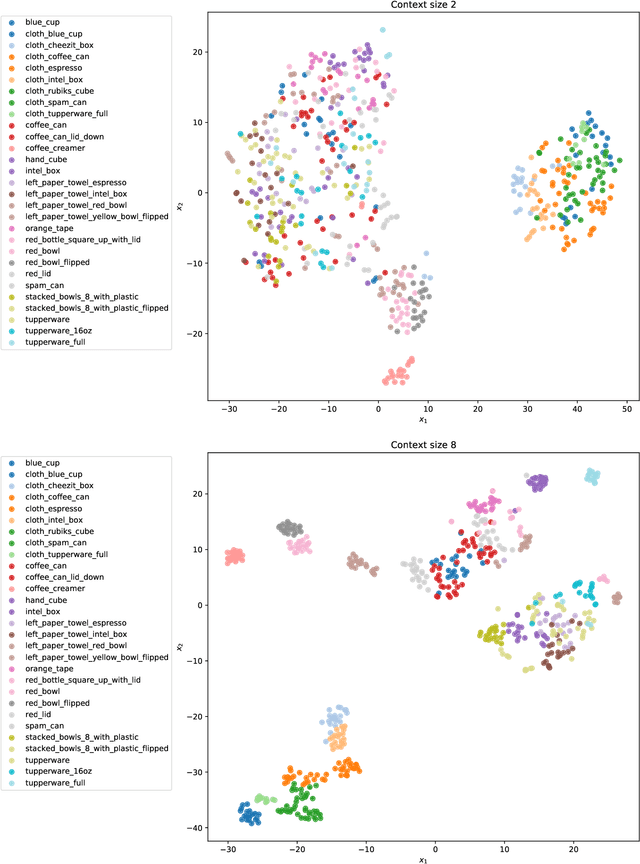
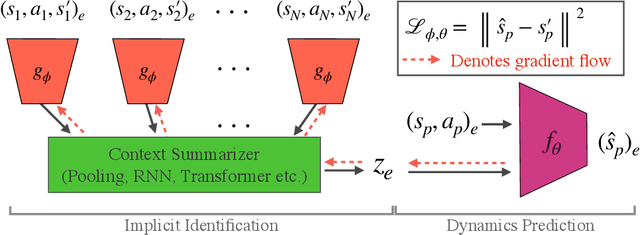

Understanding environment dynamics is necessary for robots to act safely and optimally in the world. In realistic scenarios, dynamics are non-stationary and the causal variables such as environment parameters cannot necessarily be precisely measured or inferred, even during training. We propose Implicit Identification for Dynamics Adaptation (IIDA), a simple method to allow predictive models to adapt to changing environment dynamics. IIDA assumes no access to the true variations in the world and instead implicitly infers properties of the environment from a small amount of contextual data. We demonstrate IIDA's ability to perform well in unseen environments through a suite of simulated experiments on MuJoCo environments and a real robot dynamic sliding task. In general, IIDA significantly reduces model error and results in higher task performance over commonly used methods. Our code and robot videos are at https://bennevans.github.io/iida/
Don't Change the Algorithm, Change the Data: Exploratory Data for Offline Reinforcement Learning
Feb 08, 2022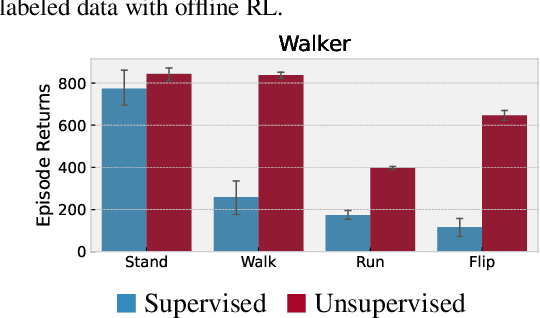
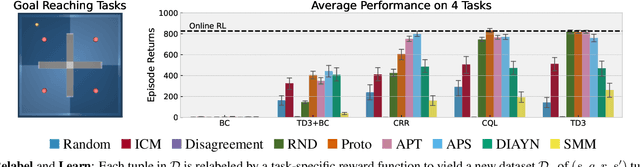
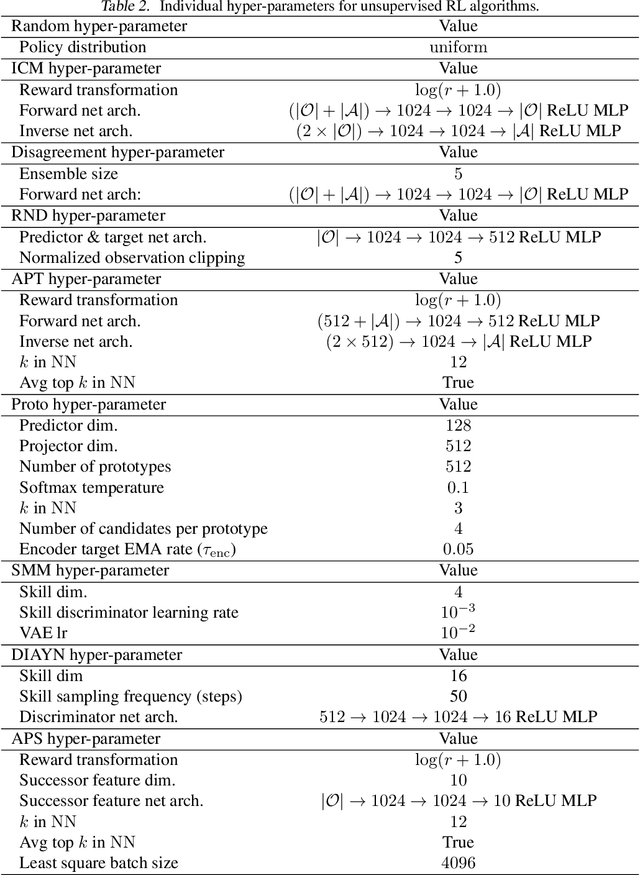
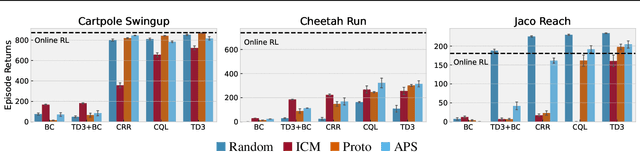
Recent progress in deep learning has relied on access to large and diverse datasets. Such data-driven progress has been less evident in offline reinforcement learning (RL), because offline RL data is usually collected to optimize specific target tasks limiting the data's diversity. In this work, we propose Exploratory data for Offline RL (ExORL), a data-centric approach to offline RL. ExORL first generates data with unsupervised reward-free exploration, then relabels this data with a downstream reward before training a policy with offline RL. We find that exploratory data allows vanilla off-policy RL algorithms, without any offline-specific modifications, to outperform or match state-of-the-art offline RL algorithms on downstream tasks. Our findings suggest that data generation is as important as algorithmic advances for offline RL and hence requires careful consideration from the community. Code and data can be found at https://github.com/denisyarats/exorl .
The Surprising Effectiveness of Representation Learning for Visual Imitation
Dec 06, 2021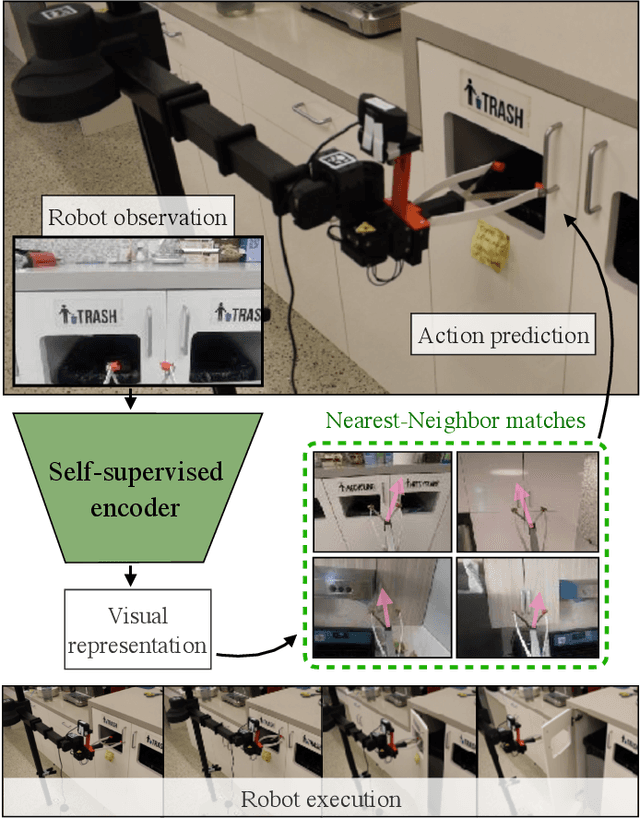
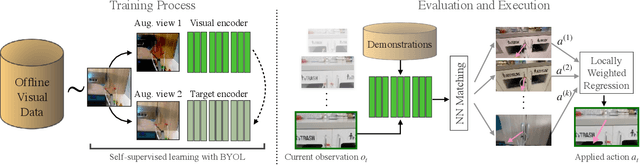

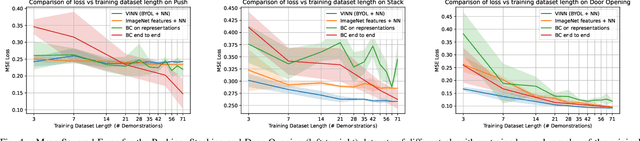
While visual imitation learning offers one of the most effective ways of learning from visual demonstrations, generalizing from them requires either hundreds of diverse demonstrations, task specific priors, or large, hard-to-train parametric models. One reason such complexities arise is because standard visual imitation frameworks try to solve two coupled problems at once: learning a succinct but good representation from the diverse visual data, while simultaneously learning to associate the demonstrated actions with such representations. Such joint learning causes an interdependence between these two problems, which often results in needing large amounts of demonstrations for learning. To address this challenge, we instead propose to decouple representation learning from behavior learning for visual imitation. First, we learn a visual representation encoder from offline data using standard supervised and self-supervised learning methods. Once the representations are trained, we use non-parametric Locally Weighted Regression to predict the actions. We experimentally show that this simple decoupling improves the performance of visual imitation models on both offline demonstration datasets and real-robot door opening compared to prior work in visual imitation. All of our generated data, code, and robot videos are publicly available at https://jyopari.github.io/VINN/.