 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent-Centric Representations for Multi-Agent Reinforcement Learning
Apr 19, 2021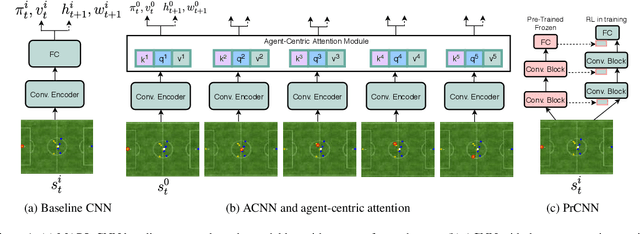

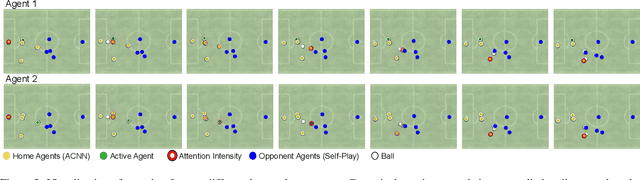

Object-centric representations have recently enabled significant progress in tackling relational reasoning tasks. By building a strong object-centric inductive bias into neural architectures, recent efforts have improved generalization and data efficiency of machine learning algorithms for these problems. One problem class involving relational reasoning that still remains under-explored is multi-agent reinforcement learning (MARL). Here we investigate whether object-centric representations are also beneficial in the fully cooperative MARL setting. Specifically, we study two ways of incorporating an agent-centric inductive bias into our RL algorithm: 1. Introducing an agent-centric attention module with explicit connections across agents 2. Adding an agent-centric unsupervised predictive objective (i.e. not using action labels), to be used as an auxiliary loss for MARL, or as the basis of a pre-training step. We evaluate these approaches on the Google Research Football environment as well as DeepMind Lab 2D. Empirically, agent-centric representation learning leads to the emergence of more complex cooperation strategies between agents as well as enhanced sample efficiency and generalization.
GEM: Group Enhanced Model for Learning Dynamical Control Systems
Apr 07, 2021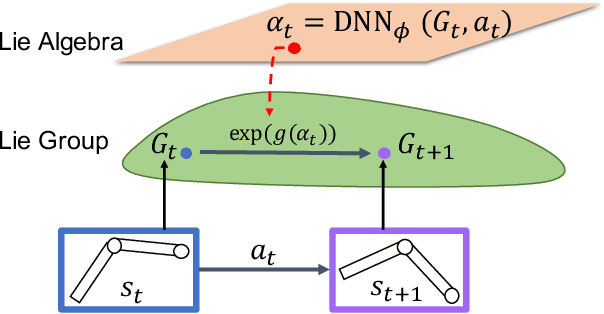
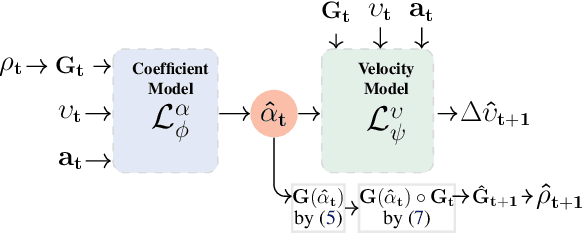
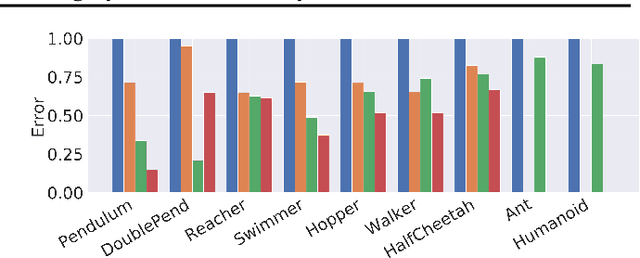
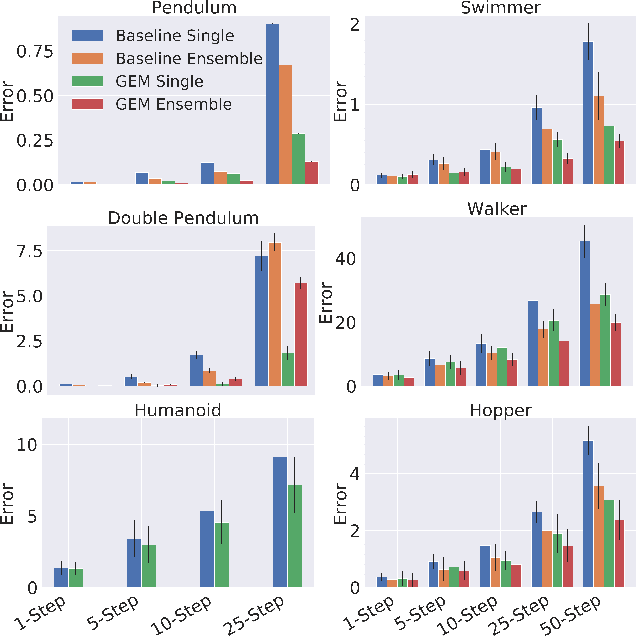
Learning the dynamics of a physical system wherein an autonomous agent operates is an important task. Often these systems present apparent geometric structures. For instance, the trajectories of a robotic manipulator can be broken down into a collection of its transitional and rotational motions, fully characterized by the corresponding Lie groups and Lie algebras. In this work, we take advantage of these structures to build effective dynamical models that are amenable to sample-based learning. We hypothesize that learning the dynamics on a Lie algebra vector space is more effective than learning a direct state transition model. To verify this hypothesis, we introduce the Group Enhanced Model (GEM). GEMs significantly outperform conventional transition models on tasks of long-term prediction, planning, and model-based reinforcement learning across a diverse suite of standard continuous-control environments, including Walker, Hopper, Reacher, Half-Cheetah, Inverted Pendulums, Ant, and Humanoid. Furthermore, plugging GEM into existing state of the art systems enhances their performance, which we demonstrate on the PETS system. This work sheds light on a connection between learning of dynamics and Lie group properties, which opens doors for new research directions and practical applications along this direction. Our code is publicly available at: https://tinyurl.com/GEMMBRL.
Reinforcement Learning with Latent Flow
Jan 06, 2021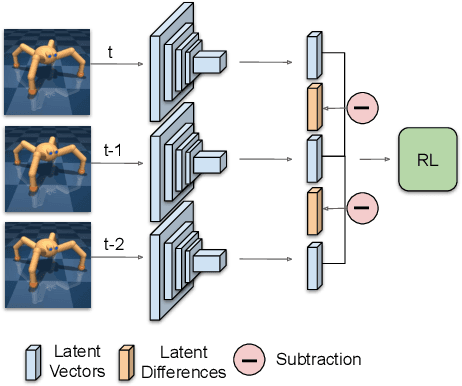

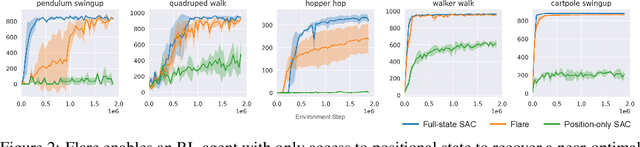

Temporal information is essential to learning effective policies with Reinforcement Learning (RL). However, current state-of-the-art RL algorithms either assume that such information is given as part of the state space or, when learning from pixels, use the simple heuristic of frame-stacking to implicitly capture temporal information present in the image observations. This heuristic is in contrast to the current paradigm in video classification architectures, which utilize explicit encodings of temporal information through methods such as optical flow and two-stream architectures to achieve state-of-the-art performance. Inspired by leading video classification architectures, we introduce the Flow of Latents for Reinforcement Learning (Flare), a network architecture for RL that explicitly encodes temporal information through latent vector differences. We show that Flare (i) recovers optimal performance in state-based RL without explicit access to the state velocity, solely with positional state information, (ii) achieves state-of-the-art performance on pixel-based challenging continuous control tasks within the DeepMind control benchmark suite, namely quadruped walk, hopper hop, finger turn hard, pendulum swing, and walker run, and is the most sample efficient model-free pixel-based RL algorithm, outperforming the prior model-free state-of-the-art by 1.9X and 1.5X on the 500k and 1M step benchmarks, respectively, and (iv), when augmented over rainbow DQN, outperforms this state-of-the-art level baseline on 5 of 8 challenging Atari games at 100M time step benchmark.
Learning World Graphs to Accelerate Hierarchical Reinforcement Learning
Jul 01, 2019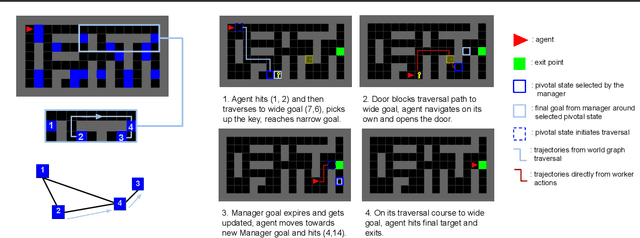
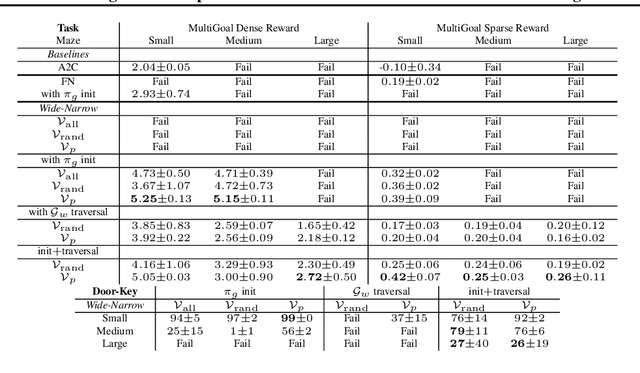
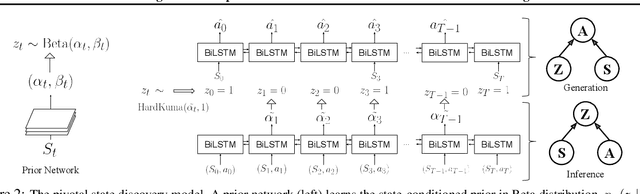
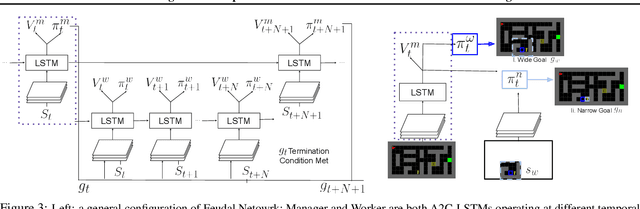
In many real-world scenarios, an autonomous agent often encounters various tasks within a single complex environment. We propose to build a graph abstraction over the environment structure to accelerate the learning of these tasks. Here, nodes are important points of interest (pivotal states) and edges represent feasible traversals between them. Our approach has two stages. First, we jointly train a latent pivotal state model and a curiosity-driven goal-conditioned policy in a task-agnostic manner. Second, provided with the information from the world graph, a high-level Manager quickly finds solution to new tasks and expresses subgoals in reference to pivotal states to a low-level Worker. The Worker can then also leverage the graph to easily traverse to the pivotal states of interest, even across long distance, and explore non-locally. We perform a thorough ablation study to evaluate our approach on a suite of challenging maze tasks, demonstrating significant advantages from the proposed framework over baselines that lack world graph knowledge in terms of performance and efficiency.
Channel-Recurrent Autoencoding for Image Modeling
Mar 11, 2018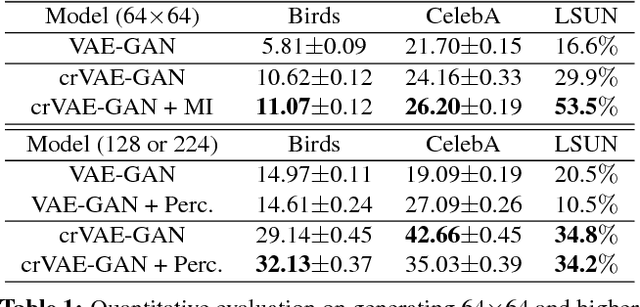
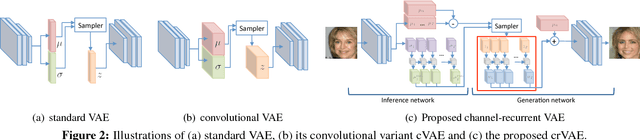
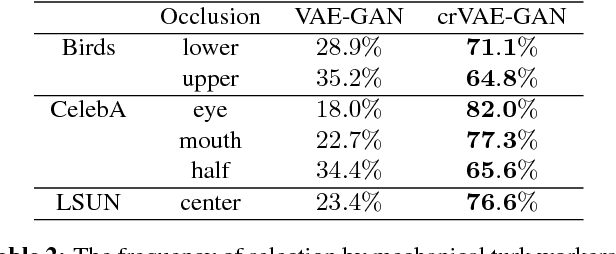

Despite recent successes in synthesizing faces and bedrooms, existing generative models struggle to capture more complex image types, potentially due to the oversimplification of their latent space constructions. To tackle this issue, building on Variational Autoencoders (VAEs), we integrate recurrent connections across channels to both inference and generation steps, allowing the high-level features to be captured in global-to-local, coarse-to-fine manners. Combined with adversarial loss, our channel-recurrent VAE-GAN (crVAE-GAN) outperforms VAE-GAN in generating a diverse spectrum of high resolution images while maintaining the same level of computational efficacy. Our model produces interpretable and expressive latent representations to benefit downstream tasks such as image completion. Moreover, we propose two novel regularizations, namely the KL objective weighting scheme over time steps and mutual information maximization between transformed latent variables and the outputs, to enhance the training.
ELF: An Extensive, Lightweight and Flexible Research Platform for Real-time Strategy Games
Nov 10, 2017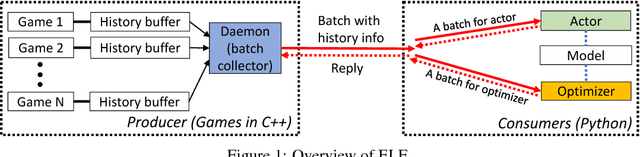
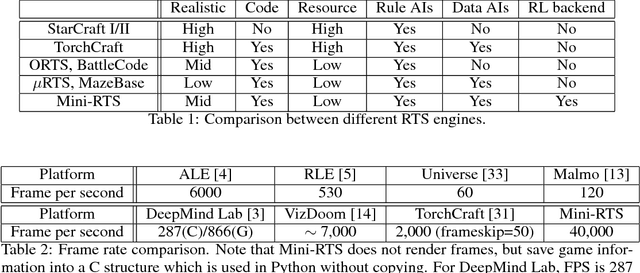
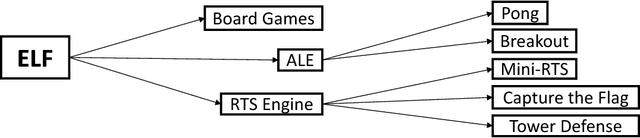
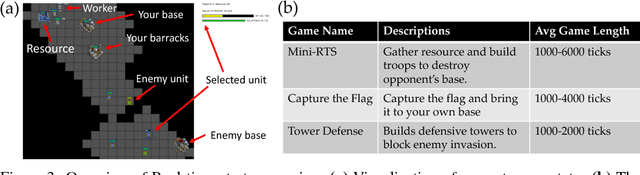
In this paper, we propose ELF, an Extensive, Lightweight and Flexible platform for fundamental reinforcement learning research. Using ELF, we implement a highly customizable real-time strategy (RTS) engine with three game environments (Mini-RTS, Capture the Flag and Tower Defense). Mini-RTS, as a miniature version of StarCraft, captures key game dynamics and runs at 40K frame-per-second (FPS) per core on a Macbook Pro notebook. When coupled with modern reinforcement learning methods, the system can train a full-game bot against built-in AIs end-to-end in one day with 6 CPUs and 1 GPU. In addition, our platform is flexible in terms of environment-agent communication topologies, choices of RL methods, changes in game parameters, and can host existing C/C++-based game environments like Arcade Learning Environment. Using ELF, we thoroughly explore training parameters and show that a network with Leaky ReLU and Batch Normalization coupled with long-horizon training and progressive curriculum beats the rule-based built-in AI more than $70\%$ of the time in the full game of Mini-RTS. Strong performance is also achieved on the other two games. In game replays, we show our agents learn interesting strategies. ELF, along with its RL platform, is open-sourced at https://github.com/facebookresearch/ELF.
Understanding and Improving Convolutional Neural Networks via Concatenated Rectified Linear Units
Jul 19, 2016
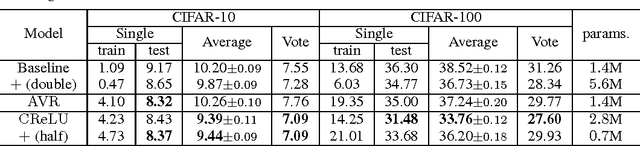
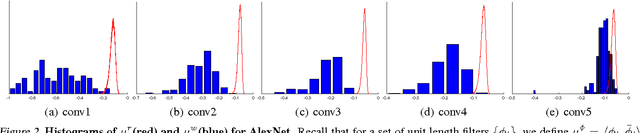

Recently, convolutional neural networks (CNNs) have been used as a powerful tool to solve many problems of machine learning and computer vision. In this paper, we aim to provide insight on the property of convolutional neural networks, as well as a generic method to improve the performance of many CNN architectures. Specifically, we first examine existing CNN models and observe an intriguing property that the filters in the lower layers form pairs (i.e., filters with opposite phase). Inspired by our observation, we propose a novel, simple yet effective activation scheme called concatenated ReLU (CRelu) and theoretically analyze its reconstruction property in CNNs. We integrate CRelu into several state-of-the-art CNN architectures and demonstrate improvement in their recognition performance on CIFAR-10/100 and ImageNet datasets with fewer trainable parameters. Our results suggest that better understanding of the properties of CNNs can lead to significant performance improvement with a simple modification.