 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA MARL Based Multi-Target Tracking Algorithm Under Jamming Against Radar
Dec 17, 2024



Unmanned aerial vehicles (UAVs) have played an increasingly important role in military operations and social life. Among all application scenarios, multi-target tracking tasks accomplished by UAV swarms have received extensive attention. However, when UAVs use radar to track targets, the tracking performance can be severely compromised by jammers. To track targets in the presence of jammers, UAVs can use passive radar to position the jammer. This paper proposes a system where a UAV swarm selects the radar's active or passive work mode to track multiple differently located and potentially jammer-carrying targets. After presenting the optimization problem and proving its solving difficulty, we use a multi-agent reinforcement learning algorithm to solve this control problem. We also propose a mechanism based on simulated annealing algorithm to avoid cases where UAV actions violate constraints. Simulation experiments demonstrate the effectiveness of the proposed algorithm.
Attention-driven GUI Grounding: Leveraging Pretrained Multimodal Large Language Models without Fine-Tuning
Dec 14, 2024



Recent advancements in Multimodal Large Language Models (MLLMs) have generated significant interest in their ability to autonomously interact with and interpret Graphical User Interfaces (GUIs). A major challenge in these systems is grounding-accurately identifying critical GUI components such as text or icons based on a GUI image and a corresponding text query. Traditionally, this task has relied on fine-tuning MLLMs with specialized training data to predict component locations directly. However, in this paper, we propose a novel Tuning-free Attention-driven Grounding (TAG) method that leverages the inherent attention patterns in pretrained MLLMs to accomplish this task without the need for additional fine-tuning. Our method involves identifying and aggregating attention maps from specific tokens within a carefully constructed query prompt. Applied to MiniCPM-Llama3-V 2.5, a state-of-the-art MLLM, our tuning-free approach achieves performance comparable to tuning-based methods, with notable success in text localization. Additionally, we demonstrate that our attention map-based grounding technique significantly outperforms direct localization predictions from MiniCPM-Llama3-V 2.5, highlighting the potential of using attention maps from pretrained MLLMs and paving the way for future innovations in this domain.
TrendSim: Simulating Trending Topics in Social Media Under Poisoning Attacks with LLM-based Multi-agent System
Dec 14, 2024



Trending topics have become a significant part of modern social media, attracting users to participate in discussions of breaking events. However, they also bring in a new channel for poisoning attacks, resulting in negative impacts on society. Therefore, it is urgent to study this critical problem and develop effective strategies for defense. In this paper, we propose TrendSim, an LLM-based multi-agent system to simulate trending topics in social media under poisoning attacks. Specifically, we create a simulation environment for trending topics that incorporates a time-aware interaction mechanism, centralized message dissemination, and an interactive system. Moreover, we develop LLM-based human-like agents to simulate users in social media, and propose prototype-based attackers to replicate poisoning attacks. Besides, we evaluate TrendSim from multiple aspects to validate its effectiveness. Based on TrendSim, we conduct simulation experiments to study four critical problems about poisoning attacks on trending topics for social benefit.
CharacterBox: Evaluating the Role-Playing Capabilities of LLMs in Text-Based Virtual Worlds
Dec 07, 2024



Role-playing is a crucial capability of Large Language Models (LLMs), enabling a wide range of practical applications, including intelligent non-player characters, digital twins, and emotional companions. Evaluating this capability in LLMs is challenging due to the complex dynamics involved in role-playing, such as maintaining character fidelity throughout a storyline and navigating open-ended narratives without a definitive ground truth. Current evaluation methods, which primarily focus on question-answering or conversational snapshots, fall short of adequately capturing the nuanced character traits and behaviors essential for authentic role-playing. In this paper, we propose CharacterBox, which is a simulation sandbox designed to generate situational fine-grained character behavior trajectories. These behavior trajectories enable a more comprehensive and in-depth evaluation of role-playing capabilities. CharacterBox consists of two main components: the character agent and the narrator agent. The character agent, grounded in psychological and behavioral science, exhibits human-like behaviors, while the narrator agent coordinates interactions between character agents and environmental changes. Additionally, we introduce two trajectory-based methods that leverage CharacterBox to enhance LLM performance. To reduce costs and facilitate the adoption of CharacterBox by public communities, we fine-tune two smaller models, CharacterNR and CharacterRM, as substitutes for GPT API calls, and demonstrate their competitive performance compared to advanced GPT APIs.
Synergistic Development of Perovskite Memristors and Algorithms for Robust Analog Computing
Dec 03, 2024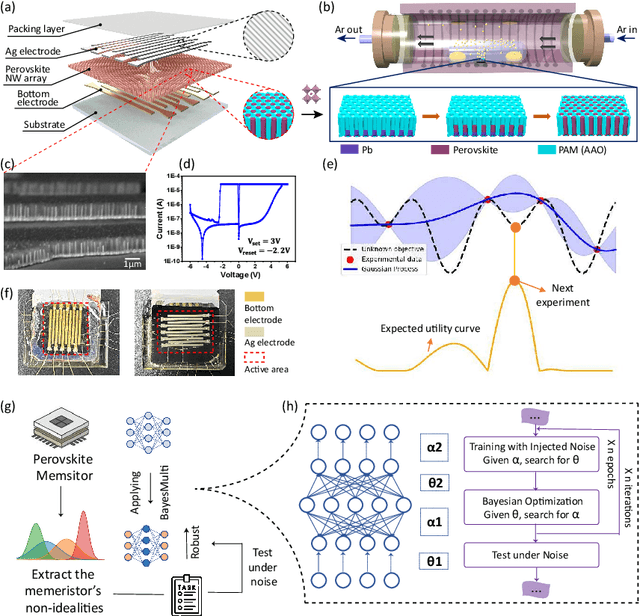

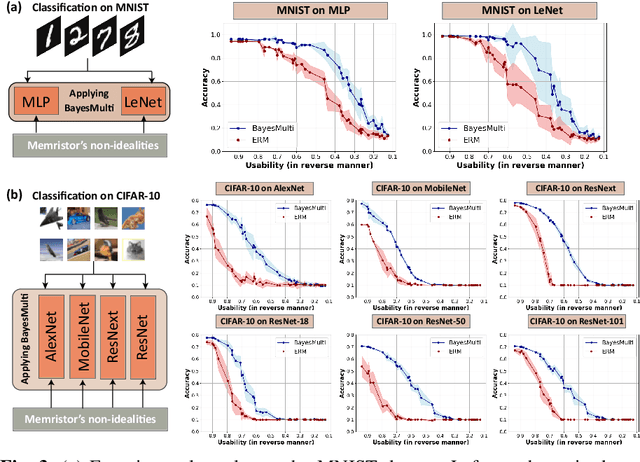
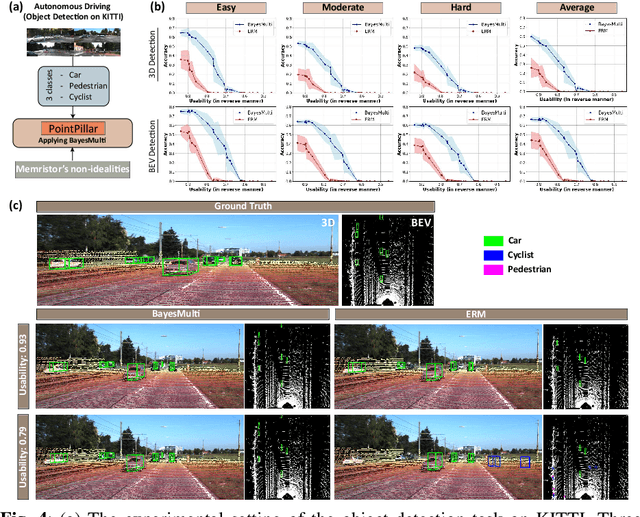
Analog computing using non-volatile memristors has emerged as a promising solution for energy-efficient deep learning. New materials, like perovskites-based memristors are recently attractive due to their cost-effectiveness, energy efficiency and flexibility. Yet, challenges in material diversity and immature fabrications require extensive experimentation for device development. Moreover, significant non-idealities in these memristors often impede them for computing. Here, we propose a synergistic methodology to concurrently optimize perovskite memristor fabrication and develop robust analog DNNs that effectively address the inherent non-idealities of these memristors. Employing Bayesian optimization (BO) with a focus on usability, we efficiently identify optimal materials and fabrication conditions for perovskite memristors. Meanwhile, we developed "BayesMulti", a DNN training strategy utilizing BO-guided noise injection to improve the resistance of analog DNNs to memristor imperfections. Our approach theoretically ensures that within a certain range of parameter perturbations due to memristor non-idealities, the prediction outcomes remain consistent. Our integrated approach enables use of analog computing in much deeper and wider networks, which significantly outperforms existing methods in diverse tasks like image classification, autonomous driving, species identification, and large vision-language models, achieving up to 100-fold improvements. We further validate our methodology on a 10$\times$10 optimized perovskite memristor crossbar, demonstrating high accuracy in a classification task and low energy consumption. This study offers a versatile solution for efficient optimization of various analog computing systems, encompassing both devices and algorithms.
Bridging the Gap: Aligning Text-to-Image Diffusion Models with Specific Feedback
Nov 28, 2024Learning from feedback has been shown to enhance the alignment between text prompts and images in text-to-image diffusion models. However, due to the lack of focus in feedback content, especially regarding the object type and quantity, these techniques struggle to accurately match text and images when faced with specified prompts. To address this issue, we propose an efficient fine-turning method with specific reward objectives, including three stages. First, generated images from diffusion model are detected to obtain the object categories and quantities. Meanwhile, the confidence of category and quantity can be derived from the detection results and given prompts. Next, we define a novel matching score, based on above confidence, to measure text-image alignment. It can guide the model for feedback learning in the form of a reward function. Finally, we fine-tune the diffusion model by backpropagation the reward function gradients to generate semantically related images. Different from previous feedbacks that focus more on overall matching, we place more emphasis on the accuracy of entity categories and quantities. Besides, we construct a text-to-image dataset for studying the compositional generation, including 1.7 K pairs of text-image with diverse combinations of entities and quantities. Experimental results on this benchmark show that our model outperforms other SOTA methods in both alignment and fidelity. In addition, our model can also serve as a metric for evaluating text-image alignment in other models. All code and dataset are available at https://github.com/kingniu0329/Visions.
ER2Score: LLM-based Explainable and Customizable Metric for Assessing Radiology Reports with Reward-Control Loss
Nov 26, 2024



Automated radiology report generation (R2Gen) has advanced significantly, introducing challenges in accurate evaluation due to its complexity. Traditional metrics often fall short by relying on rigid word-matching or focusing only on pathological entities, leading to inconsistencies with human assessments. To bridge this gap, we introduce ER2Score, an automatic evaluation metric designed specifically for R2Gen. Our metric utilizes a reward model, guided by our margin-based reward enforcement loss, along with a tailored training data design that enables customization of evaluation criteria to suit user-defined needs. It not only scores reports according to user-specified criteria but also provides detailed sub-scores, enhancing interpretability and allowing users to adjust the criteria between different aspects of reports. Leveraging GPT-4, we designed an easy-to-use data generation pipeline, enabling us to produce extensive training data based on two distinct scoring systems, each containing reports of varying quality along with corresponding scores. These GPT-generated reports are then paired as accepted and rejected samples through our pairing rule to train an LLM towards our fine-grained reward model, which assigns higher rewards to the report with high quality. Our reward-control loss enables this model to simultaneously output multiple individual rewards corresponding to the number of evaluation criteria, with their summation as our final ER2Score. Our experiments demonstrate ER2Score's heightened correlation with human judgments and superior performance in model selection compared to traditional metrics. Notably, our model provides both an overall score and individual scores for each evaluation item, enhancing interpretability. We also demonstrate its flexible training across various evaluation systems.
A Method for Building Large Language Models with Predefined KV Cache Capacity
Nov 24, 2024
This paper proposes a method for building large language models with predefined Key-Value (KV) cache capacity, particularly suitable for the attention layers in Transformer decode-only architectures. This method introduces fixed-length KV caches to address the issue of excessive memory consumption in traditional KV caches when handling infinite contexts. By dynamically updating the key-value vector sequences, it achieves efficient inference within limited cache capacity, significantly reducing memory usage while maintaining model performance and system throughput. Experimental results show that this method significantly reduces memory usage while maintaining the model's inference quality.
When Spatial meets Temporal in Action Recognition
Nov 22, 2024



Video action recognition has made significant strides, but challenges remain in effectively using both spatial and temporal information. While existing methods often focus on either spatial features (e.g., object appearance) or temporal dynamics (e.g., motion), they rarely address the need for a comprehensive integration of both. Capturing the rich temporal evolution of video frames, while preserving their spatial details, is crucial for improving accuracy. In this paper, we introduce the Temporal Integration and Motion Enhancement (TIME) layer, a novel preprocessing technique designed to incorporate temporal information. The TIME layer generates new video frames by rearranging the original sequence, preserving temporal order while embedding $N^2$ temporally evolving frames into a single spatial grid of size $N \times N$. This transformation creates new frames that balance both spatial and temporal information, making them compatible with existing video models. When $N=1$, the layer captures rich spatial details, similar to existing methods. As $N$ increases ($N\geq2$), temporal information becomes more prominent, while the spatial information decreases to ensure compatibility with model inputs. We demonstrate the effectiveness of the TIME layer by integrating it into popular action recognition models, such as ResNet-50, Vision Transformer, and Video Masked Autoencoders, for both RGB and depth video data. Our experiments show that the TIME layer enhances recognition accuracy, offering valuable insights for video processing tasks.
LoRA-FAIR: Federated LoRA Fine-Tuning with Aggregation and Initialization Refinement
Nov 22, 2024



Foundation models (FMs) achieve strong performance across diverse tasks with task-specific fine-tuning, yet full parameter fine-tuning is often computationally prohibitive for large models. Parameter-efficient fine-tuning (PEFT) methods like Low-Rank Adaptation (LoRA) reduce this cost by introducing low-rank matrices for tuning fewer parameters. While LoRA allows for efficient fine-tuning, it requires significant data for adaptation, making Federated Learning (FL) an appealing solution due to its privacy-preserving collaborative framework. However, combining LoRA with FL introduces two key challenges: the \textbf{Server-Side LoRA Aggregation Bias}, where server-side averaging of LoRA matrices diverges from the ideal global update, and the \textbf{Client-Side LoRA Initialization Drift}, emphasizing the need for consistent initialization across rounds. Existing approaches address these challenges individually, limiting their effectiveness. We propose LoRA-FAIR, a novel method that tackles both issues by introducing a correction term on the server while keeping the original LoRA modules, enhancing aggregation efficiency and accuracy. LoRA-FAIR maintains computational and communication efficiency, yielding superior performance over state-of-the-art methods. Experimental results on ViT and MLP-Mixer models across large-scale datasets demonstrate that LoRA-FAIR consistently achieves performance improvements in FL settings.