 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCAR: A Characterization Scheme for Multi-Modal Dataset
Aug 27, 2025Foundation models exhibit remarkable generalization across diverse tasks, largely driven by the characteristics of their training data. Recent data-centric methods like pruning and compression aim to optimize training but offer limited theoretical insight into how data properties affect generalization, especially the data characteristics in sample scaling. Traditional perspectives further constrain progress by focusing predominantly on data quantity and training efficiency, often overlooking structural aspects of data quality. In this study, we introduce SCAR, a principled scheme for characterizing the intrinsic structural properties of datasets across four key measures: Scale, Coverage, Authenticity, and Richness. Unlike prior data-centric measures, SCAR captures stable characteristics that remain invariant under dataset scaling, providing a robust and general foundation for data understanding. Leveraging these structural properties, we introduce Foundation Data-a minimal subset that preserves the generalization behavior of the full dataset without requiring model-specific retraining. We model single-modality tasks as step functions and estimate the distribution of the foundation data size to capture step-wise generalization bias across modalities in the target multi-modal dataset. Finally, we develop a SCAR-guided data completion strategy based on this generalization bias, which enables efficient, modality-aware expansion of modality-specific characteristics in multimodal datasets. Experiments across diverse multi-modal datasets and model architectures validate the effectiveness of SCAR in predicting data utility and guiding data acquisition. Code is available at https://github.com/McAloma/SCAR.
Beyond Tokens: Enhancing RTL Quality Estimation via Structural Graph Learning
Aug 26, 2025



Estimating the quality of register transfer level (RTL) designs is crucial in the electronic design automation (EDA) workflow, as it enables instant feedback on key metrics like area and delay without the need for time-consuming logic synthesis. While recent approaches have leveraged large language models (LLMs) to derive embeddings from RTL code and achieved promising results, they overlook the structural semantics essential for accurate quality estimation. In contrast, the control data flow graph (CDFG) view exposes the design's structural characteristics more explicitly, offering richer cues for representation learning. In this work, we introduce a novel structure-aware graph self-supervised learning framework, StructRTL, for improved RTL design quality estimation. By learning structure-informed representations from CDFGs, our method significantly outperforms prior art on various quality estimation tasks. To further boost performance, we incorporate a knowledge distillation strategy that transfers low-level insights from post-mapping netlists into the CDFG predictor. Experiments show that our approach establishes new state-of-the-art results, demonstrating the effectiveness of combining structural learning with cross-stage supervision.
LGE-Guided Cross-Modality Contrastive Learning for Gadolinium-Free Cardiomyopathy Screening in Cine CMR
Aug 23, 2025Cardiomyopathy, a principal contributor to heart failure and sudden cardiac mortality, demands precise early screening. Cardiac Magnetic Resonance (CMR), recognized as the diagnostic 'gold standard' through multiparametric protocols, holds the potential to serve as an accurate screening tool. However, its reliance on gadolinium contrast and labor-intensive interpretation hinders population-scale deployment. We propose CC-CMR, a Contrastive Learning and Cross-Modal alignment framework for gadolinium-free cardiomyopathy screening using cine CMR sequences. By aligning the latent spaces of cine CMR and Late Gadolinium Enhancement (LGE) sequences, our model encodes fibrosis-specific pathology into cine CMR embeddings. A Feature Interaction Module concurrently optimizes diagnostic precision and cross-modal feature congruence, augmented by an uncertainty-guided adaptive training mechanism that dynamically calibrates task-specific objectives to ensure model generalizability. Evaluated on multi-center data from 231 subjects, CC-CMR achieves accuracy of 0.943 (95% CI: 0.886-0.986), outperforming state-of-the-art cine-CMR-only models by 4.3% while eliminating gadolinium dependency, demonstrating its clinical viability for wide range of populations and healthcare environments.
ELF: Efficient Logic Synthesis by Pruning Redundancy in Refactoring
Aug 11, 2025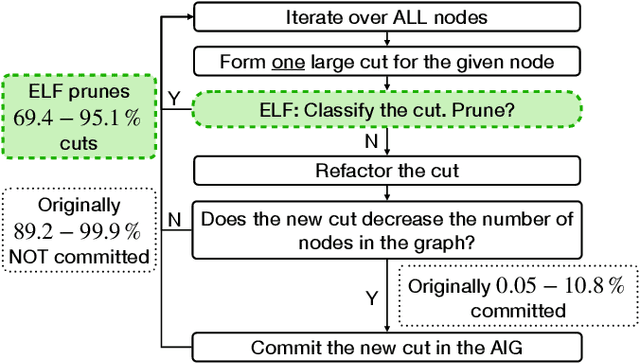
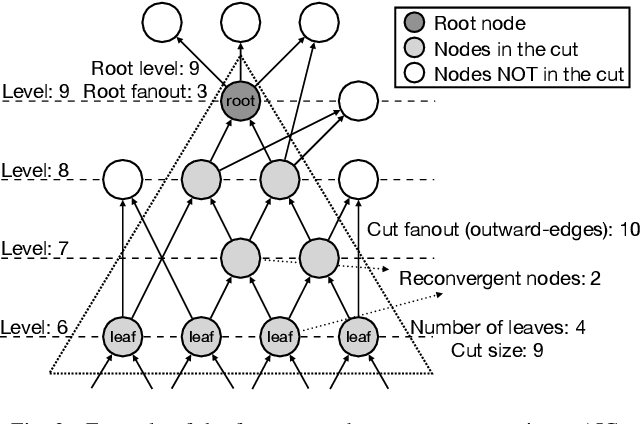
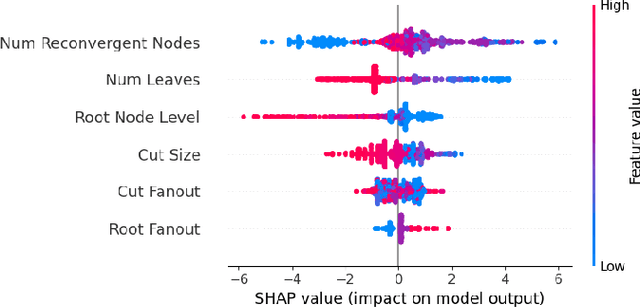
In electronic design automation, logic optimization operators play a crucial role in minimizing the gate count of logic circuits. However, their computation demands are high. Operators such as refactor conventionally form iterative cuts for each node, striving for a more compact representation - a task which often fails 98% on average. Prior research has sought to mitigate computational cost through parallelization. In contrast, our approach leverages a classifier to prune unsuccessful cuts preemptively, thus eliminating unnecessary resynthesis operations. Experiments on the refactor operator using the EPFL benchmark suite and 10 large industrial designs demonstrate that this technique can speedup logic optimization by 3.9x on average compared with the state-of-the-art ABC implementation.
Lightweight Multi-Scale Feature Extraction with Fully Connected LMF Layer for Salient Object Detection
Aug 10, 2025



In the domain of computer vision, multi-scale feature extraction is vital for tasks such as salient object detection. However, achieving this capability in lightweight networks remains challenging due to the trade-off between efficiency and performance. This paper proposes a novel lightweight multi-scale feature extraction layer, termed the LMF layer, which employs depthwise separable dilated convolutions in a fully connected structure. By integrating multiple LMF layers, we develop LMFNet, a lightweight network tailored for salient object detection. Our approach significantly reduces the number of parameters while maintaining competitive performance. Here, we show that LMFNet achieves state-of-the-art or comparable results on five benchmark datasets with only 0.81M parameters, outperforming several traditional and lightweight models in terms of both efficiency and accuracy. Our work not only addresses the challenge of multi-scale learning in lightweight networks but also demonstrates the potential for broader applications in image processing tasks. The related code files are available at https://github.com/Shi-Yun-peng/LMFNet
DocTron-Formula: Generalized Formula Recognition in Complex and Structured Scenarios
Aug 01, 2025

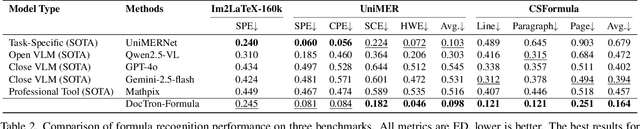
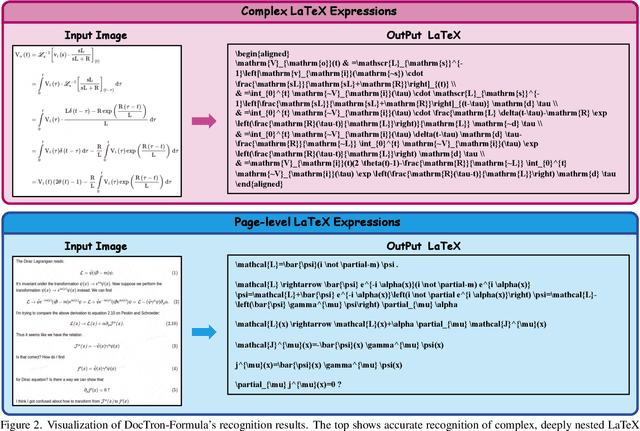
Optical Character Recognition (OCR) for mathematical formula is essential for the intelligent analysis of scientific literature. However, both task-specific and general vision-language models often struggle to handle the structural diversity, complexity, and real-world variability inherent in mathematical content. In this work, we present DocTron-Formula, a unified framework built upon general vision-language models, thereby eliminating the need for specialized architectures. Furthermore, we introduce CSFormula, a large-scale and challenging dataset that encompasses multidisciplinary and structurally complex formulas at the line, paragraph, and page levels. Through straightforward supervised fine-tuning, our approach achieves state-of-the-art performance across a variety of styles, scientific domains, and complex layouts. Experimental results demonstrate that our method not only surpasses specialized models in terms of accuracy and robustness, but also establishes a new paradigm for the automated understanding of complex scientific documents.
Self-Guided Process Reward Optimization with Redefined Step-wise Advantage for Process Reinforcement Learning
Jul 03, 2025Process Reinforcement Learning~(PRL) has demonstrated considerable potential in enhancing the reasoning capabilities of Large Language Models~(LLMs). However, introducing additional process reward models incurs substantial computational overhead, and there is no unified theoretical framework for process-level advantage estimation. To bridge this gap, we propose \textbf{S}elf-Guided \textbf{P}rocess \textbf{R}eward \textbf{O}ptimization~(\textbf{SPRO}), a novel framework that enables process-aware RL through two key innovations: (1) we first theoretically demonstrate that process rewards can be derived intrinsically from the policy model itself, and (2) we introduce well-defined cumulative process rewards and \textbf{M}asked \textbf{S}tep \textbf{A}dvantage (\textbf{MSA}), which facilitates rigorous step-wise action advantage estimation within shared-prompt sampling groups. Our experimental results demonstrate that SPRO outperforms vaniila GRPO with 3.4x higher training efficiency and a 17.5\% test accuracy improvement. Furthermore, SPRO maintains a stable and elevated policy entropy throughout training while reducing the average response length by approximately $1/3$, evidencing sufficient exploration and prevention of reward hacking. Notably, SPRO incurs no additional computational overhead compared to outcome-supervised RL methods such as GRPO, which benefit industrial implementation.
Leader360V: The Large-scale, Real-world 360 Video Dataset for Multi-task Learning in Diverse Environment
Jun 17, 2025360 video captures the complete surrounding scenes with the ultra-large field of view of 360X180. This makes 360 scene understanding tasks, eg, segmentation and tracking, crucial for appications, such as autonomous driving, robotics. With the recent emergence of foundation models, the community is, however, impeded by the lack of large-scale, labelled real-world datasets. This is caused by the inherent spherical properties, eg, severe distortion in polar regions, and content discontinuities, rendering the annotation costly yet complex. This paper introduces Leader360V, the first large-scale, labeled real-world 360 video datasets for instance segmentation and tracking. Our datasets enjoy high scene diversity, ranging from indoor and urban settings to natural and dynamic outdoor scenes. To automate annotation, we design an automatic labeling pipeline, which subtly coordinates pre-trained 2D segmentors and large language models to facilitate the labeling. The pipeline operates in three novel stages. Specifically, in the Initial Annotation Phase, we introduce a Semantic- and Distortion-aware Refinement module, which combines object mask proposals from multiple 2D segmentors with LLM-verified semantic labels. These are then converted into mask prompts to guide SAM2 in generating distortion-aware masks for subsequent frames. In the Auto-Refine Annotation Phase, missing or incomplete regions are corrected either by applying the SDR again or resolving the discontinuities near the horizontal borders. The Manual Revision Phase finally incorporates LLMs and human annotators to further refine and validate the annotations. Extensive user studies and evaluations demonstrate the effectiveness of our labeling pipeline. Meanwhile, experiments confirm that Leader360V significantly enhances model performance for 360 video segmentation and tracking, paving the way for more scalable 360 scene understanding.
Block-wise Adaptive Caching for Accelerating Diffusion Policy
Jun 16, 2025Diffusion Policy has demonstrated strong visuomotor modeling capabilities, but its high computational cost renders it impractical for real-time robotic control. Despite huge redundancy across repetitive denoising steps, existing diffusion acceleration techniques fail to generalize to Diffusion Policy due to fundamental architectural and data divergences. In this paper, we propose Block-wise Adaptive Caching(BAC), a method to accelerate Diffusion Policy by caching intermediate action features. BAC achieves lossless action generation acceleration by adaptively updating and reusing cached features at the block level, based on a key observation that feature similarities vary non-uniformly across timesteps and locks. To operationalize this insight, we first propose the Adaptive Caching Scheduler, designed to identify optimal update timesteps by maximizing the global feature similarities between cached and skipped features. However, applying this scheduler for each block leads to signiffcant error surges due to the inter-block propagation of caching errors, particularly within Feed-Forward Network (FFN) blocks. To mitigate this issue, we develop the Bubbling Union Algorithm, which truncates these errors by updating the upstream blocks with signiffcant caching errors before downstream FFNs. As a training-free plugin, BAC is readily integrable with existing transformer-based Diffusion Policy and vision-language-action models. Extensive experiments on multiple robotic benchmarks demonstrate that BAC achieves up to 3x inference speedup for free.
Pushing the Limits of Safety: A Technical Report on the ATLAS Challenge 2025
Jun 14, 2025Multimodal Large Language Models (MLLMs) have enabled transformative advancements across diverse applications but remain susceptible to safety threats, especially jailbreak attacks that induce harmful outputs. To systematically evaluate and improve their safety, we organized the Adversarial Testing & Large-model Alignment Safety Grand Challenge (ATLAS) 2025}. This technical report presents findings from the competition, which involved 86 teams testing MLLM vulnerabilities via adversarial image-text attacks in two phases: white-box and black-box evaluations. The competition results highlight ongoing challenges in securing MLLMs and provide valuable guidance for developing stronger defense mechanisms. The challenge establishes new benchmarks for MLLM safety evaluation and lays groundwork for advancing safer multimodal AI systems. The code and data for this challenge are openly available at https://github.com/NY1024/ATLAS_Challenge_2025.