 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Boundaries to Semantics: Prompt-Guided Multi-Task Learning for Petrographic Thin-section Segmentation
Apr 16, 2026Grain-edge segmentation (GES) and lithology semantic segmentation (LSS) are two pivotal tasks for quantifying rock fabric and composition. However, these two tasks are often treated separately, and the segmentation quality is implausible albeit expensive, time-consuming, and expert-annotated datasets have been used. Recently, foundation models, especially the Segment Anything Model (SAM), have demonstrated impressive robustness for boundary alignment. However, directly adapting SAM to joint GES and LSS is nontrivial due to 1) severe domain gap induced by extinction-dependent color variations and ultra-fine grain boundaries, and 2) lacking novel modules for joint learning on multi-angle petrographic image stacks. In this paper, we propose Petro-SAM, a novel two-stage, multi-task framework that can achieve high-quality joint GES and LSS on petrographic images. Specifically, based on SAM, we introduce a Merge Block to integrate seven polarized views, effectively solving the extinction issue. Moreover, we introduce multi-scale feature fusion and color-entropy priors to refine the detection.
Tarot-SAM3: Training-free SAM3 for Any Referring Expression Segmentation
Apr 09, 2026Referring Expression Segmentation (RES) aims to segment image regions described by natural-language expressions, serving as a bridge between vision and language understanding. Existing RES methods, however, rely heavily on large annotated datasets and are limited to either explicit or implicit expressions, hindering their ability to generalize to any referring expression. Recently, the Segment Anything Model 3 (SAM3) has shown impressive robustness in Promptable Concept Segmentation. Nonetheless, applying it to RES remains challenging: (1) SAM3 struggles with longer or implicit expressions; (2) naive coupling of SAM3 with a multimodal large language model (MLLM) makes the final results overly dependent on the MLLM's reasoning capability, without enabling refinement of SAM3's segmentation outputs. To this end, we present Tarot-SAM3, a novel training-free framework that can accurately segment from any referring expression. Specifically, Tarot-SAM3 consists of two key phases. First, the Expression Reasoning Interpreter (ERI) phase introduces reasoning-assisted prompt options to support structured expression parsing and evaluation-aware rephrasing. This transforms arbitrary queries into robust heterogeneous prompts for generating reliable masks with SAM3. Second, the Mask Self-Refining (MSR) phase selects the best mask across prompt types and performs self-refinement by leveraging rich feature relationships from DINOv3 to compare discriminative regions among ERI outputs. It then infers region affiliation to the target, thereby correcting over- and under-segmentation. Extensive experiments demonstrate that Tarot-SAM3 achieves strong performance on both explicit and implicit RES benchmarks, as well as open-world scenarios. Ablation studies further validate the effectiveness of each phase.
PanoSAM2: Lightweight Distortion- and Memory-aware Adaptions of SAM2 for 360 Video Object Segmentation
Apr 09, 2026360 video object segmentation (360VOS) aims to predict temporally-consistent masks in 360 videos, offering full-scene coverage, benefiting applications, such as VR/AR and embodied AI. Learning 360VOS model is nontrivial due to the lack of high-quality labeled dataset. Recently, Segment Anything Models (SAMs), especially SAM2 -- with its design of memory module -- shows strong, promptable VOS capability. However, directly using SAM2 for 360VOS yields implausible results as 360 videos suffer from the projection distortion, semantic inconsistency of left-right sides, and sparse object mask information in SAM2's memory. To this end, we propose PanoSAM2, a novel 360VOS framework based on our lightweight distortion- and memory-aware adaptation strategies of SAM2 to achieve reliable 360VOS while retaining SAM2's user-friendly prompting design. Concretely, to tackle the projection distortion and semantic inconsistency issues, we propose a Pano-Aware Decoder with seam-consistent receptive fields and iterative distortion refinement to maintain continuity across the 0/360 degree boundary. Meanwhile, a Distortion-Guided Mask Loss is introduced to weight pixels by distortion magnitude, stressing stretched regions and boundaries. To address the object sparsity issue, we propose a Long-Short Memory Module to maintain a compact long-term object pointer to re-instantiate and align short-term memories, thereby enhancing temporal coherence. Extensive experiments show that PanoSAM2 yields substantial gains over SAM2: +5.6 on 360VOTS and +6.7 on PanoVOS, showing the effectiveness of our method.
Leader360V: The Large-scale, Real-world 360 Video Dataset for Multi-task Learning in Diverse Environment
Jun 17, 2025360 video captures the complete surrounding scenes with the ultra-large field of view of 360X180. This makes 360 scene understanding tasks, eg, segmentation and tracking, crucial for appications, such as autonomous driving, robotics. With the recent emergence of foundation models, the community is, however, impeded by the lack of large-scale, labelled real-world datasets. This is caused by the inherent spherical properties, eg, severe distortion in polar regions, and content discontinuities, rendering the annotation costly yet complex. This paper introduces Leader360V, the first large-scale, labeled real-world 360 video datasets for instance segmentation and tracking. Our datasets enjoy high scene diversity, ranging from indoor and urban settings to natural and dynamic outdoor scenes. To automate annotation, we design an automatic labeling pipeline, which subtly coordinates pre-trained 2D segmentors and large language models to facilitate the labeling. The pipeline operates in three novel stages. Specifically, in the Initial Annotation Phase, we introduce a Semantic- and Distortion-aware Refinement module, which combines object mask proposals from multiple 2D segmentors with LLM-verified semantic labels. These are then converted into mask prompts to guide SAM2 in generating distortion-aware masks for subsequent frames. In the Auto-Refine Annotation Phase, missing or incomplete regions are corrected either by applying the SDR again or resolving the discontinuities near the horizontal borders. The Manual Revision Phase finally incorporates LLMs and human annotators to further refine and validate the annotations. Extensive user studies and evaluations demonstrate the effectiveness of our labeling pipeline. Meanwhile, experiments confirm that Leader360V significantly enhances model performance for 360 video segmentation and tracking, paving the way for more scalable 360 scene understanding.
E-SAM: Training-Free Segment Every Entity Model
Mar 15, 2025



Entity Segmentation (ES) aims at identifying and segmenting distinct entities within an image without the need for predefined class labels. This characteristic makes ES well-suited to open-world applications with adaptation to diverse and dynamically changing environments, where new and previously unseen entities may appear frequently. Existing ES methods either require large annotated datasets or high training costs, limiting their scalability and adaptability. Recently, the Segment Anything Model (SAM), especially in its Automatic Mask Generation (AMG) mode, has shown potential for holistic image segmentation. However, it struggles with over-segmentation and under-segmentation, making it less effective for ES. In this paper, we introduce E-SAM, a novel training-free framework that exhibits exceptional ES capability. Specifically, we first propose Multi-level Mask Generation (MMG) that hierarchically processes SAM's AMG outputs to generate reliable object-level masks while preserving fine details at other levels. Entity-level Mask Refinement (EMR) then refines these object-level masks into accurate entity-level masks. That is, it separates overlapping masks to address the redundancy issues inherent in SAM's outputs and merges similar masks by evaluating entity-level consistency. Lastly, Under-Segmentation Refinement (USR) addresses under-segmentation by generating additional high-confidence masks fused with EMR outputs to produce the final ES map. These three modules are seamlessly optimized to achieve the best ES without additional training overhead. Extensive experiments demonstrate that E-SAM achieves state-of-the-art performance compared to prior ES methods, demonstrating a significant improvement by +30.1 on benchmark metrics.
Look Closer to Your Enemy: Learning to Attack via Teacher-student Mimicking
Jul 28, 2022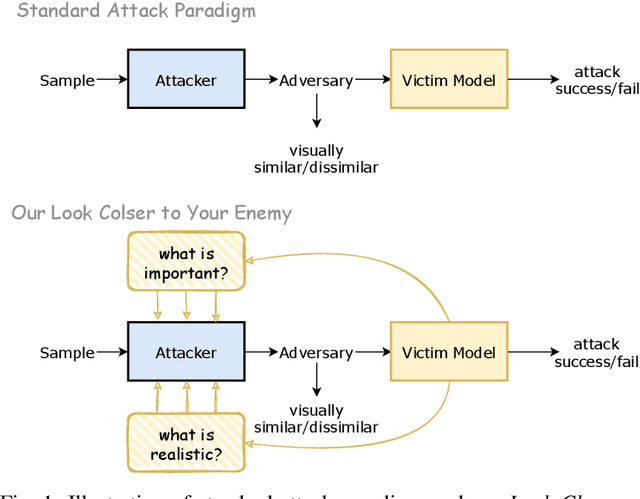
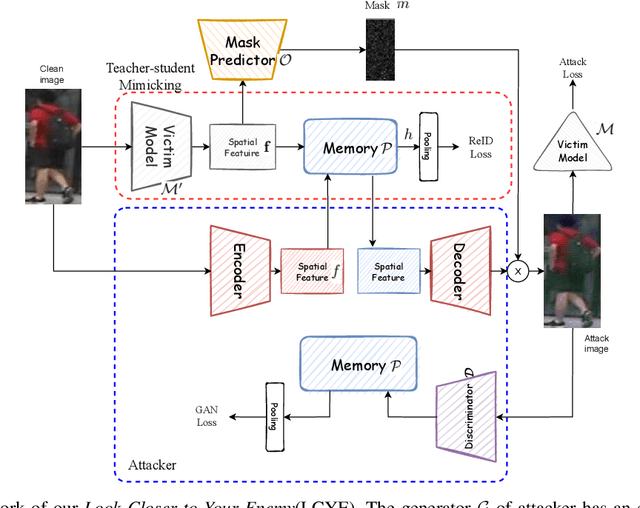
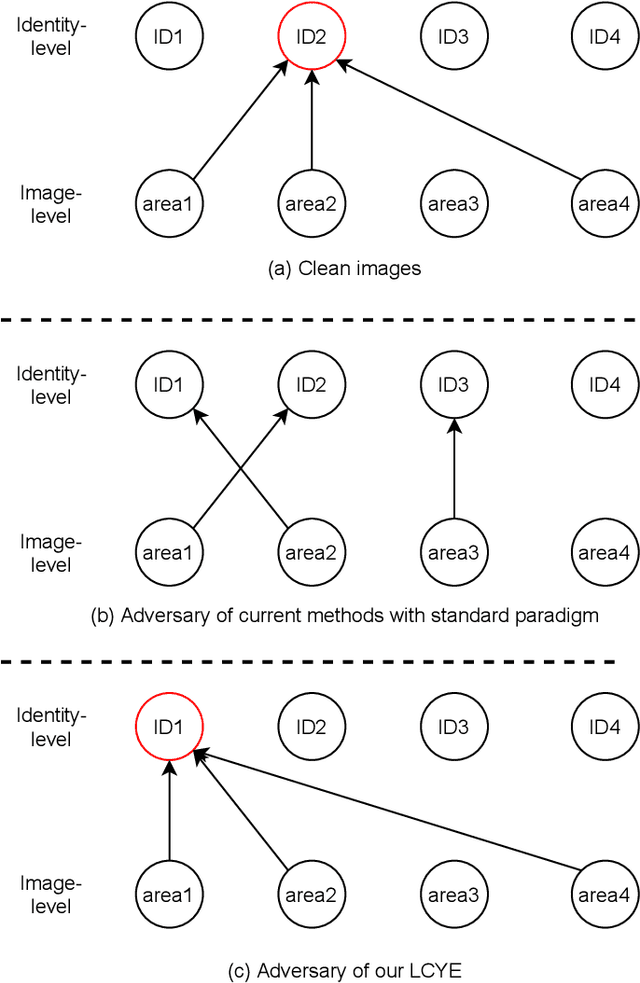
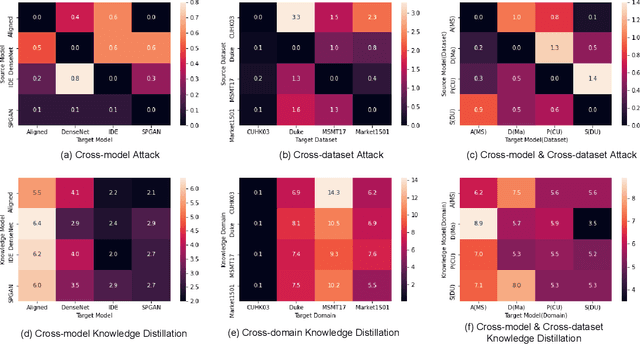
This paper aims to generate realistic attack samples of person re-identification, ReID, by reading the enemy's mind (VM). In this paper, we propose a novel inconspicuous and controllable ReID attack baseline, LCYE, to generate adversarial query images. Concretely, LCYE first distills VM's knowledge via teacher-student memory mimicking in the proxy task. Then this knowledge prior acts as an explicit cipher conveying what is essential and realistic, believed by VM, for accurate adversarial misleading. Besides, benefiting from the multiple opposing task framework of LCYE, we further investigate the interpretability and generalization of ReID models from the view of the adversarial attack, including cross-domain adaption, cross-model consensus, and online learning process. Extensive experiments on four ReID benchmarks show that our method outperforms other state-of-the-art attackers with a large margin in white-box, black-box, and target attacks. Our code is now available at https://gitfront.io/r/user-3704489/mKXusqDT4ffr/LCYE/.