 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Implicit Feedback from Deployment Data in Dialogue
Jul 26, 2023



We study improving social conversational agents by learning from natural dialogue between users and a deployed model, without extra annotations. To implicitly measure the quality of a machine-generated utterance, we leverage signals like user response length, sentiment and reaction of the future human utterances in the collected dialogue episodes. Our experiments use the publicly released deployment data from BlenderBot (Xu et al., 2023). Human evaluation indicates improvements in our new models over baseline responses; however, we find that some proxy signals can lead to more generations with undesirable properties as well. For example, optimizing for conversation length can lead to more controversial or unfriendly generations compared to the baseline, whereas optimizing for positive sentiment or reaction can decrease these behaviors.
Making the Most Out of the Limited Context Length: Predictive Power Varies with Clinical Note Type and Note Section
Jul 13, 2023


Recent advances in large language models have led to renewed interest in natural language processing in healthcare using the free text of clinical notes. One distinguishing characteristic of clinical notes is their long time span over multiple long documents. The unique structure of clinical notes creates a new design choice: when the context length for a language model predictor is limited, which part of clinical notes should we choose as the input? Existing studies either choose the inputs with domain knowledge or simply truncate them. We propose a framework to analyze the sections with high predictive power. Using MIMIC-III, we show that: 1) predictive power distribution is different between nursing notes and discharge notes and 2) combining different types of notes could improve performance when the context length is large. Our findings suggest that a carefully selected sampling function could enable more efficient information extraction from clinical notes.
* Our code is publicly available on GitHub (https://github.com/nyuolab/EfficientTransformer)
System-Level Natural Language Feedback
Jun 23, 2023Natural language (NL) feedback contains rich information about the user experience. Existing studies focus on an instance-level approach, where feedback is used to refine specific examples, disregarding its system-wide application. This paper proposes a general framework for unlocking the system-level use of NL feedback. We show how to use feedback to formalize system-level design decisions in a human-in-the-loop-process -- in order to produce better models. In particular this is done through: (i) metric design for tasks; and (ii) language model prompt design for refining model responses. We conduct two case studies of this approach for improving search query generation and dialog response generation, demonstrating the effectiveness of the use of system-level feedback. We show the combination of system-level feedback and instance-level feedback brings further gains, and that human written instance-level feedback results in more grounded refinements than GPT-3.5 written ones, underlying the importance of human feedback for building systems.
On Sensitivity and Robustness of Normalization Schemes to Input Distribution Shifts in Automatic MR Image Diagnosis
Jun 23, 2023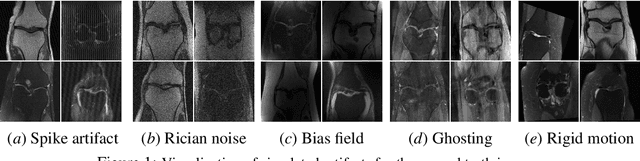
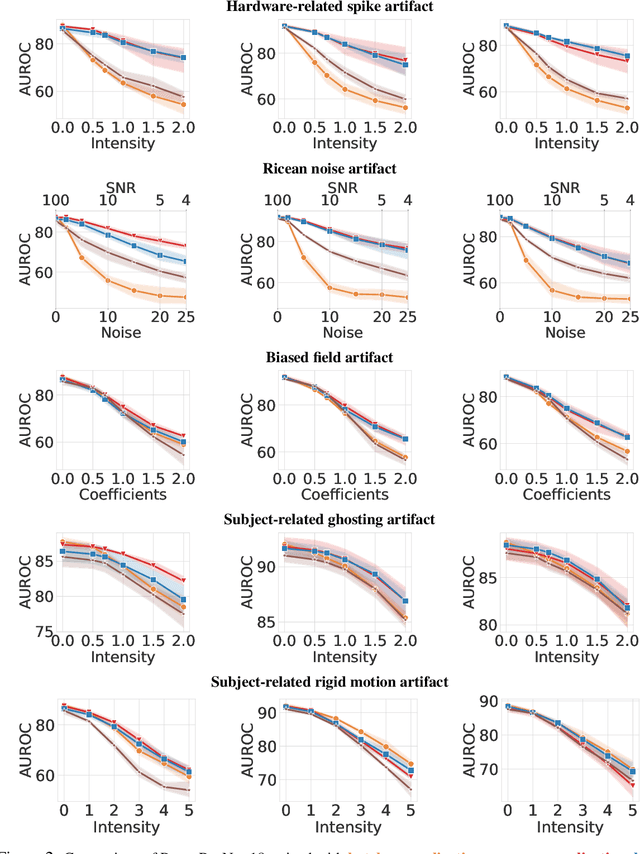
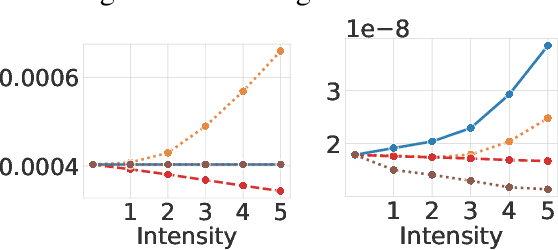
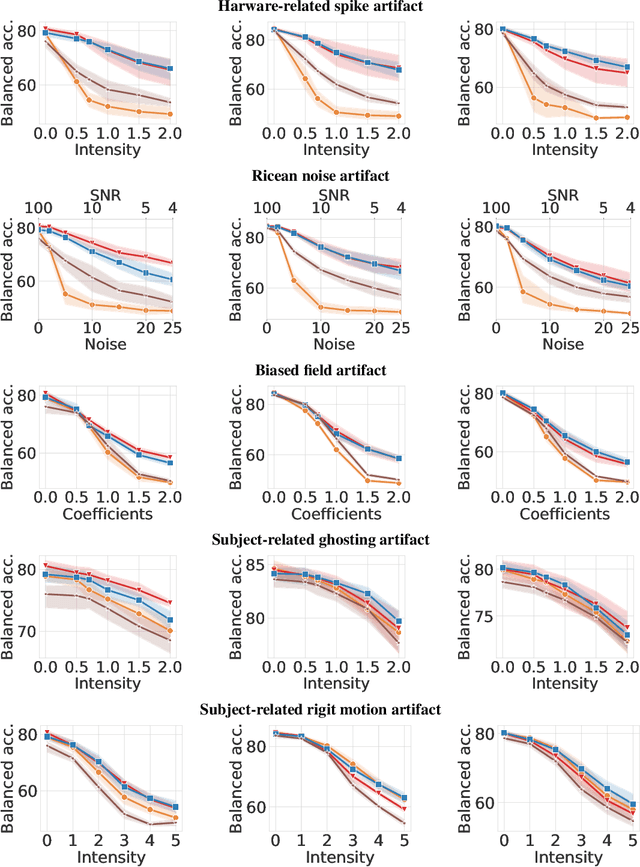
Magnetic Resonance Imaging (MRI) is considered the gold standard of medical imaging because of the excellent soft-tissue contrast exhibited in the images reconstructed by the MRI pipeline, which in-turn enables the human radiologist to discern many pathologies easily. More recently, Deep Learning (DL) models have also achieved state-of-the-art performance in diagnosing multiple diseases using these reconstructed images as input. However, the image reconstruction process within the MRI pipeline, which requires the use of complex hardware and adjustment of a large number of scanner parameters, is highly susceptible to noise of various forms, resulting in arbitrary artifacts within the images. Furthermore, the noise distribution is not stationary and varies within a machine, across machines, and patients, leading to varying artifacts within the images. Unfortunately, DL models are quite sensitive to these varying artifacts as it leads to changes in the input data distribution between the training and testing phases. The lack of robustness of these models against varying artifacts impedes their use in medical applications where safety is critical. In this work, we focus on improving the generalization performance of these models in the presence of multiple varying artifacts that manifest due to the complexity of the MR data acquisition. In our experiments, we observe that Batch Normalization, a widely used technique during the training of DL models for medical image analysis, is a significant cause of performance degradation in these changing environments. As a solution, we propose to use other normalization techniques, such as Group Normalization and Layer Normalization (LN), to inject robustness into model performance against varying image artifacts. Through a systematic set of experiments, we show that GN and LN provide better accuracy for various MR artifacts and distribution shifts.
Protein Discovery with Discrete Walk-Jump Sampling
Jun 08, 2023



We resolve difficulties in training and sampling from a discrete generative model by learning a smoothed energy function, sampling from the smoothed data manifold with Langevin Markov chain Monte Carlo (MCMC), and projecting back to the true data manifold with one-step denoising. Our Discrete Walk-Jump Sampling formalism combines the maximum likelihood training of an energy-based model and improved sample quality of a score-based model, while simplifying training and sampling by requiring only a single noise level. We evaluate the robustness of our approach on generative modeling of antibody proteins and introduce the distributional conformity score to benchmark protein generative models. By optimizing and sampling from our models for the proposed distributional conformity score, 97-100% of generated samples are successfully expressed and purified and 35% of functional designs show equal or improved binding affinity compared to known functional antibodies on the first attempt in a single round of laboratory experiments. We also report the first demonstration of long-run fast-mixing MCMC chains where diverse antibody protein classes are visited in a single MCMC chain.
BOtied: Multi-objective Bayesian optimization with tied multivariate ranks
Jun 01, 2023



Many scientific and industrial applications require joint optimization of multiple, potentially competing objectives. Multi-objective Bayesian optimization (MOBO) is a sample-efficient framework for identifying Pareto-optimal solutions. We show a natural connection between non-dominated solutions and the highest multivariate rank, which coincides with the outermost level line of the joint cumulative distribution function (CDF). We propose the CDF indicator, a Pareto-compliant metric for evaluating the quality of approximate Pareto sets that complements the popular hypervolume indicator. At the heart of MOBO is the acquisition function, which determines the next candidate to evaluate by navigating the best compromises among the objectives. Multi-objective acquisition functions that rely on box decomposition of the objective space, such as the expected hypervolume improvement (EHVI) and entropy search, scale poorly to a large number of objectives. We propose an acquisition function, called BOtied, based on the CDF indicator. BOtied can be implemented efficiently with copulas, a statistical tool for modeling complex, high-dimensional distributions. We benchmark BOtied against common acquisition functions, including EHVI and random scalarization (ParEGO), in a series of synthetic and real-data experiments. BOtied performs on par with the baselines across datasets and metrics while being computationally efficient.
Protein Design with Guided Discrete Diffusion
May 31, 2023A popular approach to protein design is to combine a generative model with a discriminative model for conditional sampling. The generative model samples plausible sequences while the discriminative model guides a search for sequences with high fitness. Given its broad success in conditional sampling, classifier-guided diffusion modeling is a promising foundation for protein design, leading many to develop guided diffusion models for structure with inverse folding to recover sequences. In this work, we propose diffusioN Optimized Sampling (NOS), a guidance method for discrete diffusion models that follows gradients in the hidden states of the denoising network. NOS makes it possible to perform design directly in sequence space, circumventing significant limitations of structure-based methods, including scarce data and challenging inverse design. Moreover, we use NOS to generalize LaMBO, a Bayesian optimization procedure for sequence design that facilitates multiple objectives and edit-based constraints. The resulting method, LaMBO-2, enables discrete diffusions and stronger performance with limited edits through a novel application of saliency maps. We apply LaMBO-2 to a real-world protein design task, optimizing antibodies for higher expression yield and binding affinity to a therapeutic target under locality and liability constraints, with 97% expression rate and 25% binding rate in exploratory in vitro experiments.
Two Failures of Self-Consistency in the Multi-Step Reasoning of LLMs
May 23, 2023



Large language models (LLMs) have achieved widespread success on a variety of in-context few-shot tasks, but this success is typically evaluated via correctness rather than consistency. We argue that self-consistency is an important criteria for valid multi-step reasoning and propose two types of self-consistency that are particularly important for multi-step logic -- hypothetical consistency (the ability for a model to predict what its output would be in a hypothetical other context) and compositional consistency (consistency of a model's outputs for a compositional task even when an intermediate step is replaced with the model's output for that step). We demonstrate that four sizes of the GPT-3 model exhibit poor consistency rates across both types of consistency on four different tasks (Wikipedia, DailyDialog, arithmetic, and GeoQuery).
Towards Understanding and Improving GFlowNet Training
May 11, 2023



Generative flow networks (GFlowNets) are a family of algorithms that learn a generative policy to sample discrete objects $x$ with non-negative reward $R(x)$. Learning objectives guarantee the GFlowNet samples $x$ from the target distribution $p^*(x) \propto R(x)$ when loss is globally minimized over all states or trajectories, but it is unclear how well they perform with practical limits on training resources. We introduce an efficient evaluation strategy to compare the learned sampling distribution to the target reward distribution. As flows can be underdetermined given training data, we clarify the importance of learned flows to generalization and matching $p^*(x)$ in practice. We investigate how to learn better flows, and propose (i) prioritized replay training of high-reward $x$, (ii) relative edge flow policy parametrization, and (iii) a novel guided trajectory balance objective, and show how it can solve a substructure credit assignment problem. We substantially improve sample efficiency on biochemical design tasks.
A Comparison of Semi-Supervised Learning Techniques for Streaming ASR at Scale
Apr 19, 2023



Unpaired text and audio injection have emerged as dominant methods for improving ASR performance in the absence of a large labeled corpus. However, little guidance exists on deploying these methods to improve production ASR systems that are trained on very large supervised corpora and with realistic requirements like a constrained model size and CPU budget, streaming capability, and a rich lattice for rescoring and for downstream NLU tasks. In this work, we compare three state-of-the-art semi-supervised methods encompassing both unpaired text and audio as well as several of their combinations in a controlled setting using joint training. We find that in our setting these methods offer many improvements beyond raw WER, including substantial gains in tail-word WER, decoder computation during inference, and lattice density.