 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMATHENA: Mamba-based Architectural Tooth Hierarchical Estimator and Holistic Evaluation Network for Anatomy
Apr 01, 2026Dental diagnosis from Orthopantomograms (OPGs) requires coordination of tooth detection, caries segmentation (CarSeg), anomaly detection (AD), and dental developmental staging (DDS). We propose Mamba-based Architectural Tooth Hierarchical Estimator and Holistic Evaluation Network for Anatomy (MATHENA), a unified framework leveraging Mamba's linear-complexity State Space Models (SSM) to address all four tasks. MATHENA integrates MATHE, a multi-resolution SSM-driven detector with four-directional Vision State Space (VSS) blocks for O(N) global context modeling, generating per-tooth crops. These crops are processed by HENA, a lightweight Mamba-UNet with a triple-head architecture and Global Context State Token (GCST). In the triple-head architecture, CarSeg is first trained as an upstream task to establish shared representations, which are then frozen and reused for downstream AD fine-tuning and DDS classification via linear probing, enabling stable, efficient learning. We also curate PARTHENON, a benchmark comprising 15,062 annotated instances from ten datasets. MATHENA achieves 93.78% mAP@50 in tooth detection, 90.11% Dice for CarSeg, 88.35% for AD, and 72.40% ACC for DDS.
From National Curricula to Cultural Awareness: Constructing Open-Ended Culture-Specific Question Answering Dataset
Jan 08, 2026Large language models (LLMs) achieve strong performance on many tasks, but their progress remains uneven across languages and cultures, often reflecting values latent in English-centric training data. To enable practical cultural alignment, we propose a scalable approach that leverages national social studies curricula as a foundation for culture-aware supervision. We introduce CuCu, an automated multi-agent LLM framework that transforms national textbook curricula into open-ended, culture-specific question-answer pairs. Applying CuCu to the Korean national social studies curriculum, we construct KCaQA, comprising 34.1k open-ended QA pairs. Our quantitative and qualitative analyses suggest that KCaQA covers culture-specific topics and produces responses grounded in local sociocultural contexts.
KLUE: Korean Language Understanding Evaluation
Jun 11, 2021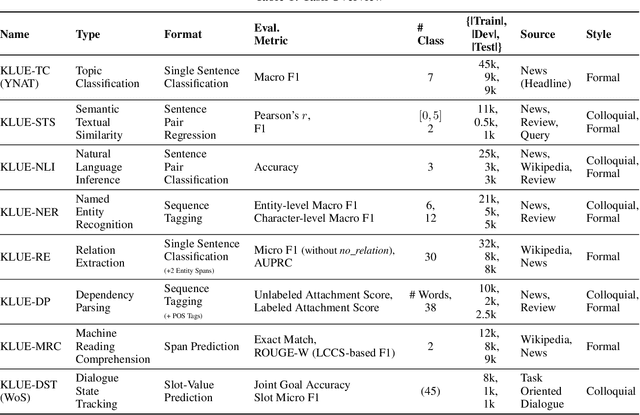
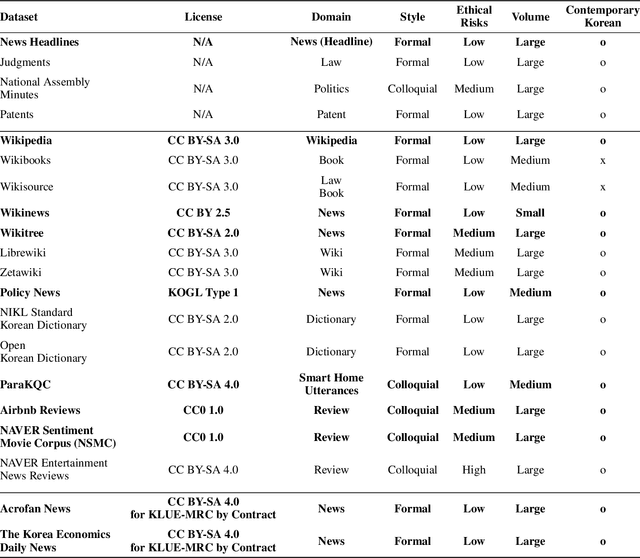
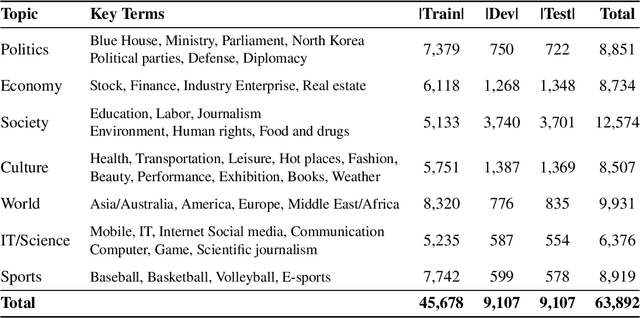
We introduce Korean Language Understanding Evaluation (KLUE) benchmark. KLUE is a collection of 8 Korean natural language understanding (NLU) tasks, including Topic Classification, SemanticTextual Similarity, Natural Language Inference, Named Entity Recognition, Relation Extraction, Dependency Parsing, Machine Reading Comprehension, and Dialogue State Tracking. We build all of the tasks from scratch from diverse source corpora while respecting copyrights, to ensure accessibility for anyone without any restrictions. With ethical considerations in mind, we carefully design annotation protocols. Along with the benchmark tasks and data, we provide suitable evaluation metrics and fine-tuning recipes for pretrained language models for each task. We furthermore release the pretrained language models (PLM), KLUE-BERT and KLUE-RoBERTa, to help reproducing baseline models on KLUE and thereby facilitate future research. We make a few interesting observations from the preliminary experiments using the proposed KLUE benchmark suite, already demonstrating the usefulness of this new benchmark suite. First, we find KLUE-RoBERTa-large outperforms other baselines, including multilingual PLMs and existing open-source Korean PLMs. Second, we see minimal degradation in performance even when we replace personally identifiable information from the pretraining corpus, suggesting that privacy and NLU capability are not at odds with each other. Lastly, we find that using BPE tokenization in combination with morpheme-level pre-tokenization is effective in tasks involving morpheme-level tagging, detection and generation. In addition to accelerating Korean NLP research, our comprehensive documentation on creating KLUE will facilitate creating similar resources for other languages in the future. KLUE is available at https://klue-benchmark.com.