 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniform-in-Time Weak Propagation-of-Chaos in Shallow Neural Networks
May 21, 2026We consider one-hidden layer neural networks trained in the feature-learning regime using gradient descent, and relate the output of the finite-width network $f_{\hatρ_t^m}$ to its infinite-width counterpart $f_{ρ_t^{MF}}$, which evolves in the mean-field dynamics. While constant-time horizon bounds for $\|f_{ρ_t^{MF}} - f_{\hatρ_t^m}\|$ may be obtained via standard Grönwall estimates, the long-time behavior of the fluctuation is a more delicate matter. Uniform-in-time bounds often rely on (local) strong convexity in the landscape or Logarithmic Sobolev inequalities present in noisy gradient dynamics. In this work, we establish non-asymptotic weak propagation-of-chaos that holds uniformly in time, obtained by exploiting instead the convergence rate of the mean-field deterministic Wasserstein-gradient-flow dynamics. Specifically, denoting by $L_t$ the mean-field excess MSE loss at time $t$ and $m$ the number of neurons, under standard regularity assumptions and the condition $\int_0^\infty L_t^{1/2} dt =O(\log d)$, we obtain the uniform in time bound $\|f_{ρ_t^{MF}}- f_{\hatρ_t^m}\|^2 \lesssim \text{poly}(d) m^{-\min(1,c/6)}$ whenever $L_t \lesssim t^{-c}$. Our result holds in a noiseless setting and does not make any assumptions on the geometry of the landscape near the optimum, and extends seamlessly to other forms of discretization, including finite number of samples and time discretization. A key takeaway of our result is that whenever the convergence rate of the mean-field, population-loss dynamics is faster than $t^{-2}$, we can attain a loss of $ε$ with only $\text{poly}(d/ε)$ neurons, training samples, and GD steps.
Lost in Tokenization: Fundamental Trade-offs in Graph Tokenization for Transformers
May 21, 2026Transformers have become a central architecture for graph learning, but their application to graphs requires first choosing a tokenization: a graph-to-token map that determines which structural information is exposed at the input. In this work, we show that this choice is a fundamental component of transformer expressivity. We examine three tokenizations that serve as building blocks for many existing graph tokenizations: spectral, random-walk, and adjacency tokenizations. We prove that different tokenizations induce distinct depth regimes: the same graph computation may be realizable by a shallow transformer under one tokenization, while requiring substantially larger depth under another. For example, we prove that random-walk tokenization is lossy for any walk length, making it impossible in general to recover the graph from it, and that while spectral tokenization is lossless, it is ill-conditioned for local tasks. We further show that although both random-walk and spectral tokenizations are derived from adjacency information, it is impossible for a limited-depth transformer to convert between tokenization families in general. In particular, we establish lower bounds and impossibility results showing that unfavorable tokenizations may preclude the efficient recovery of more suitable structural representations. Finally, we complement our theory with controlled experiments on synthetic and real-world tasks, validating the predicted separations and showing that different tasks favor different structural views, and combining complementary tokenizations allows the transformer to leverage distinct signals from each representation.
Geometric Factual Recall in Transformers
May 12, 2026How do transformer language models memorize factual associations? A common view casts internal weight matrices as associative memories over pairs of embeddings, requiring parameter counts that scale linearly with the number of facts. We develop a theoretical and empirical account of an alternative, \emph{geometric} form of memorization in which learned embeddings encode relational structure directly, and the MLP plays a qualitatively different role. In a controlled setting where a single-layer transformer must memorize random bijections from subjects to a shared attribute set, we prove that a logarithmic embedding dimension suffices: subject embeddings encode \emph{linear superpositions} of their associated attribute vectors, and a small MLP acts as a relation-conditioned selector that extracts the relevant attribute via ReLU gating, and not as an associative key-value mapping. We extend these results to the multi-hop setting -- chains of relational queries such as ``Who is the mother of the wife of $x$?'' -- providing constructions with and without chain-of-thought that exhibit a provable capacity-depth tradeoff, complemented by a matching information-theoretic lower bound. Empirically, gradient descent discovers solutions with precisely the predicted structure. Once trained, the MLP transfers zero-shot to entirely new bijections when subject embeddings are appropriately re-initialized, revealing that it has learned a generic selection mechanism rather than memorized any particular set of facts.
Towards Infinitely Long Neural Simulations: Self-Refining Neural Surrogate Models for Dynamical Systems
Mar 18, 2026Recent advances in autoregressive neural surrogate models have enabled orders-of-magnitude speedups in simulating dynamical systems. However, autoregressive models are generally prone to distribution drift: compounding errors in autoregressive rollouts that severely degrade generation quality over long time horizons. Existing work attempts to address this issue by implicitly leveraging the inherent trade-off between short-time accuracy and long-time consistency through hyperparameter tuning. In this work, we introduce a unifying mathematical framework that makes this tradeoff explicit, formalizing and generalizing hyperparameter-based strategies in existing approaches. Within this framework, we propose a robust, hyperparameter-free model implemented as a conditional diffusion model that balances short-time fidelity with long-time consistency by construction. Our model, Self-refining Neural Surrogate model (SNS), can be implemented as a standalone model that refines its own autoregressive outputs or as a complementary model to existing neural surrogates to ensure long-time consistency. We also demonstrate the numerical feasibility of SNS through high-fidelity simulations of complex dynamical systems over arbitrarily long time horizons.
Generative Modeling from Black-box Corruptions via Self-Consistent Stochastic Interpolants
Dec 11, 2025Transport-based methods have emerged as a leading paradigm for building generative models from large, clean datasets. However, in many scientific and engineering domains, clean data are often unavailable: instead, we only observe measurements corrupted through a noisy, ill-conditioned channel. A generative model for the original data thus requires solving an inverse problem at the level of distributions. In this work, we introduce a novel approach to this task based on Stochastic Interpolants: we iteratively update a transport map between corrupted and clean data samples using only access to the corrupted dataset as well as black box access to the corruption channel. Under appropriate conditions, this iterative procedure converges towards a self-consistent transport map that effectively inverts the corruption channel, thus enabling a generative model for the clean data. We refer to the resulting method as the self-consistent stochastic interpolant (SCSI). It (i) is computationally efficient compared to variational alternatives, (ii) highly flexible, handling arbitrary nonlinear forward models with only black-box access, and (iii) enjoys theoretical guarantees. We demonstrate superior performance on inverse problems in natural image processing and scientific reconstruction, and establish convergence guarantees of the scheme under appropriate assumptions.
The Generative Leap: Sharp Sample Complexity for Efficiently Learning Gaussian Multi-Index Models
Jun 05, 2025In this work we consider generic Gaussian Multi-index models, in which the labels only depend on the (Gaussian) $d$-dimensional inputs through their projection onto a low-dimensional $r = O_d(1)$ subspace, and we study efficient agnostic estimation procedures for this hidden subspace. We introduce the \emph{generative leap} exponent $k^\star$, a natural extension of the generative exponent from [Damian et al.'24] to the multi-index setting. We first show that a sample complexity of $n=\Theta(d^{1 \vee \k/2})$ is necessary in the class of algorithms captured by the Low-Degree-Polynomial framework. We then establish that this sample complexity is also sufficient, by giving an agnostic sequential estimation procedure (that is, requiring no prior knowledge of the multi-index model) based on a spectral U-statistic over appropriate Hermite tensors. We further compute the generative leap exponent for several examples including piecewise linear functions (deep ReLU networks with bias), and general deep neural networks (with $r$-dimensional first hidden layer).
Propagation of Chaos in One-hidden-layer Neural Networks beyond Logarithmic Time
Apr 17, 2025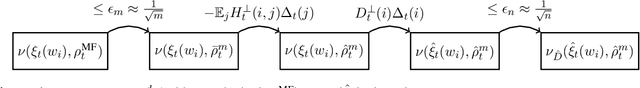

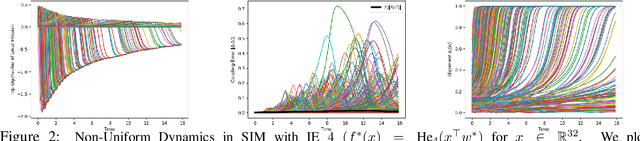
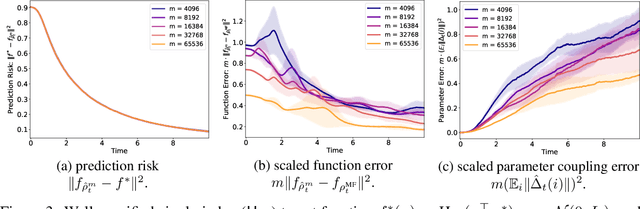
We study the approximation gap between the dynamics of a polynomial-width neural network and its infinite-width counterpart, both trained using projected gradient descent in the mean-field scaling regime. We demonstrate how to tightly bound this approximation gap through a differential equation governed by the mean-field dynamics. A key factor influencing the growth of this ODE is the local Hessian of each particle, defined as the derivative of the particle's velocity in the mean-field dynamics with respect to its position. We apply our results to the canonical feature learning problem of estimating a well-specified single-index model; we permit the information exponent to be arbitrarily large, leading to convergence times that grow polynomially in the ambient dimension $d$. We show that, due to a certain ``self-concordance'' property in these problems -- where the local Hessian of a particle is bounded by a constant times the particle's velocity -- polynomially many neurons are sufficient to closely approximate the mean-field dynamics throughout training.
Survey on Algorithms for multi-index models
Apr 07, 2025We review the literature on algorithms for estimating the index space in a multi-index model. The primary focus is on computationally efficient (polynomial-time) algorithms in Gaussian space, the assumptions under which consistency is guaranteed by these methods, and their sample complexity. In many cases, a gap is observed between the sample complexity of the best known computationally efficient methods and the information-theoretical minimum. We also review algorithms based on estimating the span of gradients using nonparametric methods, and algorithms based on fitting neural networks using gradient descent
Thermalizer: Stable autoregressive neural emulation of spatiotemporal chaos
Mar 24, 2025



Autoregressive surrogate models (or \textit{emulators}) of spatiotemporal systems provide an avenue for fast, approximate predictions, with broad applications across science and engineering. At inference time, however, these models are generally unable to provide predictions over long time rollouts due to accumulation of errors leading to diverging trajectories. In essence, emulators operate out of distribution, and controlling the online distribution quickly becomes intractable in large-scale settings. To address this fundamental issue, and focusing on time-stationary systems admitting an invariant measure, we leverage diffusion models to obtain an implicit estimator of the score of this invariant measure. We show that this model of the score function can be used to stabilize autoregressive emulator rollouts by applying on-the-fly denoising during inference, a process we call \textit{thermalization}. Thermalizing an emulator rollout is shown to extend the time horizon of stable predictions by an order of magnitude in complex systems exhibiting turbulent and chaotic behavior, opening up a novel application of diffusion models in the context of neural emulation.
Compositional Reasoning with Transformers, RNNs, and Chain of Thought
Mar 03, 2025



We study and compare the expressive power of transformers, RNNs, and transformers with chain of thought tokens on a simple and natural class of problems we term Compositional Reasoning Questions (CRQ). This family captures problems like evaluating Boolean formulas and multi-step word problems. Assuming standard hardness assumptions from circuit complexity and communication complexity, we prove that none of these three architectures is capable of solving CRQs unless some hyperparameter (depth, embedding dimension, and number of chain of thought tokens, respectively) grows with the size of the input. We also provide a construction for each architecture that solves CRQs. For transformers, our construction uses depth that is logarithmic in the problem size. For RNNs, logarithmic embedding dimension is necessary and sufficient, so long as the inputs are provided in a certain order. (Otherwise, a linear dimension is necessary). For transformers with chain of thought, our construction uses $n$ CoT tokens. These results show that, while CRQs are inherently hard, there are several different ways for language models to overcome this hardness. Even for a single class of problems, each architecture has strengths and weaknesses, and none is strictly better than the others.