 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline hyperparameter optimization by real-time recurrent learning
Paper and Code
Feb 15, 2021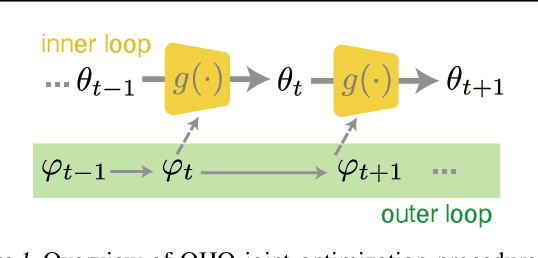
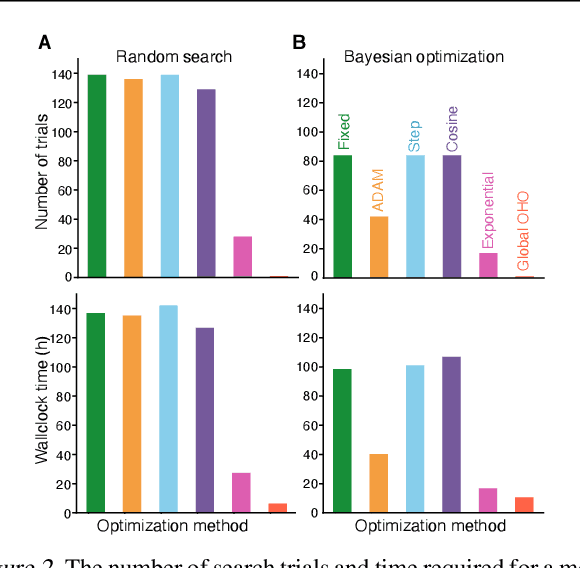
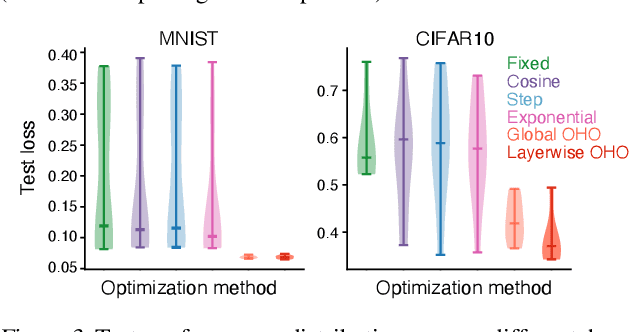
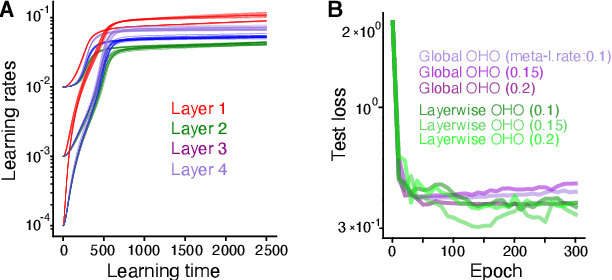
Conventional hyperparameter optimization methods are computationally intensive and hard to generalize to scenarios that require dynamically adapting hyperparameters, such as life-long learning. Here, we propose an online hyperparameter optimization algorithm that is asymptotically exact and computationally tractable, both theoretically and practically. Our framework takes advantage of the analogy between hyperparameter optimization and parameter learning in recurrent neural networks (RNNs). It adapts a well-studied family of online learning algorithms for RNNs to tune hyperparameters and network parameters simultaneously, without repeatedly rolling out iterative optimization. This procedure yields systematically better generalization performance compared to standard methods, at a fraction of wallclock time.