 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNaturalProofs: Mathematical Theorem Proving in Natural Language
Paper and Code

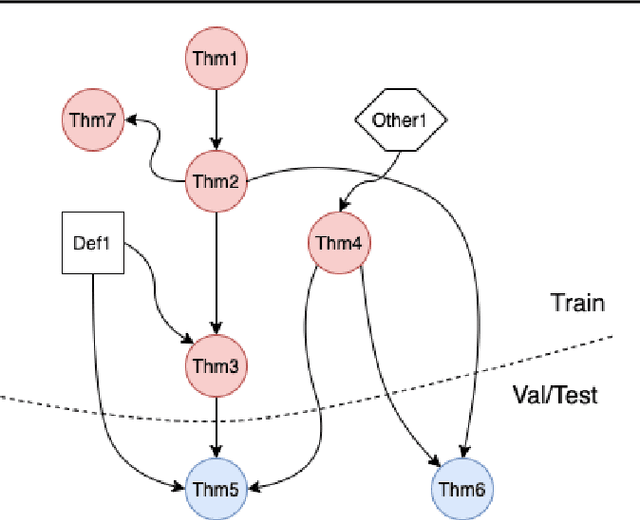
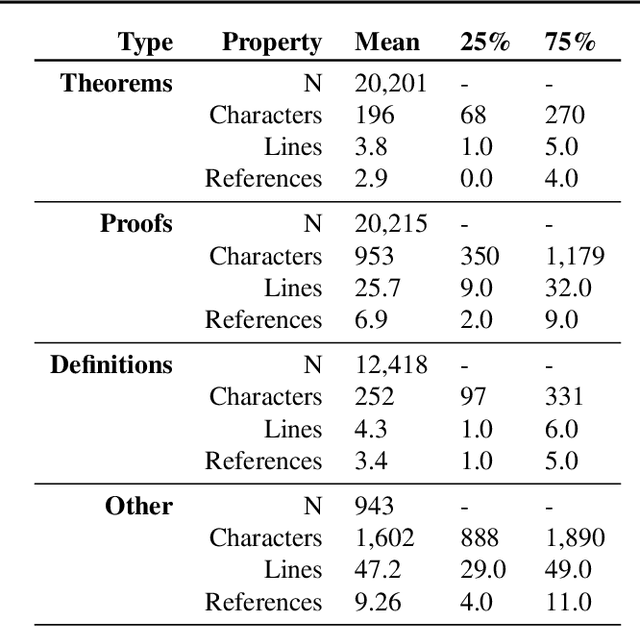
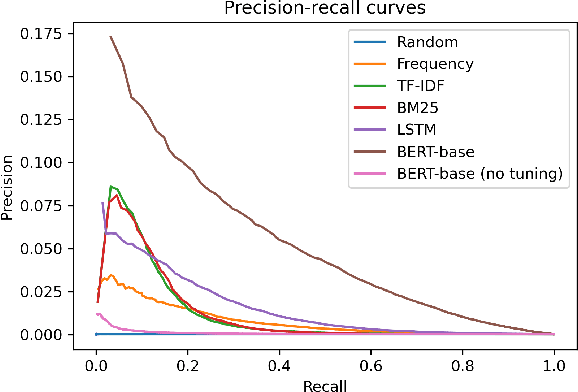
Understanding and creating mathematics using natural mathematical language - the mixture of symbolic and natural language used by humans - is a challenging and important problem for driving progress in machine learning. As a step in this direction, we develop NaturalProofs, a large-scale dataset of mathematical statements and their proofs, written in natural mathematical language. Using NaturalProofs, we propose a mathematical reference retrieval task that tests a system's ability to determine the key results that appear in a proof. Large-scale sequence models excel at this task compared to classical information retrieval techniques, and benefit from language pretraining, yet their performance leaves substantial room for improvement. NaturalProofs opens many possibilities for future research on challenging mathematical tasks.