 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Deep Autoregressive Models as Causal Inference Engines
Sep 27, 2024



Existing causal inference (CI) models are limited to primarily handling low-dimensional confounders and singleton actions. We propose an autoregressive (AR) CI framework capable of handling complex confounders and sequential actions common in modern applications. We accomplish this by {\em sequencification}, transforming data from an underlying causal diagram into a sequence of tokens. This approach not only enables training with data generated from any DAG but also extends existing CI capabilities to accommodate estimating several statistical quantities using a {\em single} model. We can directly predict interventional probabilities, simplifying inference and enhancing outcome prediction accuracy. We demonstrate that an AR model adapted for CI is efficient and effective in various complex applications such as navigating mazes, playing chess endgames, and evaluating the impact of certain keywords on paper acceptance rates.
Active and Passive Causal Inference Learning
Aug 18, 2023



This paper serves as a starting point for machine learning researchers, engineers and students who are interested in but not yet familiar with causal inference. We start by laying out an important set of assumptions that are collectively needed for causal identification, such as exchangeability, positivity, consistency and the absence of interference. From these assumptions, we build out a set of important causal inference techniques, which we do so by categorizing them into two buckets; active and passive approaches. We describe and discuss randomized controlled trials and bandit-based approaches from the active category. We then describe classical approaches, such as matching and inverse probability weighting, in the passive category, followed by more recent deep learning based algorithms. By finishing the paper with some of the missing aspects of causal inference from this paper, such as collider biases, we expect this paper to provide readers with a diverse set of starting points for further reading and research in causal inference and discovery.
UAMM: UBET Automated Market Maker
Aug 11, 2023Automated market makers (AMMs) are pricing mechanisms utilized by decentralized exchanges (DEX). Traditional AMM approaches are constrained by pricing solely based on their own liquidity pool, without consideration of external markets or risk management for liquidity providers. In this paper, we propose a new approach known as UBET AMM (UAMM), which calculates prices by considering external market prices and the impermanent loss of the liquidity pool. Despite relying on external market prices, our method maintains the desired properties of a constant product curve when computing slippages. The key element of UAMM is determining the appropriate slippage amount based on the desired target balance, which encourages the liquidity pool to minimize impermanent loss. We demonstrate that our approach eliminates arbitrage opportunities when external market prices are efficient.
Causal Effect Variational Autoencoder with Uniform Treatment
Nov 16, 2021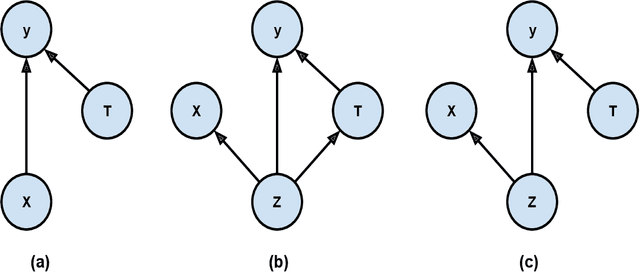


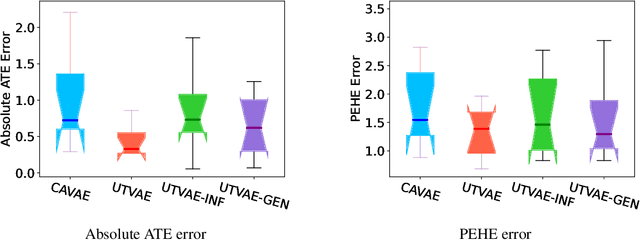
Causal effect variational autoencoder (CEVAE) are trained to predict the outcome given observational treatment data, while uniform treatment variational autoencoders (UTVAE) are trained with uniform treatment distribution using importance sampling. In this paper, we show that using uniform treatment over observational treatment distribution leads to better causal inference by mitigating the distribution shift that occurs from training to test time. We also explore the combination of uniform and observational treatment distributions with inference and generative network training objectives to find a better training procedure for inferring treatment effect. Experimentally, we find that the proposed UTVAE yields better absolute average treatment effect error and precision in estimation of heterogeneous effect error than the CEVAE on synthetic and IHDP datasets.
Online hyperparameter optimization by real-time recurrent learning
Feb 15, 2021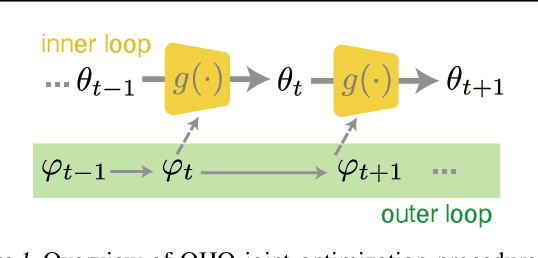
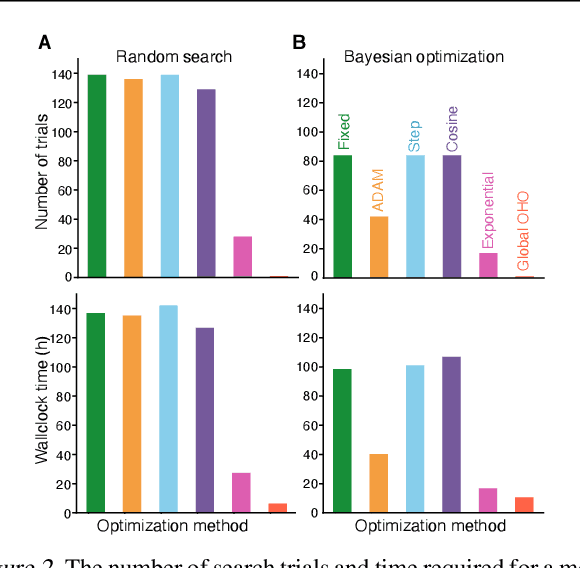
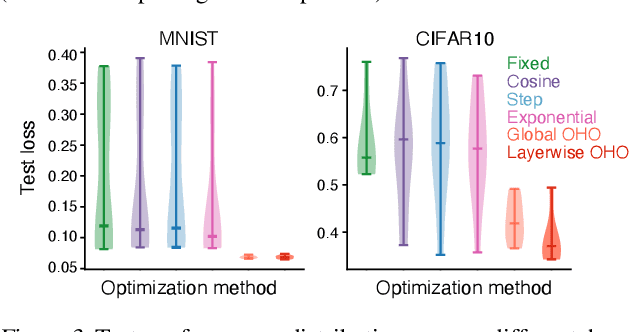
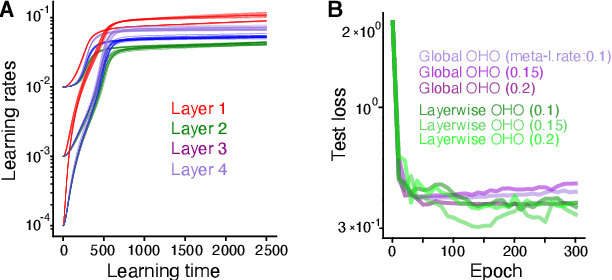
Conventional hyperparameter optimization methods are computationally intensive and hard to generalize to scenarios that require dynamically adapting hyperparameters, such as life-long learning. Here, we propose an online hyperparameter optimization algorithm that is asymptotically exact and computationally tractable, both theoretically and practically. Our framework takes advantage of the analogy between hyperparameter optimization and parameter learning in recurrent neural networks (RNNs). It adapts a well-studied family of online learning algorithms for RNNs to tune hyperparameters and network parameters simultaneously, without repeatedly rolling out iterative optimization. This procedure yields systematically better generalization performance compared to standard methods, at a fraction of wallclock time.
Evaluation metrics for behaviour modeling
Jul 23, 2020
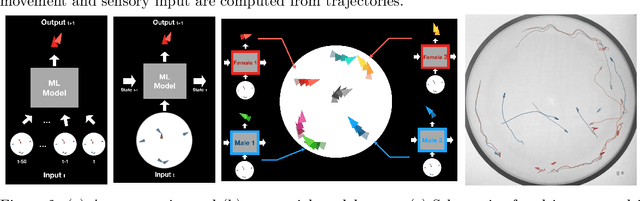
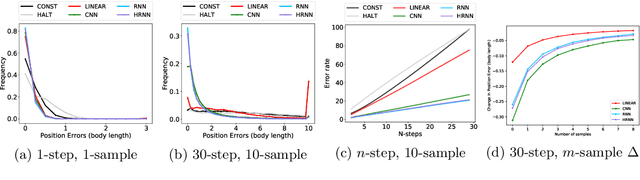

A primary difficulty with unsupervised discovery of structure in large data sets is a lack of quantitative evaluation criteria. In this work, we propose and investigate several metrics for evaluating and comparing generative models of behavior learned using imitation learning. Compared to the commonly-used model log-likelihood, these criteria look at longer temporal relationships in behavior, are relevant if behavior has some properties that are inherently unpredictable, and highlight biases in the overall distribution of behaviors produced by the model. Pointwise metrics compare real to model-predicted trajectories given true past information. Distribution metrics compare statistics of the model simulating behavior in open loop, and are inspired by how experimental biologists evaluate the effects of manipulations on animal behavior. We show that the proposed metrics correspond with biologists' intuitions about behavior, and allow us to evaluate models, understand their biases, and enable us to propose new research directions.
Are skip connections necessary for biologically plausible learning rules?
Dec 04, 2019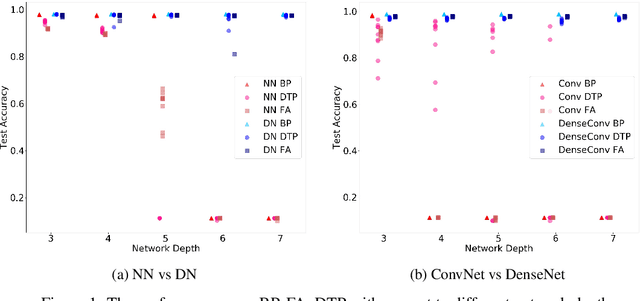
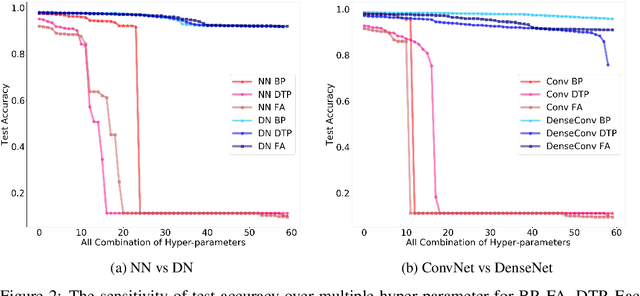
Backpropagation is the workhorse of deep learning, however, several other biologically-motivated learning rules have been introduced, such as random feedback alignment and difference target propagation. None of these methods have produced a competitive performance against backpropagation. In this paper, we show that biologically-motivated learning rules with skip connections between intermediate layers can perform as well as backpropagation on the MNIST dataset and are robust to various sets of hyper-parameters.
Model-Agnostic Meta-Learning using Runge-Kutta Methods
Oct 17, 2019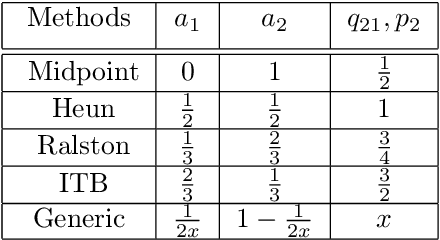
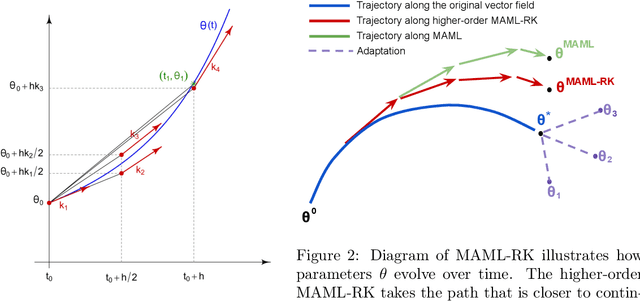
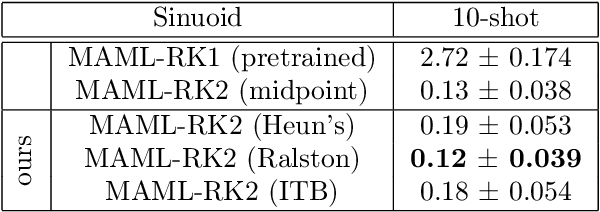
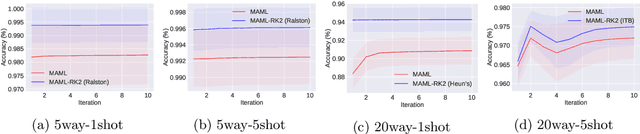
Meta-learning has emerged as an important framework for learning new tasks from just a few examples. The success of any meta-learning model depends on (i) its fast adaptation to new tasks, as well as (ii) having a shared representation across similar tasks. Here we extend the model-agnostic meta-learning (MAML) framework introduced by Finn et al. (2017) to achieve improved performance by analyzing the temporal dynamics of the optimization procedure via the Runge-Kutta method. This method enables us to gain fine-grained control over the optimization and helps us achieve both the adaptation and representation goals across tasks. By leveraging this refined control, we demonstrate that there are multiple principled ways to update MAML and show that the classic MAML optimization is simply a special case of second-order Runge-Kutta method that mainly focuses on fast-adaptation. Experiments on benchmark classification, regression and reinforcement learning tasks show that this refined control helps attain improved results.
Importance Weighted Adversarial Variational Autoencoders for Spike Inference from Calcium Imaging Data
Jun 07, 2019
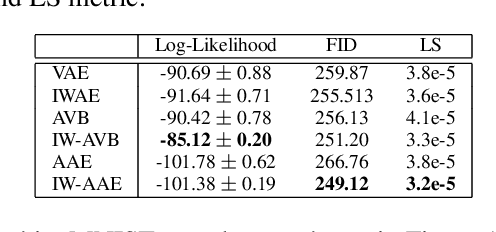
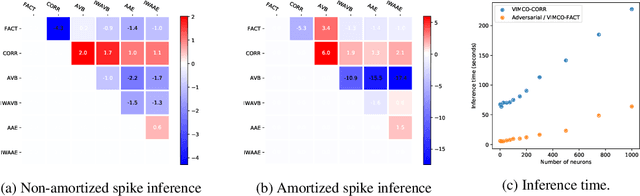
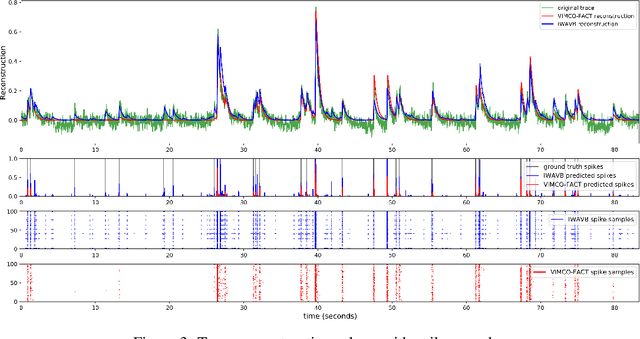
The Importance Weighted Auto Encoder (IWAE) objective has been shown to improve the training of generative models over the standard Variational Auto Encoder (VAE) objective. Here, we derive importance weighted extensions to AVB and AAE. These latent variable models use implicitly defined inference networks whose approximate posterior density q_\phi(z|x) cannot be directly evaluated, an essential ingredient for importance weighting. We show improved training and inference in latent variable models with our adversarially trained importance weighting method, and derive new theoretical connections between adversarial generative model training criteria and marginal likelihood based methods. We apply these methods to the important problem of inferring spiking neural activity from calcium imaging data, a challenging posterior inference problem in neuroscience, and show that posterior samples from the adversarial methods outperform factorized posteriors used in VAEs.
Stochastic Neighbor Embedding under f-divergences
Nov 03, 2018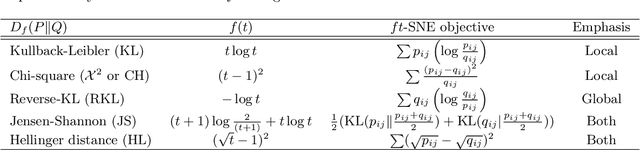
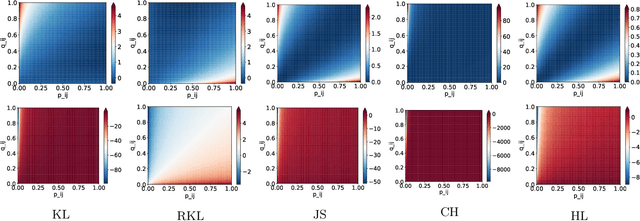
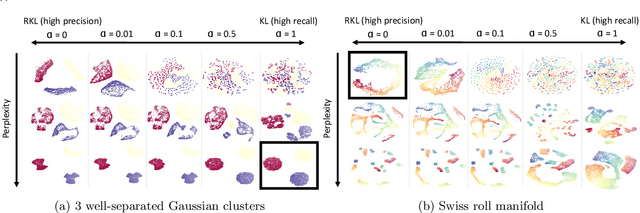
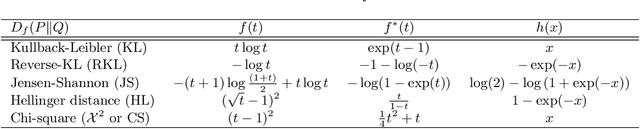
The t-distributed Stochastic Neighbor Embedding (t-SNE) is a powerful and popular method for visualizing high-dimensional data. It minimizes the Kullback-Leibler (KL) divergence between the original and embedded data distributions. In this work, we propose extending this method to other f-divergences. We analytically and empirically evaluate the types of latent structure-manifold, cluster, and hierarchical-that are well-captured using both the original KL-divergence as well as the proposed f-divergence generalization, and find that different divergences perform better for different types of structure. A common concern with $t$-SNE criterion is that it is optimized using gradient descent, and can become stuck in poor local minima. We propose optimizing the f-divergence based loss criteria by minimizing a variational bound. This typically performs better than optimizing the primal form, and our experiments show that it can improve upon the embedding results obtained from the original $t$-SNE criterion as well.