 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining Word-Based Grammatical Error Annotation for L2 Korean
May 28, 2026Korean grammatical error correction (K-GEC) presents a structural mismatch between word-based evaluation and the morpheme-level locus of many learner errors. Postpositions and verbal endings are bound to lexical hosts, but they encode grammatical relations that must be represented in correction and evaluation. This paper refines word-based grammatical error annotation for L2 Korean by addressing three connected problems in existing resources: surface target realization, Korean-specific edit annotation, and single-reference evaluation. We reconstruct target sentences from the National Institute of Korean Language (NIKL) L2 corpus under morphologically constrained realization rules and convert its morpheme-level annotations into word-level \texttt{m2} edits. We then define a Korean ERRANT-style annotation scheme that preserves the MRU core while distinguishing functional morpheme errors, spelling errors, word boundary errors, and word order errors. We also augment the KoLLA corpus with an additional reference correction, yielding a multi-reference evaluation setting for Korean GEC. Empirical validation shows that the refined NIKL targets yield lower perplexity, the converted \texttt{m2} files achieve higher agreement with source-target edit representations, and the refined resources improve KoBART-based correction under the same model setting. Multi-reference KoLLA evaluation further reduces the penalty imposed on valid corrections that diverge from a single reference, especially for neural and prompted GEC systems. These results show that Korean GEC evaluation depends not only on correction models, but also on reference data and edit annotations that reflect Korean morphology, spacing, and correction variability.
KORMo: Korean Open Reasoning Model for Everyone
Oct 10, 2025



This work presents the first large-scale investigation into constructing a fully open bilingual large language model (LLM) for a non-English language, specifically Korean, trained predominantly on synthetic data. We introduce KORMo-10B, a 10.8B-parameter model trained from scratch on a Korean-English corpus in which 68.74% of the Korean portion is synthetic. Through systematic experimentation, we demonstrate that synthetic data, when carefully curated with balanced linguistic coverage and diverse instruction styles, does not cause instability or degradation during large-scale pretraining. Furthermore, the model achieves performance comparable to that of contemporary open-weight multilingual baselines across a wide range of reasoning, knowledge, and instruction-following benchmarks. Our experiments reveal two key findings: (1) synthetic data can reliably sustain long-horizon pretraining without model collapse, and (2) bilingual instruction tuning enables near-native reasoning and discourse coherence in Korean. By fully releasing all components including data, code, training recipes, and logs, this work establishes a transparent framework for developing synthetic data-driven fully open models (FOMs) in low-resource settings and sets a reproducible precedent for future multilingual LLM research.
ScholarBench: A Bilingual Benchmark for Abstraction, Comprehension, and Reasoning Evaluation in Academic Contexts
May 22, 2025



Prior benchmarks for evaluating the domain-specific knowledge of large language models (LLMs) lack the scalability to handle complex academic tasks. To address this, we introduce \texttt{ScholarBench}, a benchmark centered on deep expert knowledge and complex academic problem-solving, which evaluates the academic reasoning ability of LLMs and is constructed through a three-step process. \texttt{ScholarBench} targets more specialized and logically complex contexts derived from academic literature, encompassing five distinct problem types. Unlike prior benchmarks, \texttt{ScholarBench} evaluates the abstraction, comprehension, and reasoning capabilities of LLMs across eight distinct research domains. To ensure high-quality evaluation data, we define category-specific example attributes and design questions that are aligned with the characteristic research methodologies and discourse structures of each domain. Additionally, this benchmark operates as an English-Korean bilingual dataset, facilitating simultaneous evaluation for linguistic capabilities of LLMs in both languages. The benchmark comprises 5,031 examples in Korean and 5,309 in English, with even state-of-the-art models like o3-mini achieving an average evaluation score of only 0.543, demonstrating the challenging nature of this benchmark.
X-LLaVA: Optimizing Bilingual Large Vision-Language Alignment
Apr 01, 2024



The impressive development of large language models (LLMs) is expanding into the realm of large multimodal models (LMMs), which incorporate multiple types of data beyond text. However, the nature of multimodal models leads to significant expenses in the creation of training data. Furthermore, constructing multilingual data for LMMs presents its own set of challenges due to language diversity and complexity. Therefore, in this study, we propose two cost-effective methods to solve this problem: (1) vocabulary expansion and pretraining of multilingual LLM for specific languages, and (2) automatic and elaborate construction of multimodal datasets using GPT4-V. Based on015 these methods, we constructed a 91K English-Korean-Chinese multilingual, multimodal training dataset. Additionally, we developed a bilingual multimodal model that exhibits excellent performance in both Korean and English, surpassing existing approaches.
BOK-VQA: Bilingual Outside Knowledge-based Visual Question Answering via Graph Representation Pretraining
Jan 12, 2024



The current research direction in generative models, such as the recently developed GPT4, aims to find relevant knowledge information for multimodal and multilingual inputs to provide answers. Under these research circumstances, the demand for multilingual evaluation of visual question answering (VQA) tasks, a representative task of multimodal systems, has increased. Accordingly, we propose a bilingual outside-knowledge VQA (BOK-VQA) dataset in this study that can be extended to multilingualism. The proposed data include 17K images, 17K question-answer pairs for both Korean and English and 280K instances of knowledge information related to question-answer content. We also present a framework that can effectively inject knowledge information into a VQA system by pretraining the knowledge information of BOK-VQA data in the form of graph embeddings. Finally, through in-depth analysis, we demonstrated the actual effect of the knowledge information contained in the constructed training data on VQA.
KLUE: Korean Language Understanding Evaluation
Jun 11, 2021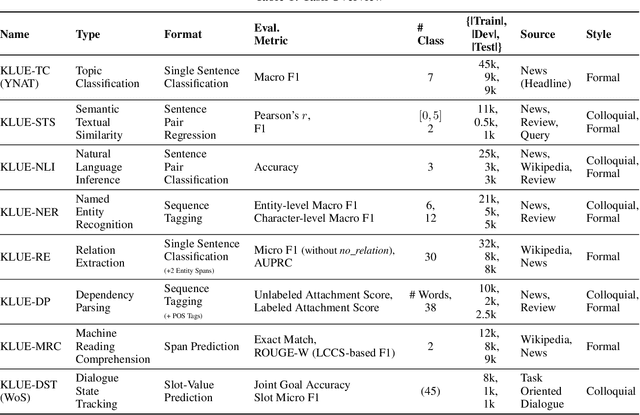
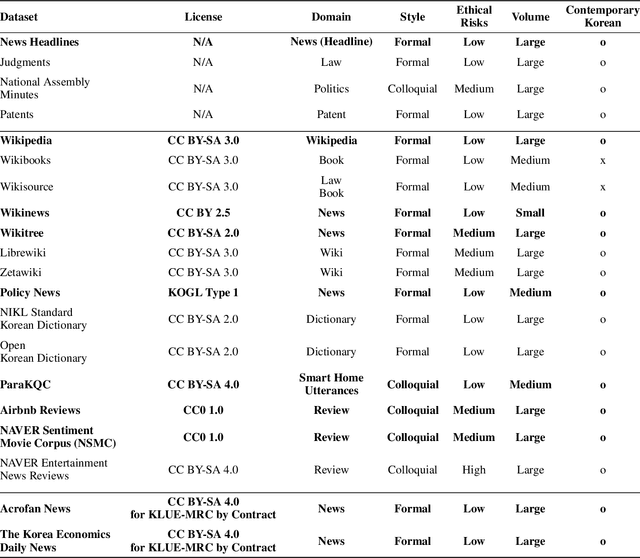
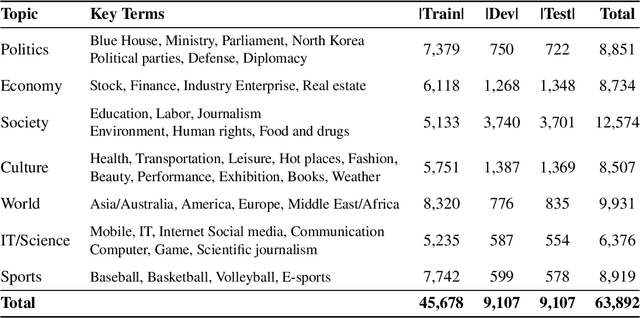
We introduce Korean Language Understanding Evaluation (KLUE) benchmark. KLUE is a collection of 8 Korean natural language understanding (NLU) tasks, including Topic Classification, SemanticTextual Similarity, Natural Language Inference, Named Entity Recognition, Relation Extraction, Dependency Parsing, Machine Reading Comprehension, and Dialogue State Tracking. We build all of the tasks from scratch from diverse source corpora while respecting copyrights, to ensure accessibility for anyone without any restrictions. With ethical considerations in mind, we carefully design annotation protocols. Along with the benchmark tasks and data, we provide suitable evaluation metrics and fine-tuning recipes for pretrained language models for each task. We furthermore release the pretrained language models (PLM), KLUE-BERT and KLUE-RoBERTa, to help reproducing baseline models on KLUE and thereby facilitate future research. We make a few interesting observations from the preliminary experiments using the proposed KLUE benchmark suite, already demonstrating the usefulness of this new benchmark suite. First, we find KLUE-RoBERTa-large outperforms other baselines, including multilingual PLMs and existing open-source Korean PLMs. Second, we see minimal degradation in performance even when we replace personally identifiable information from the pretraining corpus, suggesting that privacy and NLU capability are not at odds with each other. Lastly, we find that using BPE tokenization in combination with morpheme-level pre-tokenization is effective in tasks involving morpheme-level tagging, detection and generation. In addition to accelerating Korean NLP research, our comprehensive documentation on creating KLUE will facilitate creating similar resources for other languages in the future. KLUE is available at https://klue-benchmark.com.