 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSqueezeLLM: Dense-and-Sparse Quantization
Jun 13, 2023



Generative Large Language Models (LLMs) have demonstrated remarkable results for a wide range of tasks. However, deploying these models for inference has been a significant challenge due to their unprecedented resource requirements. This has forced existing deployment frameworks to use multi-GPU inference pipelines, which are often complex and costly, or to use smaller and less performant models. In this work, we demonstrate that the main bottleneck for generative inference with LLMs is memory bandwidth, rather than compute, specifically for single batch inference. While quantization has emerged as a promising solution by representing model weights with reduced precision, previous efforts have often resulted in notable performance degradation. To address this, we introduce SqueezeLLM, a post-training quantization framework that not only enables lossless compression to ultra-low precisions of up to 3-bit, but also achieves higher quantization performance under the same memory constraint. Our framework incorporates two novel ideas: (i) sensitivity-based non-uniform quantization, which searches for the optimal bit precision assignment based on second-order information; and (ii) the Dense-and-Sparse decomposition that stores outliers and sensitive weight values in an efficient sparse format. When applied to the LLaMA models, our 3-bit quantization significantly reduces the perplexity gap from the FP16 baseline by up to 2.1x as compared to the state-of-the-art methods with the same memory requirement. Furthermore, when deployed on an A6000 GPU, our quantized models achieve up to 2.3x speedup compared to the baseline. Our code is open-sourced and available online.
Towards Foundation Models for Scientific Machine Learning: Characterizing Scaling and Transfer Behavior
Jun 01, 2023



Pre-trained machine learning (ML) models have shown great performance for a wide range of applications, in particular in natural language processing (NLP) and computer vision (CV). Here, we study how pre-training could be used for scientific machine learning (SciML) applications, specifically in the context of transfer learning. We study the transfer behavior of these models as (i) the pre-trained model size is scaled, (ii) the downstream training dataset size is scaled, (iii) the physics parameters are systematically pushed out of distribution, and (iv) how a single model pre-trained on a mixture of different physics problems can be adapted to various downstream applications. We find that-when fine-tuned appropriately-transfer learning can help reach desired accuracy levels with orders of magnitude fewer downstream examples (across different tasks that can even be out-of-distribution) than training from scratch, with consistent behavior across a wide range of downstream examples. We also find that fine-tuning these models yields more performance gains as model size increases, compared to training from scratch on new downstream tasks. These results hold for a broad range of PDE learning tasks. All in all, our results demonstrate the potential of the "pre-train and fine-tune" paradigm for SciML problems, demonstrating a path towards building SciML foundation models. We open-source our code for reproducibility.
Flan-MoE: Scaling Instruction-Finetuned Language Models with Sparse Mixture of Experts
May 24, 2023The explosive growth of language models and their applications have led to an increased demand for efficient and scalable methods. In this paper, we introduce Flan-MoE, a set of Instruction-Finetuned Sparse Mixture-of-Expert (MoE) models. We show that naively finetuning MoE models on a task-specific dataset (in other words, no instruction-finetuning) often yield worse performance compared to dense models of the same computational complexity. However, our Flan-MoE outperforms dense models under multiple experiment settings: instruction-finetuning only and instruction-finetuning followed by task-specific finetuning. This shows that instruction-finetuning is an essential stage for MoE models. Specifically, our largest model, Flan-MoE-32B, surpasses the performance of Flan-PaLM-62B on four benchmarks, while utilizing only one-third of the FLOPs. The success of Flan-MoE encourages rethinking the design of large-scale, high-performance language models, under the setting of task-agnostic learning.
Quadric Representations for LiDAR Odometry, Mapping and Localization
Apr 27, 2023



Current LiDAR odometry, mapping and localization methods leverage point-wise representations of 3D scenes and achieve high accuracy in autonomous driving tasks. However, the space-inefficiency of methods that use point-wise representations limits their development and usage in practical applications. In particular, scan-submap matching and global map representation methods are restricted by the inefficiency of nearest neighbor searching (NNS) for large-volume point clouds. To improve space-time efficiency, we propose a novel method of describing scenes using quadric surfaces, which are far more compact representations of 3D objects than conventional point clouds. In contrast to point cloud-based methods, our quadric representation-based method decomposes a 3D scene into a collection of sparse quadric patches, which improves storage efficiency and avoids the slow point-wise NNS process. Our method first segments a given point cloud into patches and fits each of them to a quadric implicit function. Each function is then coupled with other geometric descriptors of the patch, such as its center position and covariance matrix. Collectively, these patch representations fully describe a 3D scene, which can be used in place of the original point cloud and employed in LiDAR odometry, mapping and localization algorithms. We further design a novel incremental growing method for quadric representations, which eliminates the need to repeatedly re-fit quadric surfaces from the original point cloud. Extensive odometry, mapping and localization experiments on large-volume point clouds in the KITTI and UrbanLoco datasets demonstrate that our method maintains low latency and memory utility while achieving competitive, and even superior, accuracy.
SparseFusion: Fusing Multi-Modal Sparse Representations for Multi-Sensor 3D Object Detection
Apr 27, 2023By identifying four important components of existing LiDAR-camera 3D object detection methods (LiDAR and camera candidates, transformation, and fusion outputs), we observe that all existing methods either find dense candidates or yield dense representations of scenes. However, given that objects occupy only a small part of a scene, finding dense candidates and generating dense representations is noisy and inefficient. We propose SparseFusion, a novel multi-sensor 3D detection method that exclusively uses sparse candidates and sparse representations. Specifically, SparseFusion utilizes the outputs of parallel detectors in the LiDAR and camera modalities as sparse candidates for fusion. We transform the camera candidates into the LiDAR coordinate space by disentangling the object representations. Then, we can fuse the multi-modality candidates in a unified 3D space by a lightweight self-attention module. To mitigate negative transfer between modalities, we propose novel semantic and geometric cross-modality transfer modules that are applied prior to the modality-specific detectors. SparseFusion achieves state-of-the-art performance on the nuScenes benchmark while also running at the fastest speed, even outperforming methods with stronger backbones. We perform extensive experiments to demonstrate the effectiveness and efficiency of our modules and overall method pipeline. Our code will be made publicly available at https://github.com/yichen928/SparseFusion.
Open-Vocabulary Point-Cloud Object Detection without 3D Annotation
Apr 03, 2023



The goal of open-vocabulary detection is to identify novel objects based on arbitrary textual descriptions. In this paper, we address open-vocabulary 3D point-cloud detection by a dividing-and-conquering strategy, which involves: 1) developing a point-cloud detector that can learn a general representation for localizing various objects, and 2) connecting textual and point-cloud representations to enable the detector to classify novel object categories based on text prompting. Specifically, we resort to rich image pre-trained models, by which the point-cloud detector learns localizing objects under the supervision of predicted 2D bounding boxes from 2D pre-trained detectors. Moreover, we propose a novel de-biased triplet cross-modal contrastive learning to connect the modalities of image, point-cloud and text, thereby enabling the point-cloud detector to benefit from vision-language pre-trained models,i.e.,CLIP. The novel use of image and vision-language pre-trained models for point-cloud detectors allows for open-vocabulary 3D object detection without the need for 3D annotations. Experiments demonstrate that the proposed method improves at least 3.03 points and 7.47 points over a wide range of baselines on the ScanNet and SUN RGB-D datasets, respectively. Furthermore, we provide a comprehensive analysis to explain why our approach works.
Scaling Vision-Language Models with Sparse Mixture of Experts
Mar 13, 2023The field of natural language processing (NLP) has made significant strides in recent years, particularly in the development of large-scale vision-language models (VLMs). These models aim to bridge the gap between text and visual information, enabling a more comprehensive understanding of multimedia data. However, as these models become larger and more complex, they also become more challenging to train and deploy. One approach to addressing this challenge is the use of sparsely-gated mixture-of-experts (MoE) techniques, which divide the model into smaller, specialized sub-models that can jointly solve a task. In this paper, we explore the effectiveness of MoE in scaling vision-language models, demonstrating its potential to achieve state-of-the-art performance on a range of benchmarks over dense models of equivalent computational cost. Our research offers valuable insights into stabilizing the training of MoE models, understanding the impact of MoE on model interpretability, and balancing the trade-offs between compute performance when scaling VLMs. We hope our work will inspire further research into the use of MoE for scaling large-scale vision-language models and other multimodal machine learning applications.
Full Stack Optimization of Transformer Inference: a Survey
Feb 27, 2023Recent advances in state-of-the-art DNN architecture design have been moving toward Transformer models. These models achieve superior accuracy across a wide range of applications. This trend has been consistent over the past several years since Transformer models were originally introduced. However, the amount of compute and bandwidth required for inference of recent Transformer models is growing at a significant rate, and this has made their deployment in latency-sensitive applications challenging. As such, there has been an increased focus on making Transformer models more efficient, with methods that range from changing the architecture design, all the way to developing dedicated domain-specific accelerators. In this work, we survey different approaches for efficient Transformer inference, including: (i) analysis and profiling of the bottlenecks in existing Transformer architectures and their similarities and differences with previous convolutional models; (ii) implications of Transformer architecture on hardware, including the impact of non-linear operations such as Layer Normalization, Softmax, and GELU, as well as linear operations, on hardware design; (iii) approaches for optimizing a fixed Transformer architecture; (iv) challenges in finding the right mapping and scheduling of operations for Transformer models; and (v) approaches for optimizing Transformer models by adapting the architecture using neural architecture search. Finally, we perform a case study by applying the surveyed optimizations on Gemmini, the open-source, full-stack DNN accelerator generator, and we show how each of these approaches can yield improvements, compared to previous benchmark results on Gemmini. Among other things, we find that a full-stack co-design approach with the aforementioned methods can result in up to 88.7x speedup with a minimal performance degradation for Transformer inference.
Big Little Transformer Decoder
Feb 15, 2023The recent emergence of Large Language Models based on the Transformer architecture has enabled dramatic advancements in the field of Natural Language Processing. However, these models have long inference latency, which limits their deployment, and which makes them prohibitively expensive for various real-time applications. The inference latency is further exacerbated by autoregressive generative tasks, as models need to run iteratively to generate tokens sequentially without leveraging token-level parallelization. To address this, we propose Big Little Decoder (BiLD), a framework that can improve inference efficiency and latency for a wide range of text generation applications. The BiLD framework contains two models with different sizes that collaboratively generate text. The small model runs autoregressively to generate text with a low inference cost, and the large model is only invoked occasionally to refine the small model's inaccurate predictions in a non-autoregressive manner. To coordinate the small and large models, BiLD introduces two simple yet effective policies: (1) the fallback policy that determines when to hand control over to the large model; and (2) the rollback policy that determines when the large model needs to review and correct the small model's inaccurate predictions. To evaluate our framework across different tasks and models, we apply BiLD to various text generation scenarios encompassing machine translation on IWSLT 2017 De-En and WMT 2014 De-En, summarization on CNN/DailyMail, and language modeling on WikiText-2. On an NVIDIA Titan Xp GPU, our framework achieves a speedup of up to 2.13x without any performance drop, and it achieves up to 2.38x speedup with only ~1 point degradation. Furthermore, our framework is fully plug-and-play as it does not require any training or modifications to model architectures. Our code will be open-sourced.
Q-Diffusion: Quantizing Diffusion Models
Feb 10, 2023


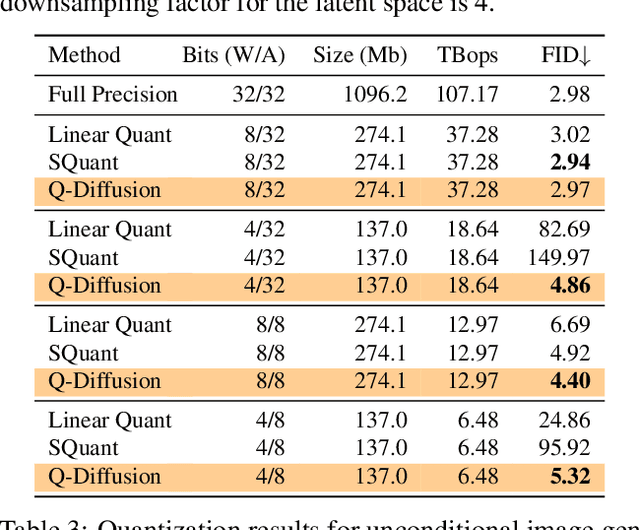
Diffusion models have achieved great success in synthesizing diverse and high-fidelity images. However, sampling speed and memory constraints remain a major barrier to the practical adoption of diffusion models, since the generation process for these models can be slow due to the need for iterative noise estimation using compute-intensive neural networks. We propose to tackle this problem by compressing the noise estimation network to accelerate the generation process through post-training quantization (PTQ). While existing PTQ approaches have not been able to effectively deal with the changing output distributions of noise estimation networks in diffusion models over multiple time steps, we are able to formulate a PTQ method that is specifically designed to handle the unique multi-timestep structure of diffusion models with a data calibration scheme using data sampled from different time steps. Experimental results show that our proposed method is able to directly quantize full-precision diffusion models into 8-bit or 4-bit models while maintaining comparable performance in a training-free manner, achieving a FID change of at most 1.88. Our approach can also be applied to text-guided image generation, and for the first time we can run stable diffusion in 4-bit weights without losing much perceptual quality, as shown in Figure 5 and Figure 9.