 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPEED: Speculative Pipelined Execution for Efficient Decoding
Oct 18, 2023Generative Large Language Models (LLMs) based on the Transformer architecture have recently emerged as a dominant foundation model for a wide range of Natural Language Processing tasks. Nevertheless, their application in real-time scenarios has been highly restricted due to the significant inference latency associated with these models. This is particularly pronounced due to the autoregressive nature of generative LLM inference, where tokens are generated sequentially since each token depends on all previous output tokens. It is therefore challenging to achieve any token-level parallelism, making inference extremely memory-bound. In this work, we propose SPEED, which improves inference efficiency by speculatively executing multiple future tokens in parallel with the current token using predicted values based on early-layer hidden states. For Transformer decoders that employ parameter sharing, the memory operations for the tokens executing in parallel can be amortized, which allows us to accelerate generative LLM inference. We demonstrate the efficiency of our method in terms of latency reduction relative to model accuracy and demonstrate how speculation allows for training deeper decoders with parameter sharing with minimal runtime overhead.
MoCA: Memory-Centric, Adaptive Execution for Multi-Tenant Deep Neural Networks
May 10, 2023



Driven by the wide adoption of deep neural networks (DNNs) across different application domains, multi-tenancy execution, where multiple DNNs are deployed simultaneously on the same hardware, has been proposed to satisfy the latency requirements of different applications while improving the overall system utilization. However, multi-tenancy execution could lead to undesired system-level resource contention, causing quality-of-service (QoS) degradation for latency-critical applications. To address this challenge, we propose MoCA, an adaptive multi-tenancy system for DNN accelerators. Unlike existing solutions that focus on compute resource partition, MoCA dynamically manages shared memory resources of co-located applications to meet their QoS targets. Specifically, MoCA leverages the regularities in both DNN operators and accelerators to dynamically modulate memory access rates based on their latency targets and user-defined priorities so that co-located applications get the resources they demand without significantly starving their co-runners. We demonstrate that MoCA improves the satisfaction rate of the service level agreement (SLA) up to 3.9x (1.8x average), system throughput by 2.3x (1.7x average), and fairness by 1.3x (1.2x average), compared to prior work.
Full Stack Optimization of Transformer Inference: a Survey
Feb 27, 2023Recent advances in state-of-the-art DNN architecture design have been moving toward Transformer models. These models achieve superior accuracy across a wide range of applications. This trend has been consistent over the past several years since Transformer models were originally introduced. However, the amount of compute and bandwidth required for inference of recent Transformer models is growing at a significant rate, and this has made their deployment in latency-sensitive applications challenging. As such, there has been an increased focus on making Transformer models more efficient, with methods that range from changing the architecture design, all the way to developing dedicated domain-specific accelerators. In this work, we survey different approaches for efficient Transformer inference, including: (i) analysis and profiling of the bottlenecks in existing Transformer architectures and their similarities and differences with previous convolutional models; (ii) implications of Transformer architecture on hardware, including the impact of non-linear operations such as Layer Normalization, Softmax, and GELU, as well as linear operations, on hardware design; (iii) approaches for optimizing a fixed Transformer architecture; (iv) challenges in finding the right mapping and scheduling of operations for Transformer models; and (v) approaches for optimizing Transformer models by adapting the architecture using neural architecture search. Finally, we perform a case study by applying the surveyed optimizations on Gemmini, the open-source, full-stack DNN accelerator generator, and we show how each of these approaches can yield improvements, compared to previous benchmark results on Gemmini. Among other things, we find that a full-stack co-design approach with the aforementioned methods can result in up to 88.7x speedup with a minimal performance degradation for Transformer inference.
ProTuner: Tuning Programs with Monte Carlo Tree Search
May 27, 2020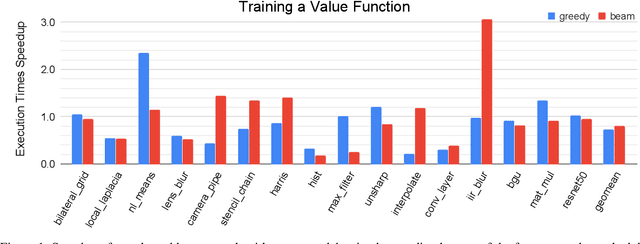

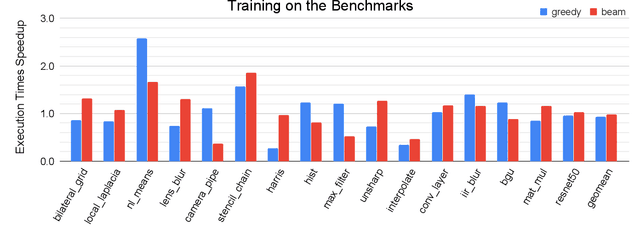
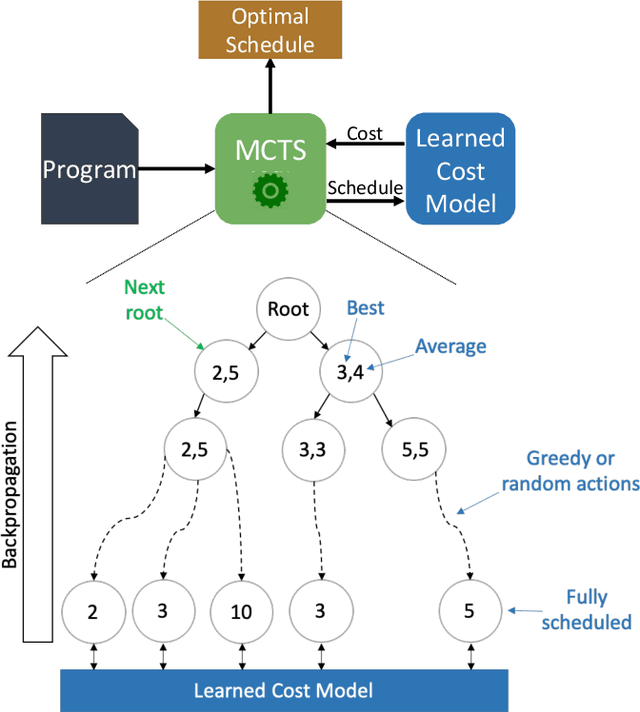
We explore applying the Monte Carlo Tree Search (MCTS) algorithm in a notoriously difficult task: tuning programs for high-performance deep learning and image processing. We build our framework on top of Halide and show that MCTS can outperform the state-of-the-art beam-search algorithm. Unlike beam search, which is guided by greedy intermediate performance comparisons between partial and less meaningful schedules, MCTS compares complete schedules and looks ahead before making any intermediate scheduling decision. We further explore modifications to the standard MCTS algorithm as well as combining real execution time measurements with the cost model. Our results show that MCTS can outperform beam search on a suite of 16 real benchmarks.
Gemmini: An Agile Systolic Array Generator Enabling Systematic Evaluations of Deep-Learning Architectures
Dec 07, 2019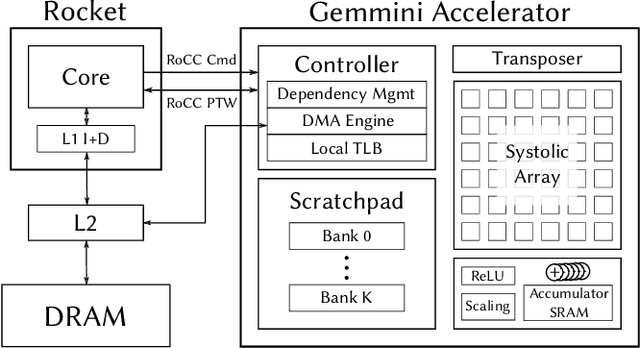
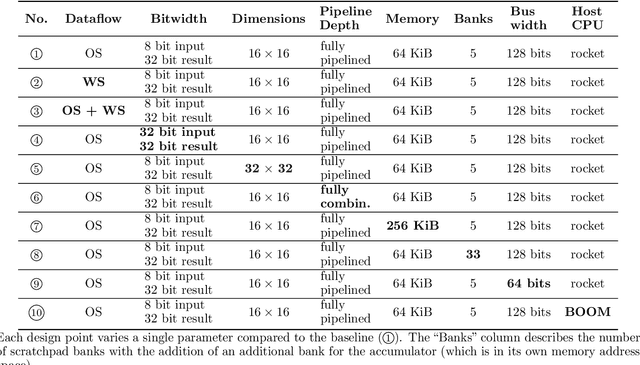
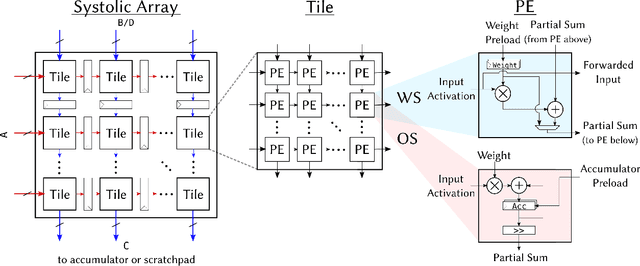
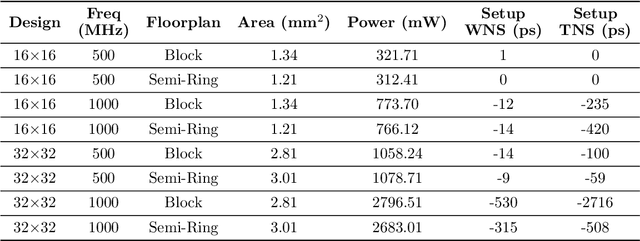
Advances in deep learning and neural networks have resulted in the rapid development of hardware accelerators that support them. A large majority of ASIC accelerators, however, target a single hardware design point to accelerate the main computational kernels of deep neural networks such as convolutions or matrix multiplication. On the other hand, the spectrum of use-cases for neural network accelerators, ranging from edge devices to cloud, presents a prime opportunity for agile hardware design and generator methodologies. We present Gemmini -- an open source and agile systolic array generator enabling systematic evaluations of deep-learning architectures. Gemmini generates a custom ASIC accelerator for matrix multiplication based on a systolic array architecture, complete with additional functions for neural network inference. Gemmini runs with the RISC-V ISA, and is integrated with the Rocket Chip System-on-Chip generator ecosystem, including Rocket in-order cores and BOOM out-of-order cores. Through an elaborate design space exploration case study, this work demonstrates the selection processes of various parameters for the use-case of inference on edge devices. Selected design points achieve two to three orders of magnitude speedup in deep neural network inference compared to the baseline execution on a host processor. Gemmini-generated accelerators were used in the fabrication of test systems-on-chip in TSMC 16nm and Intel 22FFL process technologies.
The Role of Compute in Autonomous Aerial Vehicles
Jun 24, 2019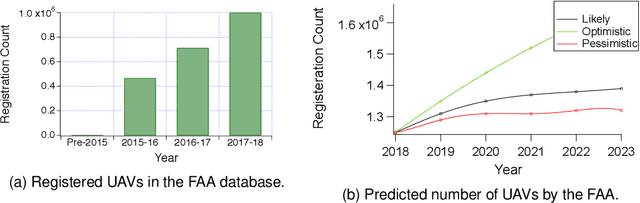
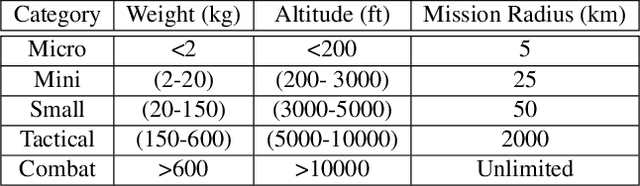

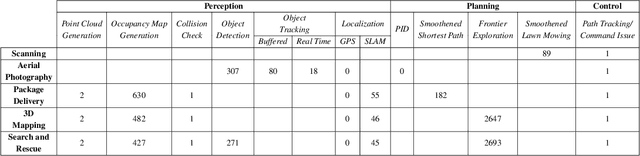
Autonomous-mobile cyber-physical machines are part of our future. Specifically, unmanned-aerial-vehicles have seen a resurgence in activity with use-cases such as package delivery. These systems face many challenges such as their low-endurance caused by limited onboard-energy, hence, improving the mission-time and energy are of importance. Such improvements traditionally are delivered through better algorithms. But our premise is that more powerful and efficient onboard-compute should also address the problem. This paper investigates how the compute subsystem, in a cyber-physical mobile machine, such as a Micro Aerial Vehicle, impacts mission-time and energy. Specifically, we pose the question as what is the role of computing for cyber-physical mobile robots? We show that compute and motion are tightly intertwined, hence a close examination of cyber and physical processes and their impact on one another is necessary. We show different impact paths through which compute impacts mission-metrics and examine them using analytical models, simulation, and end-to-end benchmarking. To enable similar studies, we open sourced MAVBench, our tool-set consisting of a closed-loop simulator and a benchmark suite. Our investigations show cyber-physical co-design, a methodology where robot's cyber and physical processes/quantities are developed with one another consideration, similar to hardware-software co-design, is necessary for optimal robot design.
MAVBench: Micro Aerial Vehicle Benchmarking
Jun 01, 2019
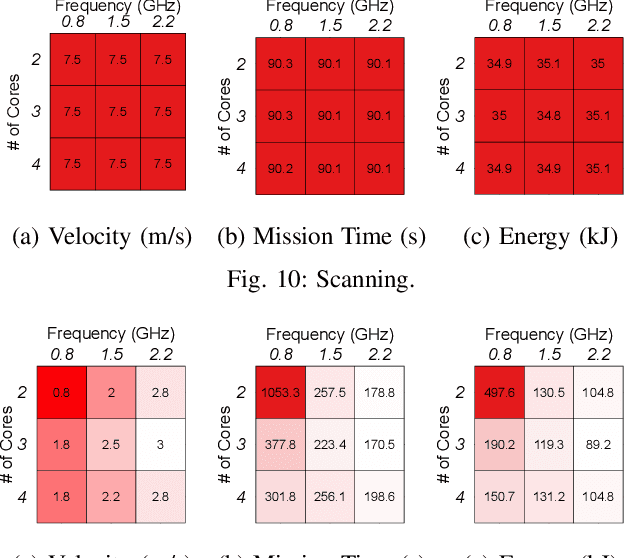
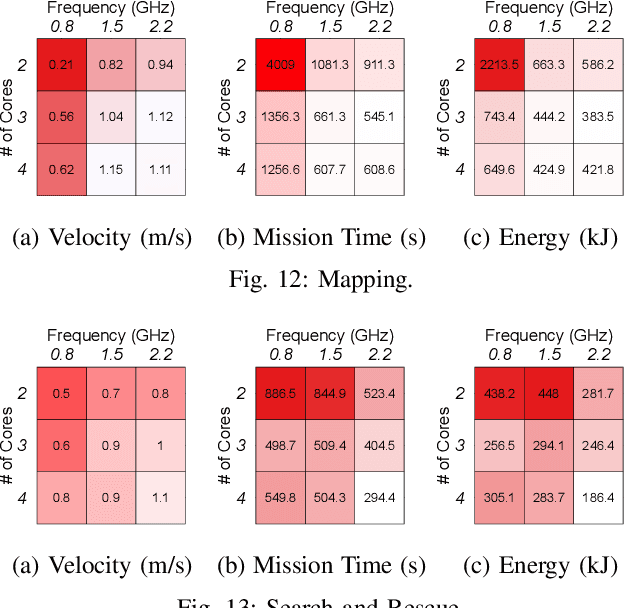
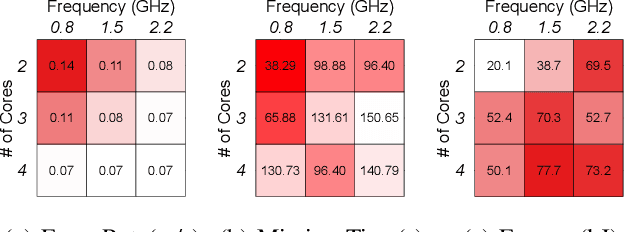
Unmanned Aerial Vehicles (UAVs) are getting closer to becoming ubiquitous in everyday life. Among them, Micro Aerial Vehicles (MAVs) have seen an outburst of attention recently, specifically in the area with a demand for autonomy. A key challenge standing in the way of making MAVs autonomous is that researchers lack the comprehensive understanding of how performance, power, and computational bottlenecks affect MAV applications. MAVs must operate under a stringent power budget, which severely limits their flight endurance time. As such, there is a need for new tools, benchmarks, and methodologies to foster the systematic development of autonomous MAVs. In this paper, we introduce the `MAVBench' framework which consists of a closed-loop simulator and an end-to-end application benchmark suite. A closed-loop simulation platform is needed to probe and understand the intra-system (application data flow) and inter-system (system and environment) interactions in MAV applications to pinpoint bottlenecks and identify opportunities for hardware and software co-design and optimization. In addition to the simulator, MAVBench provides a benchmark suite, the first of its kind, consisting of a variety of MAV applications designed to enable computer architects to perform characterization and develop future aerial computing systems. Using our open source, end-to-end experimental platform, we uncover a hidden, and thus far unexpected compute to total system energy relationship in MAVs. Furthermore, we explore the role of compute by presenting three case studies targeting performance, energy and reliability. These studies confirm that an efficient system design can improve MAV's battery consumption by up to 1.8X.
Domain Specific Approximation for Object Detection
Oct 04, 2018
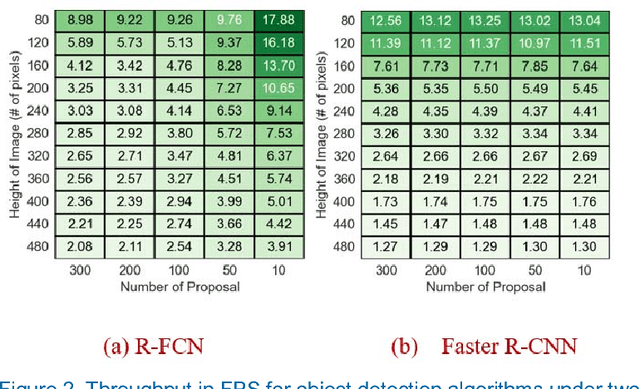
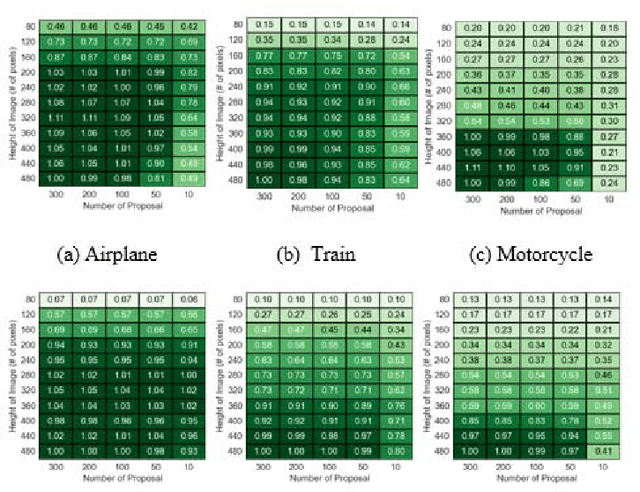

There is growing interest in object detection in advanced driver assistance systems and autonomous robots and vehicles. To enable such innovative systems, we need faster object detection. In this work, we investigate the trade-off between accuracy and speed with domain-specific approximations, i.e. category-aware image size scaling and proposals scaling, for two state-of-the-art deep learning-based object detection meta-architectures. We study the effectiveness of applying approximation both statically and dynamically to understand the potential and the applicability of them. By conducting experiments on the ImageNet VID dataset, we show that domain-specific approximation has great potential to improve the speed of the system without deteriorating the accuracy of object detectors, i.e. up to 7.5x speedup for dynamic domain-specific approximation. To this end, we present our insights toward harvesting domain-specific approximation as well as devise a proof-of-concept runtime, AutoFocus, that exploits dynamic domain-specific approximation.
* 6 pages, 6 figures. Published in IEEE Micro, vol. 38, no. 1, pp. 31-40, January/February 2018