 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRayZer: A Self-supervised Large View Synthesis Model
May 01, 2025



We present RayZer, a self-supervised multi-view 3D Vision model trained without any 3D supervision, i.e., camera poses and scene geometry, while exhibiting emerging 3D awareness. Concretely, RayZer takes unposed and uncalibrated images as input, recovers camera parameters, reconstructs a scene representation, and synthesizes novel views. During training, RayZer relies solely on its self-predicted camera poses to render target views, eliminating the need for any ground-truth camera annotations and allowing RayZer to be trained with 2D image supervision. The emerging 3D awareness of RayZer is attributed to two key factors. First, we design a self-supervised framework, which achieves 3D-aware auto-encoding of input images by disentangling camera and scene representations. Second, we design a transformer-based model in which the only 3D prior is the ray structure, connecting camera, pixel, and scene simultaneously. RayZer demonstrates comparable or even superior novel view synthesis performance than ``oracle'' methods that rely on pose annotations in both training and testing. Project: https://hwjiang1510.github.io/RayZer/
Retrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey
Apr 21, 2025



Recent advancements in Retrieval-Augmented Generation (RAG) have revolutionized natural language processing by integrating Large Language Models (LLMs) with external information retrieval, enabling accurate, up-to-date, and verifiable text generation across diverse applications. However, evaluating RAG systems presents unique challenges due to their hybrid architecture that combines retrieval and generation components, as well as their dependence on dynamic knowledge sources in the LLM era. In response, this paper provides a comprehensive survey of RAG evaluation methods and frameworks, systematically reviewing traditional and emerging evaluation approaches, for system performance, factual accuracy, safety, and computational efficiency in the LLM era. We also compile and categorize the RAG-specific datasets and evaluation frameworks, conducting a meta-analysis of evaluation practices in high-impact RAG research. To the best of our knowledge, this work represents the most comprehensive survey for RAG evaluation, bridging traditional and LLM-driven methods, and serves as a critical resource for advancing RAG development.
Towards Realistic Low-Light Image Enhancement via ISP Driven Data Modeling
Apr 16, 2025



Deep neural networks (DNNs) have recently become the leading method for low-light image enhancement (LLIE). However, despite significant progress, their outputs may still exhibit issues such as amplified noise, incorrect white balance, or unnatural enhancements when deployed in real world applications. A key challenge is the lack of diverse, large scale training data that captures the complexities of low-light conditions and imaging pipelines. In this paper, we propose a novel image signal processing (ISP) driven data synthesis pipeline that addresses these challenges by generating unlimited paired training data. Specifically, our pipeline begins with easily collected high-quality normal-light images, which are first unprocessed into the RAW format using a reverse ISP. We then synthesize low-light degradations directly in the RAW domain. The resulting data is subsequently processed through a series of ISP stages, including white balance adjustment, color space conversion, tone mapping, and gamma correction, with controlled variations introduced at each stage. This broadens the degradation space and enhances the diversity of the training data, enabling the generated data to capture a wide range of degradations and the complexities inherent in the ISP pipeline. To demonstrate the effectiveness of our synthetic pipeline, we conduct extensive experiments using a vanilla UNet model consisting solely of convolutional layers, group normalization, GeLU activation, and convolutional block attention modules (CBAMs). Extensive testing across multiple datasets reveals that the vanilla UNet model trained with our data synthesis pipeline delivers high fidelity, visually appealing enhancement results, surpassing state-of-the-art (SOTA) methods both quantitatively and qualitatively.
Gaussian Mixture Flow Matching Models
Apr 07, 2025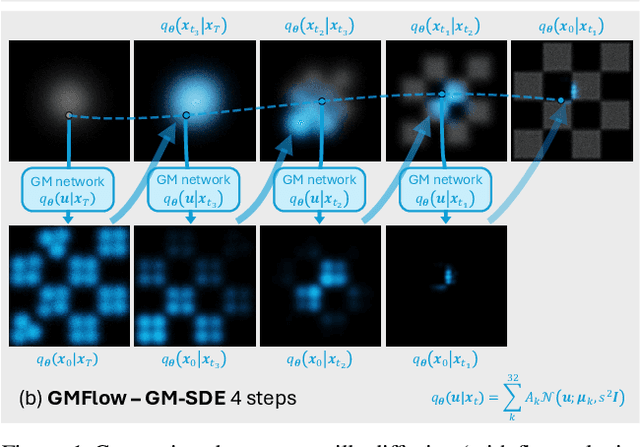
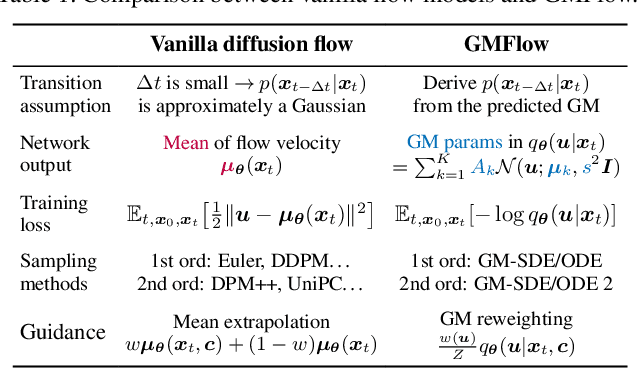
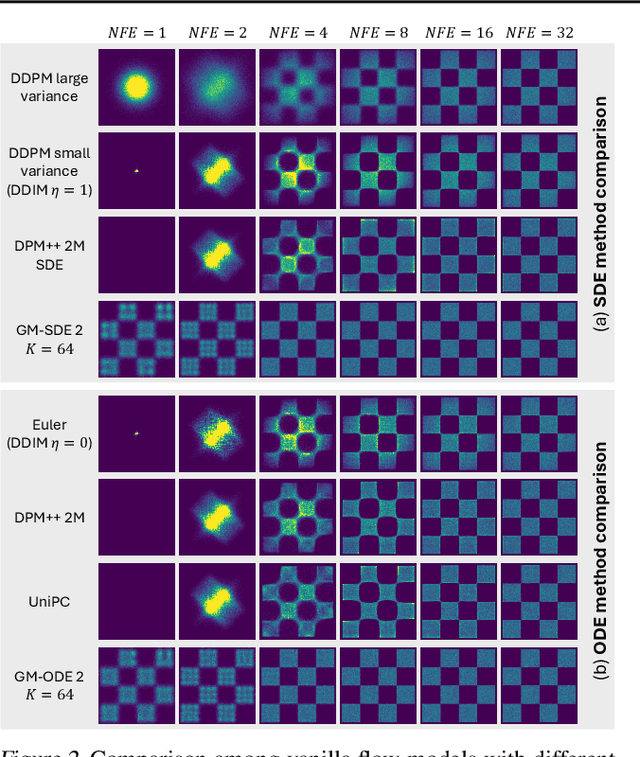
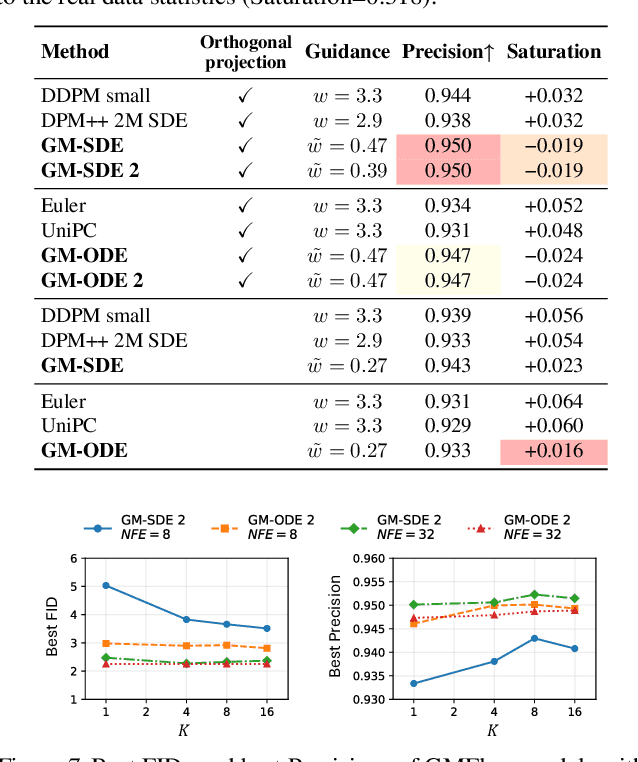
Diffusion models approximate the denoising distribution as a Gaussian and predict its mean, whereas flow matching models reparameterize the Gaussian mean as flow velocity. However, they underperform in few-step sampling due to discretization error and tend to produce over-saturated colors under classifier-free guidance (CFG). To address these limitations, we propose a novel Gaussian mixture flow matching (GMFlow) model: instead of predicting the mean, GMFlow predicts dynamic Gaussian mixture (GM) parameters to capture a multi-modal flow velocity distribution, which can be learned with a KL divergence loss. We demonstrate that GMFlow generalizes previous diffusion and flow matching models where a single Gaussian is learned with an $L_2$ denoising loss. For inference, we derive GM-SDE/ODE solvers that leverage analytic denoising distributions and velocity fields for precise few-step sampling. Furthermore, we introduce a novel probabilistic guidance scheme that mitigates the over-saturation issues of CFG and improves image generation quality. Extensive experiments demonstrate that GMFlow consistently outperforms flow matching baselines in generation quality, achieving a Precision of 0.942 with only 6 sampling steps on ImageNet 256$\times$256.
Enhancing Knowledge Graph Completion with Entity Neighborhood and Relation Context
Mar 29, 2025Knowledge Graph Completion (KGC) aims to infer missing information in Knowledge Graphs (KGs) to address their inherent incompleteness. Traditional structure-based KGC methods, while effective, face significant computational demands and scalability challenges due to the need for dense embedding learning and scoring all entities in the KG for each prediction. Recent text-based approaches using language models like T5 and BERT have mitigated these issues by converting KG triples into text for reasoning. However, they often fail to fully utilize contextual information, focusing mainly on the neighborhood of the entity and neglecting the context of the relation. To address this issue, we propose KGC-ERC, a framework that integrates both types of context to enrich the input of generative language models and enhance their reasoning capabilities. Additionally, we introduce a sampling strategy to effectively select relevant context within input token constraints, which optimizes the utilization of contextual information and potentially improves model performance. Experiments on the Wikidata5M, Wiki27K, and FB15K-237-N datasets show that KGC-ERC outperforms or matches state-of-the-art baselines in predictive performance and scalability.
A Theoretical Analysis of Analogy-Based Evolutionary Transfer Optimization
Mar 27, 2025



Evolutionary transfer optimization (ETO) has been gaining popularity in research over the years due to its outstanding knowledge transfer ability to address various challenges in optimization. However, a pressing issue in this field is that the invention of new ETO algorithms has far outpaced the development of fundamental theories needed to clearly understand the key factors contributing to the success of these algorithms for effective generalization. In response to this challenge, this study aims to establish theoretical foundations for analogy-based ETO, specifically to support various algorithms that frequently reference a key concept known as similarity. First, we introduce analogical reasoning and link its subprocesses to three key issues in ETO. Then, we develop theories for analogy-based knowledge transfer, rooted in the principles that underlie the subprocesses. Afterwards, we present two theorems related to the performance gain of analogy-based knowledge transfer, namely unconditionally nonnegative performance gain and conditionally positive performance gain, to theoretically demonstrate the effectiveness of various analogy-based ETO methods. Last but not least, we offer a novel insight into analogy-based ETO that interprets its conditional superiority over traditional evolutionary optimization through the lens of the no free lunch theorem for optimization.
Communication-Efficient Distributed On-Device LLM Inference Over Wireless Networks
Mar 19, 2025Large language models (LLMs) have demonstrated remarkable success across various application domains, but their enormous sizes and computational demands pose significant challenges for deployment on resource-constrained edge devices. To address this issue, we propose a novel distributed on-device LLM inference framework that leverages tensor parallelism to partition the neural network tensors (e.g., weight matrices) of one LLM across multiple edge devices for collaborative inference. A key challenge in tensor parallelism is the frequent all-reduce operations for aggregating intermediate layer outputs across participating devices, which incurs significant communication overhead. To alleviate this bottleneck, we propose an over-the-air computation (AirComp) approach that harnesses the analog superposition property of wireless multiple-access channels to perform fast all-reduce steps. To utilize the heterogeneous computational capabilities of edge devices and mitigate communication distortions, we investigate a joint model assignment and transceiver optimization problem to minimize the average transmission error. The resulting mixed-timescale stochastic non-convex optimization problem is intractable, and we propose an efficient two-stage algorithm to solve it. Moreover, we prove that the proposed algorithm converges almost surely to a stationary point of the original problem. Comprehensive simulation results will show that the proposed framework outperforms existing benchmark schemes, achieving up to 5x inference speed acceleration and improving inference accuracy.
Towards Understanding Graphical Perception in Large Multimodal Models
Mar 13, 2025Despite the promising results of large multimodal models (LMMs) in complex vision-language tasks that require knowledge, reasoning, and perception abilities together, we surprisingly found that these models struggle with simple tasks on infographics that require perception only. As existing benchmarks primarily focus on end tasks that require various abilities, they provide limited, fine-grained insights into the limitations of the models' perception abilities. To address this gap, we leverage the theory of graphical perception, an approach used to study how humans decode visual information encoded on charts and graphs, to develop an evaluation framework for analyzing gaps in LMMs' perception abilities in charts. With automated task generation and response evaluation designs, our framework enables comprehensive and controlled testing of LMMs' graphical perception across diverse chart types, visual elements, and task types. We apply our framework to evaluate and diagnose the perception capabilities of state-of-the-art LMMs at three granularity levels (chart, visual element, and pixel). Our findings underscore several critical limitations of current state-of-the-art LMMs, including GPT-4o: their inability to (1) generalize across chart types, (2) understand fundamental visual elements, and (3) cross reference values within a chart. These insights provide guidance for future improvements in perception abilities of LMMs. The evaluation framework and labeled data are publicly available at https://github.com/microsoft/lmm-graphical-perception.
Structured Outputs Enable General-Purpose LLMs to be Medical Experts
Mar 05, 2025Medical question-answering (QA) is a critical task for evaluating how effectively large language models (LLMs) encode clinical knowledge and assessing their potential applications in medicine. Despite showing promise on multiple-choice tests, LLMs frequently struggle with open-ended medical questions, producing responses with dangerous hallucinations or lacking comprehensive coverage of critical aspects. Existing approaches attempt to address these challenges through domain-specific fine-tuning, but this proves resource-intensive and difficult to scale across models. To improve the comprehensiveness and factuality of medical responses, we propose a novel approach utilizing structured medical reasoning. Our method guides LLMs through an seven-step cognitive process inspired by clinical diagnosis, enabling more accurate and complete answers without additional training. Experiments on the MedLFQA benchmark demonstrate that our approach achieves the highest Factuality Score of 85.8, surpassing fine-tuned models. Notably, this improvement transfers to smaller models, highlighting the method's efficiency and scalability. Our code and datasets are available.
Discrete Differential Evolution Particle Swarm Optimization Algorithm for Energy Saving Flexible Job Shop Scheduling Problem Considering Machine Multi States
Mar 04, 2025As the continuous deepening of low-carbon emission reduction policies, the manufacturing industries urgently need sensible energy-saving scheduling schemes to achieve the balance between improving production efficiency and reducing energy consumption. In energy-saving scheduling, reasonable machine states-switching is a key point to achieve expected goals, i.e., whether the machines need to switch speed between different operations, and whether the machines need to add extra setup time between different jobs. Regarding this matter, this work proposes a novel machine multi states-based energy saving flexible job scheduling problem (EFJSP-M), which simultaneously takes into account machine multi speeds and setup time. To address the proposed EFJSP-M, a kind of discrete differential evolution particle swarm optimization algorithm (D-DEPSO) is designed. In specific, D-DEPSO includes a hybrid initialization strategy to improve the initial population performance, an updating mechanism embedded with differential evolution operators to enhance population diversity, and a critical path variable neighborhood search strategy to expand the solution space. At last, based on datasets DPs and MKs, the experiment results compared with five state-of-the-art algorithms demonstrate the feasible of EFJSP-M and the superior of D-DEPSO.