 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMO-RiskVAE: A Multi-Omics Variational Autoencoder for Survival Risk Modeling in Multiple MyelomaMO-RiskVAE
Apr 07, 2026Multimodal variational autoencoders (VAEs) have emerged as a powerful framework for survival risk modeling in multiple myeloma by integrating heterogeneous omics and clinical data. However, when trained under survival supervision, standard latent regularization strategies often fail to preserve prognostically relevant variation, leading to unstable or overly constrained representations. Despite numerous proposed variants, it remains unclear which aspects of latent design fundamentally govern performance in this setting. In this work, we conduct a controlled investigation of latent modeling choices for multimodal survival prediction within a unified extension of the MyeVAE framework. By systematically isolating regularization scale, posterior geometry, and latent space structure under identical architectures and optimization protocols, we show that survival-driven training is primarily sensitive to the magnitude and structure of latent regularization rather than the specific divergence formulation. In particular, moderate relaxation of KL regularization consistently improves survival discrimination, while alternative divergence mechanisms such as MMD and HSIC provide limited benefit without appropriate scaling. We further demonstrate that structuring the latent space can improve alignment between learned representations and survival risk gradients. A hybrid continuous--discrete formulation based on Gumbel--Softmax enhances global risk ordering in the continuous latent subspace, even though stable discrete subtype discovery does not emerge under survival supervision. Guided by these findings, we instantiate a robust multimodal survival model, termed MO-RiskVAE, which consistently improves risk stratification over the original MyeVAE without introducing additional supervision or complex training heuristics.
Goal-Guided Efficient Exploration via Large Language Model in Reinforcement Learning
Sep 26, 2025Real-world decision-making tasks typically occur in complex and open environments, posing significant challenges to reinforcement learning (RL) agents' exploration efficiency and long-horizon planning capabilities. A promising approach is LLM-enhanced RL, which leverages the rich prior knowledge and strong planning capabilities of LLMs to guide RL agents in efficient exploration. However, existing methods mostly rely on frequent and costly LLM invocations and suffer from limited performance due to the semantic mismatch. In this paper, we introduce a Structured Goal-guided Reinforcement Learning (SGRL) method that integrates a structured goal planner and a goal-conditioned action pruner to guide RL agents toward efficient exploration. Specifically, the structured goal planner utilizes LLMs to generate a reusable, structured function for goal generation, in which goals are prioritized. Furthermore, by utilizing LLMs to determine goals' priority weights, it dynamically generates forward-looking goals to guide the agent's policy toward more promising decision-making trajectories. The goal-conditioned action pruner employs an action masking mechanism that filters out actions misaligned with the current goal, thereby constraining the RL agent to select goal-consistent policies. We evaluate the proposed method on Crafter and Craftax-Classic, and experimental results demonstrate that SGRL achieves superior performance compared to existing state-of-the-art methods.
Discrete Differential Evolution Particle Swarm Optimization Algorithm for Energy Saving Flexible Job Shop Scheduling Problem Considering Machine Multi States
Mar 04, 2025As the continuous deepening of low-carbon emission reduction policies, the manufacturing industries urgently need sensible energy-saving scheduling schemes to achieve the balance between improving production efficiency and reducing energy consumption. In energy-saving scheduling, reasonable machine states-switching is a key point to achieve expected goals, i.e., whether the machines need to switch speed between different operations, and whether the machines need to add extra setup time between different jobs. Regarding this matter, this work proposes a novel machine multi states-based energy saving flexible job scheduling problem (EFJSP-M), which simultaneously takes into account machine multi speeds and setup time. To address the proposed EFJSP-M, a kind of discrete differential evolution particle swarm optimization algorithm (D-DEPSO) is designed. In specific, D-DEPSO includes a hybrid initialization strategy to improve the initial population performance, an updating mechanism embedded with differential evolution operators to enhance population diversity, and a critical path variable neighborhood search strategy to expand the solution space. At last, based on datasets DPs and MKs, the experiment results compared with five state-of-the-art algorithms demonstrate the feasible of EFJSP-M and the superior of D-DEPSO.
TME-BNA: Temporal Motif-Preserving Network Embedding with Bicomponent Neighbor Aggregation
Oct 26, 2021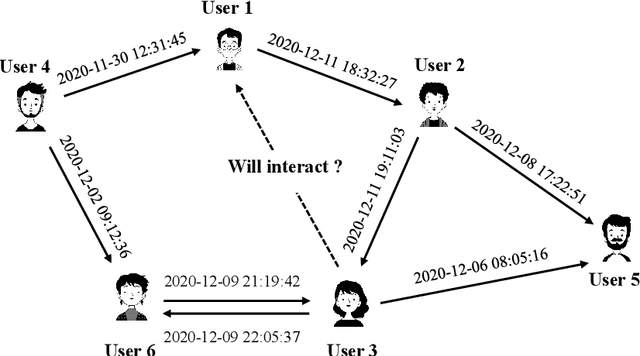
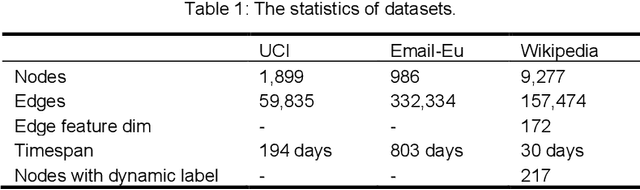
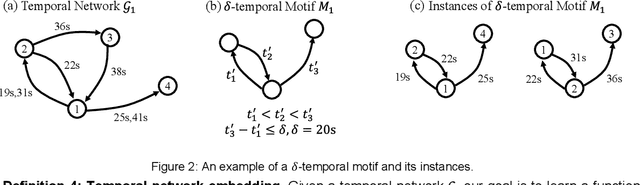
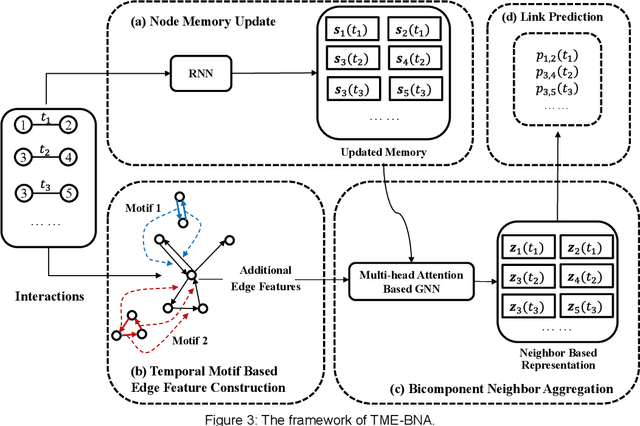
Evolving temporal networks serve as the abstractions of many real-life dynamic systems, e.g., social network and e-commerce. The purpose of temporal network embedding is to map each node to a time-evolving low-dimension vector for downstream tasks, e.g., link prediction and node classification. The difficulty of temporal network embedding lies in how to utilize the topology and time information jointly to capture the evolution of a temporal network. In response to this challenge, we propose a temporal motif-preserving network embedding method with bicomponent neighbor aggregation, named TME-BNA. Considering that temporal motifs are essential to the understanding of topology laws and functional properties of a temporal network, TME-BNA constructs additional edge features based on temporal motifs to explicitly utilize complex topology with time information. In order to capture the topology dynamics of nodes, TME-BNA utilizes Graph Neural Networks (GNNs) to aggregate the historical and current neighbors respectively according to the timestamps of connected edges. Experiments are conducted on three public temporal network datasets, and the results show the effectiveness of TME-BNA.
Multi-Relation Aware Temporal Interaction Network Embedding
Oct 09, 2021
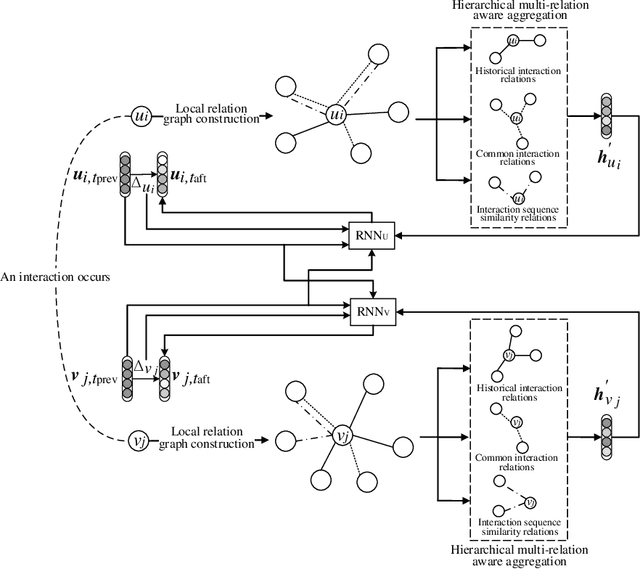
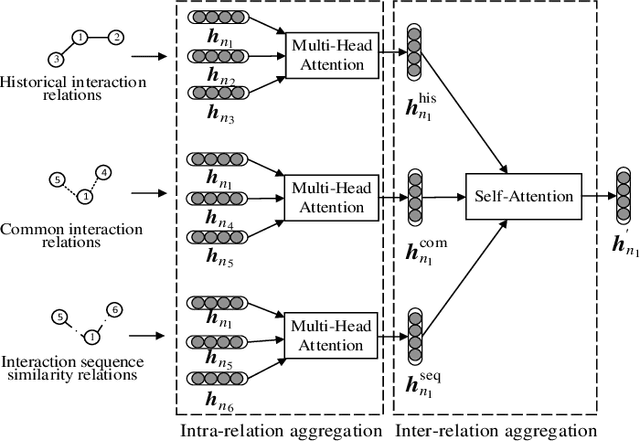
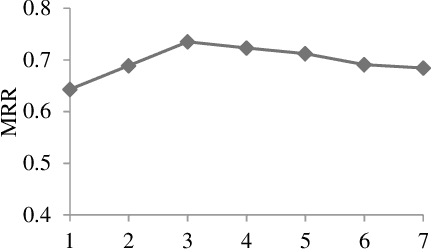
Temporal interaction networks are formed in many fields, e.g., e-commerce, online education, and social network service. Temporal interaction network embedding can effectively mine the information in temporal interaction networks, which is of great significance to the above fields. Usually, the occurrence of an interaction affects not only the nodes directly involved in the interaction (interacting nodes), but also the neighbor nodes of interacting nodes. However, existing temporal interaction network embedding methods only use historical interaction relations to mine neighbor nodes, ignoring other relation types. In this paper, we propose a multi-relation aware temporal interaction network embedding method (MRATE). Based on historical interactions, MRATE mines historical interaction relations, common interaction relations, and interaction sequence similarity relations to obtain the neighbor based embeddings of interacting nodes. The hierarchical multi-relation aware aggregation method in MRATE first employs graph attention networks (GATs) to aggregate the interaction impacts propagated through a same relation type and then combines the aggregated interaction impacts from multiple relation types through the self-attention mechanism. Experiments are conducted on three public temporal interaction network datasets, and the experimental results show the effectiveness of MRATE.