 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Disentanglement for Full-Reference Image Quality Assessment
Apr 23, 2026Existing deep network-based full-reference image quality assessment (FR-IQA) models typically work by performing pairwise comparisons of deep features from the reference and distorted images. In this paper, we approach this problem from a different perspective and propose a novel FR-IQA paradigm based on causal inference and decoupled representation learning. Unlike typical feature comparison-based FR-IQA models, our approach formulates degradation estimation as a causal disentanglement process guided by intervention on latent representations. We first decouple degradation and content representations by exploiting the content invariance between the reference and distorted images. Second, inspired by the human visual masking effect, we design a masking module to model the causal relationship between image content and degradation features, thereby extracting content-influenced degradation features from distorted images. Finally, quality scores are predicted from these degradation features using either supervised regression or label-free dimensionality reduction. Extensive experiments demonstrate that our method achieves highly competitive performance on standard IQA benchmarks across fully supervised, few-label, and label-free settings. Furthermore, we evaluate the approach on diverse non-standard natural image domains with scarce data, including underwater, radiographic, medical, neutron, and screen-content images. Benefiting from its ability to perform scenario-specific training and prediction without labeled IQA data, our method exhibits superior cross-domain generalization compared to existing training-free FR-IQA models.
Kernel Alignment-based Multi-view Unsupervised Feature Selection with Sample-level Adaptive Graph Learning
Jan 12, 2026Although multi-view unsupervised feature selection (MUFS) has demonstrated success in dimensionality reduction for unlabeled multi-view data, most existing methods reduce feature redundancy by focusing on linear correlations among features but often overlook complex nonlinear dependencies. This limits the effectiveness of feature selection. In addition, existing methods fuse similarity graphs from multiple views by employing sample-invariant weights to preserve local structure. However, this process fails to account for differences in local neighborhood clarity among samples within each view, thereby hindering accurate characterization of the intrinsic local structure of the data. In this paper, we propose a Kernel Alignment-based multi-view unsupervised FeatUre selection with Sample-level adaptive graph lEarning method (KAFUSE) to address these issues. Specifically, we first employ kernel alignment with an orthogonal constraint to reduce feature redundancy in both linear and nonlinear relationships. Then, a cross-view consistent similarity graph is learned by applying sample-level fusion to each slice of a tensor formed by stacking similarity graphs from different views, which automatically adjusts the view weights for each sample during fusion. These two steps are integrated into a unified model for feature selection, enabling mutual enhancement between them. Extensive experiments on real multi-view datasets demonstrate the superiority of KAFUSE over state-of-the-art methods.
Cross-view Joint Learning for Mixed-Missing Multi-view Unsupervised Feature Selection
Nov 15, 2025


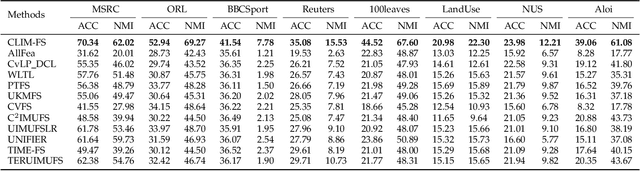
Incomplete multi-view unsupervised feature selection (IMUFS), which aims to identify representative features from unlabeled multi-view data containing missing values, has received growing attention in recent years. Despite their promising performance, existing methods face three key challenges: 1) by focusing solely on the view-missing problem, they are not well-suited to the more prevalent mixed-missing scenario in practice, where some samples lack entire views or only partial features within views; 2) insufficient utilization of consistency and diversity across views limits the effectiveness of feature selection; and 3) the lack of theoretical analysis makes it unclear how feature selection and data imputation interact during the joint learning process. Being aware of these, we propose CLIM-FS, a novel IMUFS method designed to address the mixed-missing problem. Specifically, we integrate the imputation of both missing views and variables into a feature selection model based on nonnegative orthogonal matrix factorization, enabling the joint learning of feature selection and adaptive data imputation. Furthermore, we fully leverage consensus cluster structure and cross-view local geometrical structure to enhance the synergistic learning process. We also provide a theoretical analysis to clarify the underlying collaborative mechanism of CLIM-FS. Experimental results on eight real-world multi-view datasets demonstrate that CLIM-FS outperforms state-of-the-art methods.
Attribute-formed Class-specific Concept Space: Endowing Language Bottleneck Model with Better Interpretability and Scalability
Mar 26, 2025



Language Bottleneck Models (LBMs) are proposed to achieve interpretable image recognition by classifying images based on textual concept bottlenecks. However, current LBMs simply list all concepts together as the bottleneck layer, leading to the spurious cue inference problem and cannot generalized to unseen classes. To address these limitations, we propose the Attribute-formed Language Bottleneck Model (ALBM). ALBM organizes concepts in the attribute-formed class-specific space, where concepts are descriptions of specific attributes for specific classes. In this way, ALBM can avoid the spurious cue inference problem by classifying solely based on the essential concepts of each class. In addition, the cross-class unified attribute set also ensures that the concept spaces of different classes have strong correlations, as a result, the learned concept classifier can be easily generalized to unseen classes. Moreover, to further improve interpretability, we propose Visual Attribute Prompt Learning (VAPL) to extract visual features on fine-grained attributes. Furthermore, to avoid labor-intensive concept annotation, we propose the Description, Summary, and Supplement (DSS) strategy to automatically generate high-quality concept sets with a complete and precise attribute. Extensive experiments on 9 widely used few-shot benchmarks demonstrate the interpretability, transferability, and performance of our approach. The code and collected concept sets are available at https://github.com/tiggers23/ALBM.
HLV-1K: A Large-scale Hour-Long Video Benchmark for Time-Specific Long Video Understanding
Jan 03, 2025



Multimodal large language models have become a popular topic in deep visual understanding due to many promising real-world applications. However, hour-long video understanding, spanning over one hour and containing tens of thousands of visual frames, remains under-explored because of 1) challenging long-term video analyses, 2) inefficient large-model approaches, and 3) lack of large-scale benchmark datasets. Among them, in this paper, we focus on building a large-scale hour-long long video benchmark, HLV-1K, designed to evaluate long video understanding models. HLV-1K comprises 1009 hour-long videos with 14,847 high-quality question answering (QA) and multi-choice question asnwering (MCQA) pairs with time-aware query and diverse annotations, covering frame-level, within-event-level, cross-event-level, and long-term reasoning tasks. We evaluate our benchmark using existing state-of-the-art methods and demonstrate its value for testing deep long video understanding capabilities at different levels and for various tasks. This includes promoting future long video understanding tasks at a granular level, such as deep understanding of long live videos, meeting recordings, and movies.
Enhancing Multi-Robot Semantic Navigation Through Multimodal Chain-of-Thought Score Collaboration
Dec 24, 2024



Understanding how humans cooperatively utilize semantic knowledge to explore unfamiliar environments and decide on navigation directions is critical for house service multi-robot systems. Previous methods primarily focused on single-robot centralized planning strategies, which severely limited exploration efficiency. Recent research has considered decentralized planning strategies for multiple robots, assigning separate planning models to each robot, but these approaches often overlook communication costs. In this work, we propose Multimodal Chain-of-Thought Co-Navigation (MCoCoNav), a modular approach that utilizes multimodal Chain-of-Thought to plan collaborative semantic navigation for multiple robots. MCoCoNav combines visual perception with Vision Language Models (VLMs) to evaluate exploration value through probabilistic scoring, thus reducing time costs and achieving stable outputs. Additionally, a global semantic map is used as a communication bridge, minimizing communication overhead while integrating observational results. Guided by scores that reflect exploration trends, robots utilize this map to assess whether to explore new frontier points or revisit history nodes. Experiments on HM3D_v0.2 and MP3D demonstrate the effectiveness of our approach. Our code is available at https://github.com/FrankZxShen/MCoCoNav.git.
Adaptive Paradigm Synergy: Can a Cross-Paradigm Objective Enhance Long-Tailed Learning?
Oct 30, 2024Self-supervised learning (SSL) has achieved impressive results across several computer vision tasks, even rivaling supervised methods. However, its performance degrades on real-world datasets with long-tailed distributions due to difficulties in capturing inherent class imbalances. Although supervised long-tailed learning offers significant insights, the absence of labels in SSL prevents direct transfer of these strategies.To bridge this gap, we introduce Adaptive Paradigm Synergy (APS), a cross-paradigm objective that seeks to unify the strengths of both paradigms. Our approach reexamines contrastive learning from a spatial structure perspective, dynamically adjusting the uniformity of latent space structure through adaptive temperature tuning. Furthermore, we draw on a re-weighting strategy from supervised learning to compensate for the shortcomings of temperature adjustment in explicit quantity perception.Extensive experiments on commonly used long-tailed datasets demonstrate that APS improves performance effectively and efficiently. Our findings reveal the potential for deeper integration between supervised and self-supervised learning, paving the way for robust models that handle real-world class imbalance.
From Seconds to Hours: Reviewing MultiModal Large Language Models on Comprehensive Long Video Understanding
Sep 27, 2024



The integration of Large Language Models (LLMs) with visual encoders has recently shown promising performance in visual understanding tasks, leveraging their inherent capability to comprehend and generate human-like text for visual reasoning. Given the diverse nature of visual data, MultiModal Large Language Models (MM-LLMs) exhibit variations in model designing and training for understanding images, short videos, and long videos. Our paper focuses on the substantial differences and unique challenges posed by long video understanding compared to static image and short video understanding. Unlike static images, short videos encompass sequential frames with both spatial and within-event temporal information, while long videos consist of multiple events with between-event and long-term temporal information. In this survey, we aim to trace and summarize the advancements of MM-LLMs from image understanding to long video understanding. We review the differences among various visual understanding tasks and highlight the challenges in long video understanding, including more fine-grained spatiotemporal details, dynamic events, and long-term dependencies. We then provide a detailed summary of the advancements in MM-LLMs in terms of model design and training methodologies for understanding long videos. Finally, we compare the performance of existing MM-LLMs on video understanding benchmarks of various lengths and discuss potential future directions for MM-LLMs in long video understanding.
Adaptive Collaborative Correlation Learning-based Semi-Supervised Multi-Label Feature Selection
Jun 18, 2024Semi-supervised multi-label feature selection has recently been developed to solve the curse of dimensionality problem in high-dimensional multi-label data with certain samples missing labels. Although many efforts have been made, most existing methods use a predefined graph approach to capture the sample similarity or the label correlation. In this manner, the presence of noise and outliers within the original feature space can undermine the reliability of the resulting sample similarity graph. It also fails to precisely depict the label correlation due to the existence of unknown labels. Besides, these methods only consider the discriminative power of selected features, while neglecting their redundancy. In this paper, we propose an Adaptive Collaborative Correlation lEarning-based Semi-Supervised Multi-label Feature Selection (Access-MFS) method to address these issues. Specifically, a generalized regression model equipped with an extended uncorrelated constraint is introduced to select discriminative yet irrelevant features and maintain consistency between predicted and ground-truth labels in labeled data, simultaneously. Then, the instance correlation and label correlation are integrated into the proposed regression model to adaptively learn both the sample similarity graph and the label similarity graph, which mutually enhance feature selection performance. Extensive experimental results demonstrate the superiority of the proposed Access-MFS over other state-of-the-art methods.
Colorectal Polyp Segmentation in the Deep Learning Era: A Comprehensive Survey
Jan 22, 2024Colorectal polyp segmentation (CPS), an essential problem in medical image analysis, has garnered growing research attention. Recently, the deep learning-based model completely overwhelmed traditional methods in the field of CPS, and more and more deep CPS methods have emerged, bringing the CPS into the deep learning era. To help the researchers quickly grasp the main techniques, datasets, evaluation metrics, challenges, and trending of deep CPS, this paper presents a systematic and comprehensive review of deep-learning-based CPS methods from 2014 to 2023, a total of 115 technical papers. In particular, we first provide a comprehensive review of the current deep CPS with a novel taxonomy, including network architectures, level of supervision, and learning paradigm. More specifically, network architectures include eight subcategories, the level of supervision comprises six subcategories, and the learning paradigm encompasses 12 subcategories, totaling 26 subcategories. Then, we provided a comprehensive analysis the characteristics of each dataset, including the number of datasets, annotation types, image resolution, polyp size, contrast values, and polyp location. Following that, we summarized CPS's commonly used evaluation metrics and conducted a detailed analysis of 40 deep SOTA models, including out-of-distribution generalization and attribute-based performance analysis. Finally, we discussed deep learning-based CPS methods' main challenges and opportunities.