 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchorMoE: Interpretable Time Series Classification via Anchor-Routed MoE
Jun 03, 2026Multivariate time series classification (MTSC) is pivotal in high-stakes domains, such as clinical diagnosis and industrial fault detection, where safe deployment necessitates transparent decision-making. However, isolating the temporal segments that drive model predictions is challenging because discriminative signals in real-world time series are typically sparse, heterogeneous, and heavily obscured by background noise. This paper, therefore, proposes AnchorMoE, an interpretable-by-construction classification framework. Built upon a Mixture-of-Experts (MoE) architecture, AnchorMoE encodes multi-view representations of local patches and routes them to specialized experts, ensuring that the final prediction is formulated as an exact additive decomposition over the input segments, facilitating ante-hoc transparency rather than relying on post-hoc estimations. To maintain the reliability of this decomposition under sparse signal distributions, we introduce a geometric orthogonality constraint that penalizes representational redundancy, compelling distinct experts to specialize in heterogeneous predictive patterns. Furthermore, an uncertainty-aware reliability gate is designed to dynamically calibrate the contribution of each segment, effectively suppressing residual background noise. Extensive experiments on real-world and synthetic benchmarks demonstrate that AnchorMoE achieves highly competitive classification performance while faithfully grounding its decisions in the raw time series.
CARE: Class-Adaptive Expert Consensus for Reliable Learning with Long-Tailed Noisy Labels
May 22, 2026Learning from real-world data is frequently hindered by the compound challenge of long-tailed class distributions and noisy annotations. Existing methods partially address these issues but typically ignore the non-uniform impact of label noise across classes, resulting in ineffective correction for tail classes and over-regularization for head classes. To address this issue, we propose Class-Adaptive Rectification with Experts (CARE), a parameter-efficient framework that leverages three complementary supervision sources from vision-language models (VLM): observed noisy labels, VLM text embeddings, and visual features. CARE introduces a class-adaptive expert consensus mechanism that enforces stricter agreement for tail classes and more permissive agreement for head classes based on class frequency. By aggregating high-confidence predictions across these sources, CARE filters unreliable signals and recalibrates class distributions, yielding more reliable rectification under long-tailed distributions. Extensive experiments on both synthetic and real-world benchmarks demonstrate that CARE consistently outperforms state-of-the-art methods, achieving up to 3.0\% performance gains. The source code is available at https://github.com/qwq123-study/CARE.
Learning from Imperfect Text Guidance: Robust Long-Tail Visual Recognition with High-Noise Label
Apr 25, 2026Real-world data often exhibit long-tailed distributions with numerous noisy labels, substantially degrading the performance of deep models. While prior research has made progress in addressing this combined challenge, it overlooks the severe label-image mismatch inherent to high-noise settings, thereby limiting their effectiveness. Given that observed labels, though mismatched with images, still retain category information, we propose employing auxiliary text information from labels to address label-image inconsistencies in long-tailed noisy data. Specifically, we leverage the intrinsic cross-modal alignment in pre-trained visual-language models to correct the label-image inconsistencies. This supervisory signal, referred to as Weak Teacher Supervision (WTS), is unaffected by label noise and data distribution biases, albeit exhibits limited accuracy. Therefore, the activation of WTS is determined by evaluating the discrepancy between text-predicted labels and observed labels. Extensive experiments demonstrate the superior performance of WTS across synthetic and real-world datasets, particularly under high-noise conditions. The source code is available at https://anonymous.4open.science/r/WTS-0F3C.
Learning Order Forest for Qualitative-Attribute Data Clustering
Mar 03, 2026Clustering is a fundamental approach to understanding data patterns, wherein the intuitive Euclidean distance space is commonly adopted. However, this is not the case for implicit cluster distributions reflected by qualitative attribute values, e.g., the nominal values of attributes like symptoms, marital status, etc. This paper, therefore, discovered a tree-like distance structure to flexibly represent the local order relationship among intra-attribute qualitative values. That is, treating a value as the vertex of the tree allows to capture rich order relationships among the vertex value and the others. To obtain the trees in a clustering-friendly form, a joint learning mechanism is proposed to iteratively obtain more appropriate tree structures and clusters. It turns out that the latent distance space of the whole dataset can be well-represented by a forest consisting of the learned trees. Extensive experiments demonstrate that the joint learning adapts the forest to the clustering task to yield accurate results. Comparisons of 10 counterparts on 12 real benchmark datasets with significance tests verify the superiority of the proposed method.
* Accepted to ECAI2024
One-Shot Hierarchical Federated Clustering
Jan 10, 2026Driven by the growth of Web-scale decentralized services, Federated Clustering (FC) aims to extract knowledge from heterogeneous clients in an unsupervised manner while preserving the clients' privacy, which has emerged as a significant challenge due to the lack of label guidance and the Non-Independent and Identically Distributed (non-IID) nature of clients. In real scenarios such as personalized recommendation and cross-device user profiling, the global cluster may be fragmented and distributed among different clients, and the clusters may exist at different granularities or even nested. Although Hierarchical Clustering (HC) is considered promising for exploring such distributions, the sophisticated recursive clustering process makes it more computationally expensive and vulnerable to privacy exposure, thus relatively unexplored under the federated learning scenario. This paper introduces an efficient one-shot hierarchical FC framework that performs client-end distribution exploration and server-end distribution aggregation through one-way prototype-level communication from clients to the server. A fine partition mechanism is developed to generate successive clusterlets to describe the complex landscape of the clients' clusters. Then, a multi-granular learning mechanism on the server is proposed to fuse the clusterlets, even when they have inconsistent granularities generated from different clients. It turns out that the complex cluster distributions across clients can be efficiently explored, and extensive experiments comparing state-of-the-art methods on ten public datasets demonstrate the superiority of the proposed method.
Break the Tie: Learning Cluster-Customized Category Relationships for Categorical Data Clustering
Nov 12, 2025



Categorical attributes with qualitative values are ubiquitous in cluster analysis of real datasets. Unlike the Euclidean distance of numerical attributes, the categorical attributes lack well-defined relationships of their possible values (also called categories interchangeably), which hampers the exploration of compact categorical data clusters. Although most attempts are made for developing appropriate distance metrics, they typically assume a fixed topological relationship between categories when learning distance metrics, which limits their adaptability to varying cluster structures and often leads to suboptimal clustering performance. This paper, therefore, breaks the intrinsic relationship tie of attribute categories and learns customized distance metrics suitable for flexibly and accurately revealing various cluster distributions. As a result, the fitting ability of the clustering algorithm is significantly enhanced, benefiting from the learnable category relationships. Moreover, the learned category relationships are proved to be Euclidean distance metric-compatible, enabling a seamless extension to mixed datasets that include both numerical and categorical attributes. Comparative experiments on 12 real benchmark datasets with significance tests show the superior clustering accuracy of the proposed method with an average ranking of 1.25, which is significantly higher than the 5.21 ranking of the current best-performing method.
FATE: A Prompt-Tuning-Based Semi-Supervised Learning Framework for Extremely Limited Labeled Data
Apr 14, 2025Semi-supervised learning (SSL) has achieved significant progress by leveraging both labeled data and unlabeled data. Existing SSL methods overlook a common real-world scenario when labeled data is extremely scarce, potentially as limited as a single labeled sample in the dataset. General SSL approaches struggle to train effectively from scratch under such constraints, while methods utilizing pre-trained models often fail to find an optimal balance between leveraging limited labeled data and abundant unlabeled data. To address this challenge, we propose Firstly Adapt, Then catEgorize (FATE), a novel SSL framework tailored for scenarios with extremely limited labeled data. At its core, the two-stage prompt tuning paradigm FATE exploits unlabeled data to compensate for scarce supervision signals, then transfers to downstream tasks. Concretely, FATE first adapts a pre-trained model to the feature distribution of downstream data using volumes of unlabeled samples in an unsupervised manner. It then applies an SSL method specifically designed for pre-trained models to complete the final classification task. FATE is designed to be compatible with both vision and vision-language pre-trained models. Extensive experiments demonstrate that FATE effectively mitigates challenges arising from the scarcity of labeled samples in SSL, achieving an average performance improvement of 33.74% across seven benchmarks compared to state-of-the-art SSL methods. Code is available at https://anonymous.4open.science/r/Semi-supervised-learning-BA72.
Classifying Long-tailed and Label-noise Data via Disentangling and Unlearning
Mar 14, 2025



In real-world datasets, the challenges of long-tailed distributions and noisy labels often coexist, posing obstacles to the model training and performance. Existing studies on long-tailed noisy label learning (LTNLL) typically assume that the generation of noisy labels is independent of the long-tailed distribution, which may not be true from a practical perspective. In real-world situaiton, we observe that the tail class samples are more likely to be mislabeled as head, exacerbating the original degree of imbalance. We call this phenomenon as ``tail-to-head (T2H)'' noise. T2H noise severely degrades model performance by polluting the head classes and forcing the model to learn the tail samples as head. To address this challenge, we investigate the dynamic misleading process of the nosiy labels and propose a novel method called Disentangling and Unlearning for Long-tailed and Label-noisy data (DULL). It first employs the Inner-Feature Disentangling (IFD) to disentangle feature internally. Based on this, the Inner-Feature Partial Unlearning (IFPU) is then applied to weaken and unlearn incorrect feature regions correlated to wrong classes. This method prevents the model from being misled by noisy labels, enhancing the model's robustness against noise. To provide a controlled experimental environment, we further propose a new noise addition algorithm to simulate T2H noise. Extensive experiments on both simulated and real-world datasets demonstrate the effectiveness of our proposed method.
Iterative Prompt Relocation for Distribution-Adaptive Visual Prompt Tuning
Mar 10, 2025
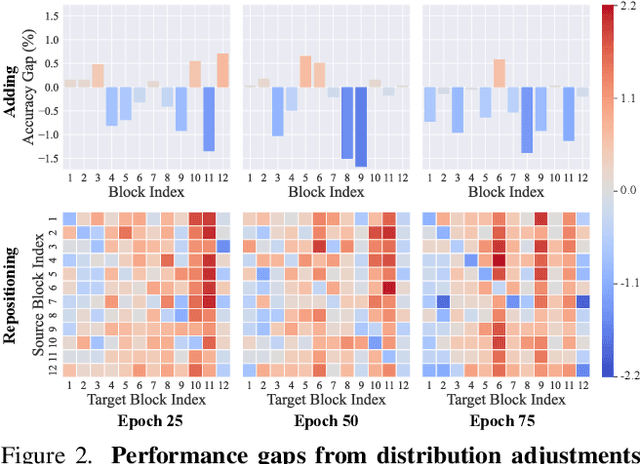
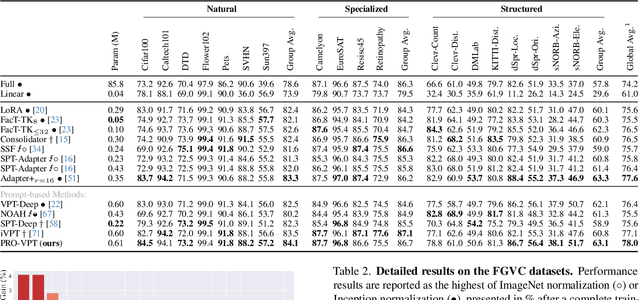

Visual prompt tuning (VPT) provides an efficient and effective solution for adapting pre-trained models to various downstream tasks by incorporating learnable prompts. However, most prior art indiscriminately applies a fixed prompt distribution across different tasks, neglecting the importance of each block differing depending on the task. In this paper, we investigate adaptive distribution optimization (ADO) by addressing two key questions: (1) How to appropriately and formally define ADO, and (2) How to design an adaptive distribution strategy guided by this definition? Through in-depth analysis, we provide an affirmative answer that properly adjusting the distribution significantly improves VPT performance, and further uncover a key insight that a nested relationship exists between ADO and VPT. Based on these findings, we propose a new VPT framework, termed PRO-VPT (iterative Prompt RelOcation-based VPT), which adaptively adjusts the distribution building upon a nested optimization formulation. Specifically, we develop a prompt relocation strategy for ADO derived from this formulation, comprising two optimization steps: identifying and pruning idle prompts, followed by determining the optimal blocks for their relocation. By iteratively performing prompt relocation and VPT, our proposal adaptively learns the optimal prompt distribution, thereby unlocking the full potential of VPT. Extensive experiments demonstrate that our proposal significantly outperforms state-of-the-art VPT methods, e.g., PRO-VPT surpasses VPT by 1.6% average accuracy, leading prompt-based methods to state-of-the-art performance on the VTAB-1k benchmark. The code is available at https://github.com/ckshang/PRO-VPT.
Asynchronous Federated Clustering with Unknown Number of Clusters
Dec 29, 2024



Federated Clustering (FC) is crucial to mining knowledge from unlabeled non-Independent Identically Distributed (non-IID) data provided by multiple clients while preserving their privacy. Most existing attempts learn cluster distributions at local clients, and then securely pass the desensitized information to the server for aggregation. However, some tricky but common FC problems are still relatively unexplored, including the heterogeneity in terms of clients' communication capacity and the unknown number of proper clusters $k^*$. To further bridge the gap between FC and real application scenarios, this paper first shows that the clients' communication asynchrony and unknown $k^*$ are complex coupling problems, and then proposes an Asynchronous Federated Cluster Learning (AFCL) method accordingly. It spreads the excessive number of seed points to the clients as a learning medium and coordinates them across the clients to form a consensus. To alleviate the distribution imbalance cumulated due to the unforeseen asynchronous uploading from the heterogeneous clients, we also design a balancing mechanism for seeds updating. As a result, the seeds gradually adapt to each other to reveal a proper number of clusters. Extensive experiments demonstrate the efficacy of AFCL.