 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBSN++: Complementary Boundary Regressor with Scale-Balanced Relation Modeling for Temporal Action Proposal Generation
Sep 15, 2020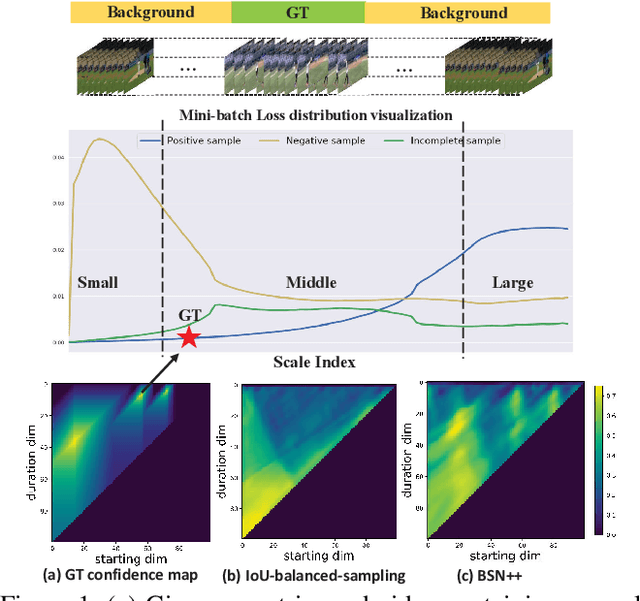

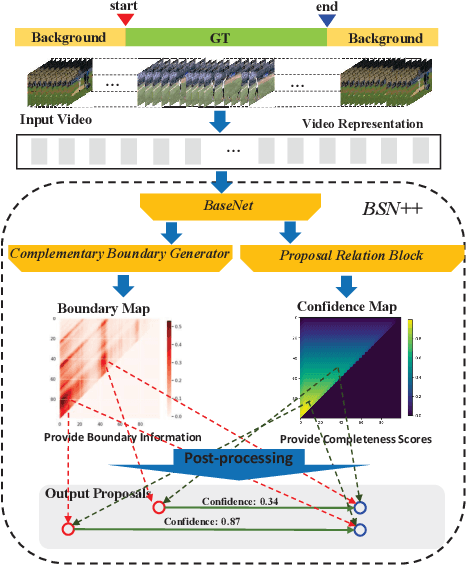
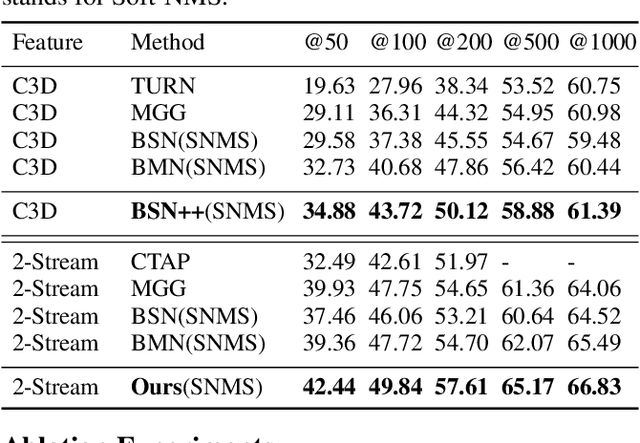
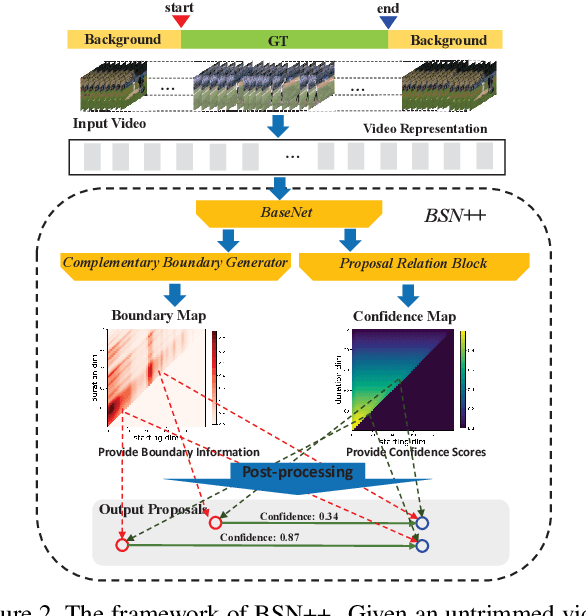
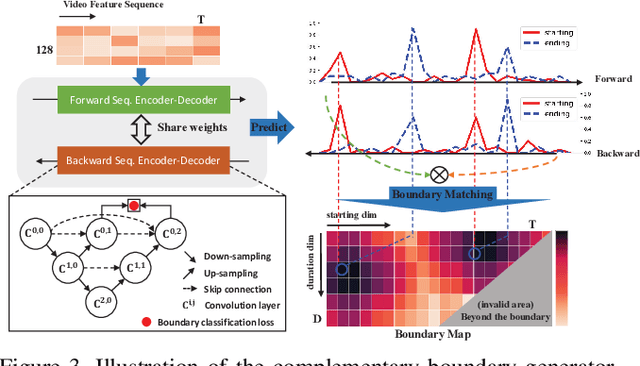
Generating human action proposals in untrimmed videos is an important yet challenging task with wide applications. Current methods often suffer from the noisy boundary locations and the inferior quality of confidence scores used for proposal retrieving. In this paper, we present BSN++, a new framework which exploits complementary boundary regressor and relation modeling for temporal proposal generation. First, we propose a novel boundary regressor based on the complementary characteristics of both starting and ending boundary classifiers. Specifically, we utilize the U-shaped architecture with nested skip connections to capture rich contexts and introduce bi-directional boundary matching mechanism to improve boundary precision. Second, to account for the proposal-proposal relations ignored in previous methods, we devise a proposal relation block to which includes two self-attention modules from the aspects of position and channel. Furthermore, we find that there inevitably exists data imbalanced problems in the positive/negative proposals and temporal durations, which harm the model performance on tail distributions. To relieve this issue, we introduce the scale-balanced re-sampling strategy. Extensive experiments are conducted on two popular benchmarks: ActivityNet-1.3 and THUMOS14, which demonstrate that BSN++ achieves the state-of-the-art performance.
Complementary Boundary Generator with Scale-Invariant Relation Modeling for Temporal Action Localization: Submission to ActivityNet Challenge 2020
Aug 26, 2020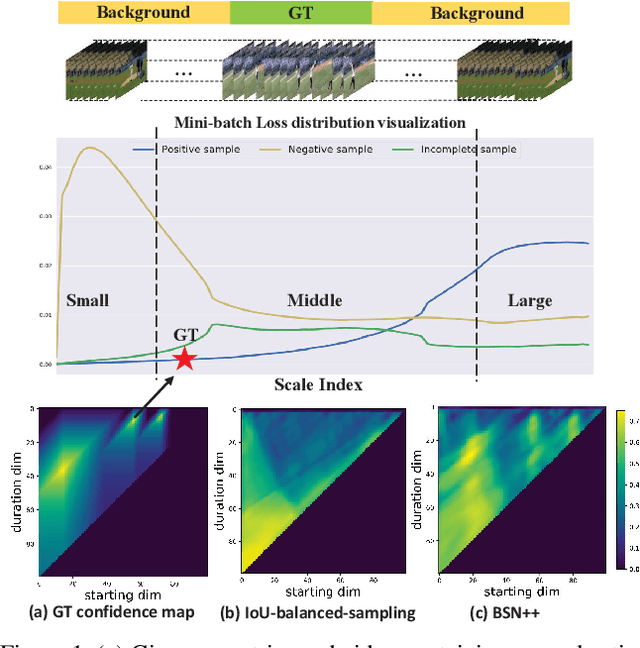
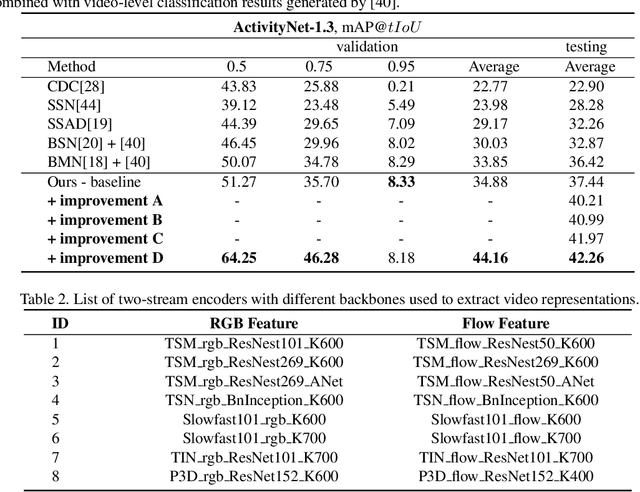
This technical report presents an overview of our solution used in the submission to ActivityNet Challenge 2020 Task 1 (\textbf{temporal action localization/detection}). Temporal action localization requires to not only precisely locate the temporal boundaries of action instances, but also accurately classify the untrimmed videos into specific categories. In this paper, we decouple the temporal action localization task into two stages (i.e. proposal generation and classification) and enrich the proposal diversity through exhaustively exploring the influences of multiple components from different but complementary perspectives. Specifically, in order to generate high-quality proposals, we consider several factors including the video feature encoder, the proposal generator, the proposal-proposal relations, the scale imbalance, and ensemble strategy. Finally, in order to obtain accurate detections, we need to further train an optimal video classifier to recognize the generated proposals. Our proposed scheme achieves the state-of-the-art performance on the temporal action localization task with \textbf{42.26} average mAP on the challenge testing set.
Learning Connectivity of Neural Networks from a Topological Perspective
Aug 19, 2020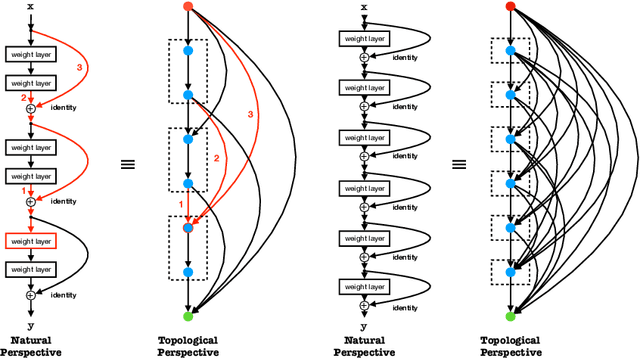
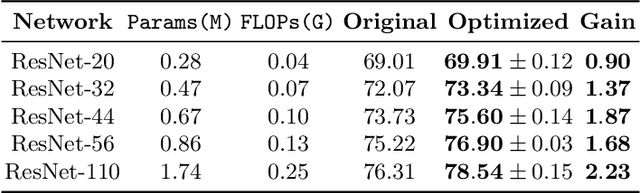
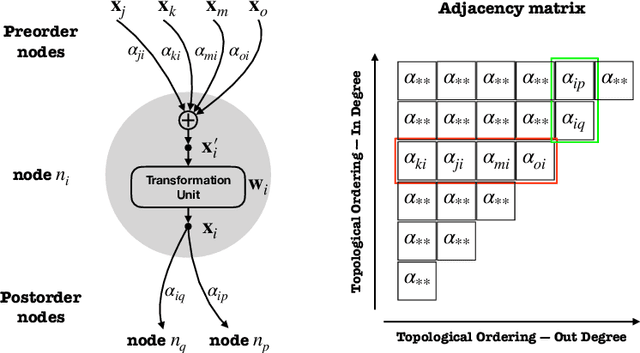
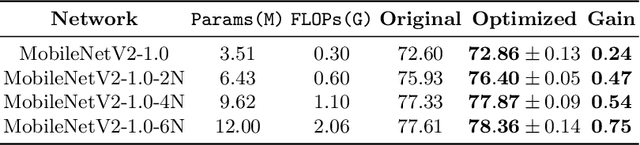
Seeking effective neural networks is a critical and practical field in deep learning. Besides designing the depth, type of convolution, normalization, and nonlinearities, the topological connectivity of neural networks is also important. Previous principles of rule-based modular design simplify the difficulty of building an effective architecture, but constrain the possible topologies in limited spaces. In this paper, we attempt to optimize the connectivity in neural networks. We propose a topological perspective to represent a network into a complete graph for analysis, where nodes carry out aggregation and transformation of features, and edges determine the flow of information. By assigning learnable parameters to the edges which reflect the magnitude of connections, the learning process can be performed in a differentiable manner. We further attach auxiliary sparsity constraint to the distribution of connectedness, which promotes the learned topology focus on critical connections. This learning process is compatible with existing networks and owns adaptability to larger search spaces and different tasks. Quantitative results of experiments reflect the learned connectivity is superior to traditional rule-based ones, such as random, residual, and complete. In addition, it obtains significant improvements in image classification and object detection without introducing excessive computation burden.
CelebA-Spoof: Large-Scale Face Anti-Spoofing Dataset with Rich Annotations
Aug 01, 2020
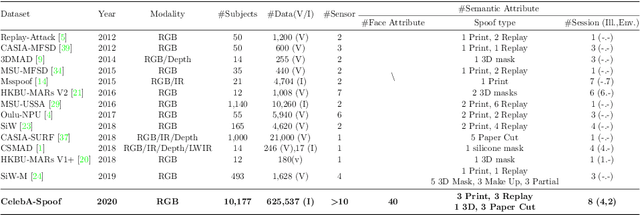
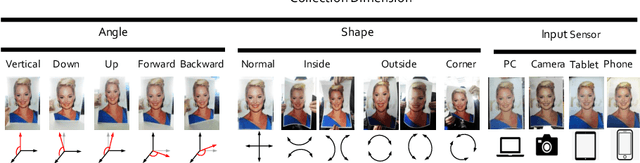

As facial interaction systems are prevalently deployed, security and reliability of these systems become a critical issue, with substantial research efforts devoted. Among them, face anti-spoofing emerges as an important area, whose objective is to identify whether a presented face is live or spoof. Though promising progress has been achieved, existing works still have difficulty in handling complex spoof attacks and generalizing to real-world scenarios. The main reason is that current face anti-spoofing datasets are limited in both quantity and diversity. To overcome these obstacles, we contribute a large-scale face anti-spoofing dataset, CelebA-Spoof, with the following appealing properties: 1) Quantity: CelebA-Spoof comprises of 625,537 pictures of 10,177 subjects, significantly larger than the existing datasets. 2) Diversity: The spoof images are captured from 8 scenes (2 environments * 4 illumination conditions) with more than 10 sensors. 3) Annotation Richness: CelebA-Spoof contains 10 spoof type annotations, as well as the 40 attribute annotations inherited from the original CelebA dataset. Equipped with CelebA-Spoof, we carefully benchmark existing methods in a unified multi-task framework, Auxiliary Information Embedding Network (AENet), and reveal several valuable observations.
Class-wise Dynamic Graph Convolution for Semantic Segmentation
Jul 19, 2020
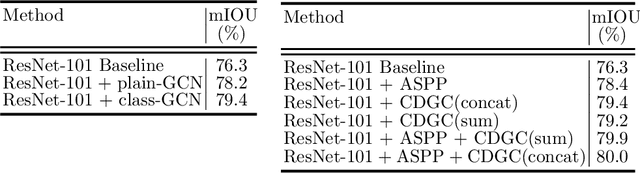
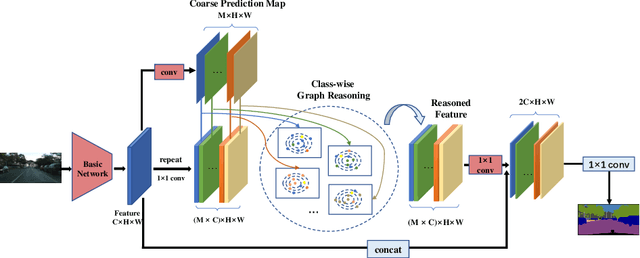
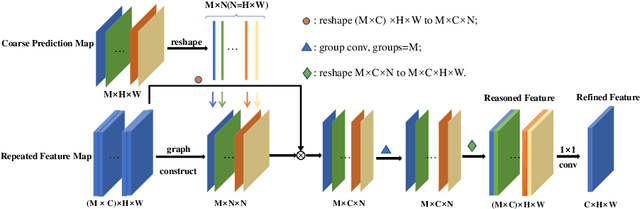
Recent works have made great progress in semantic segmentation by exploiting contextual information in a local or global manner with dilated convolutions, pyramid pooling or self-attention mechanism. In order to avoid potential misleading contextual information aggregation in previous works, we propose a class-wise dynamic graph convolution (CDGC) module to adaptively propagate information. The graph reasoning is performed among pixels in the same class. Based on the proposed CDGC module, we further introduce the Class-wise Dynamic Graph Convolution Network(CDGCNet), which consists of two main parts including the CDGC module and a basic segmentation network, forming a coarse-to-fine paradigm. Specifically, the CDGC module takes the coarse segmentation result as class mask to extract node features for graph construction and performs dynamic graph convolutions on the constructed graph to learn the feature aggregation and weight allocation. Then the refined feature and the original feature are fused to get the final prediction. We conduct extensive experiments on three popular semantic segmentation benchmarks including Cityscapes, PASCAL VOC 2012 and COCO Stuff, and achieve state-of-the-art performance on all three benchmarks.
Powering One-shot Topological NAS with Stabilized Share-parameter Proxy
May 21, 2020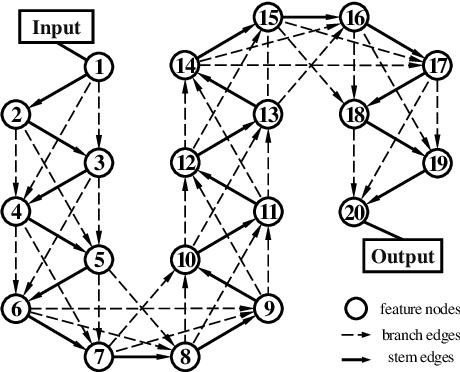

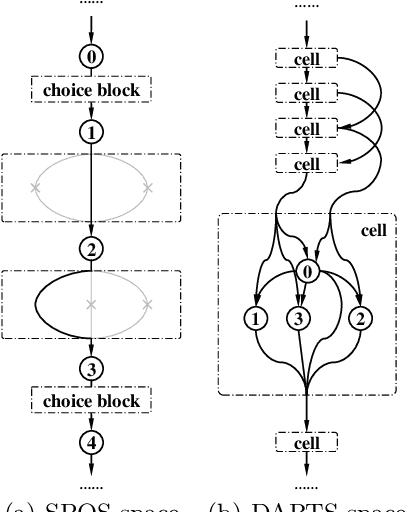
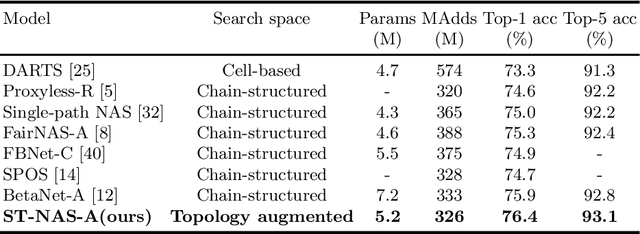
One-shot NAS method has attracted much interest from the research community due to its remarkable training efficiency and capacity to discover high performance models. However, the search spaces of previous one-shot based works usually relied on hand-craft design and were short for flexibility on the network topology. In this work, we try to enhance the one-shot NAS by exploring high-performing network architectures in our large-scale Topology Augmented Search Space (i.e., over 3.4*10^10 different topological structures). Specifically, the difficulties for architecture searching in such a complex space has been eliminated by the proposed stabilized share-parameter proxy, which employs Stochastic Gradient Langevin Dynamics to enable fast shared parameter sampling, so as to achieve stabilized measurement of architecture performance even in search space with complex topological structures. The proposed method, namely Stablized Topological Neural Architecture Search (ST-NAS), achieves state-of-the-art performance under Multiply-Adds (MAdds) constraint on ImageNet. Our lite model ST-NAS-A achieves 76.4% top-1 accuracy with only 326M MAdds. Our moderate model ST-NAS-B achieves 77.9% top-1 accuracy just required 503M MAdds. Both of our models offer superior performances in comparison to other concurrent works on one-shot NAS.
Large-Scale Object Detection in the Wild from Imbalanced Multi-Labels
May 18, 2020
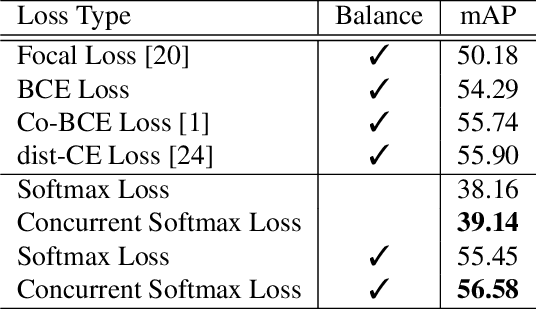


Training with more data has always been the most stable and effective way of improving performance in deep learning era. As the largest object detection dataset so far, Open Images brings great opportunities and challenges for object detection in general and sophisticated scenarios. However, owing to its semi-automatic collecting and labeling pipeline to deal with the huge data scale, Open Images dataset suffers from label-related problems that objects may explicitly or implicitly have multiple labels and the label distribution is extremely imbalanced. In this work, we quantitatively analyze these label problems and provide a simple but effective solution. We design a concurrent softmax to handle the multi-label problems in object detection and propose a soft-sampling methods with hybrid training scheduler to deal with the label imbalance. Overall, our method yields a dramatic improvement of 3.34 points, leading to the best single model with 60.90 mAP on the public object detection test set of Open Images. And our ensembling result achieves 67.17 mAP, which is 4.29 points higher than the best result of Open Images public test 2018.
COCAS: A Large-Scale Clothes Changing Person Dataset for Re-identification
May 16, 2020

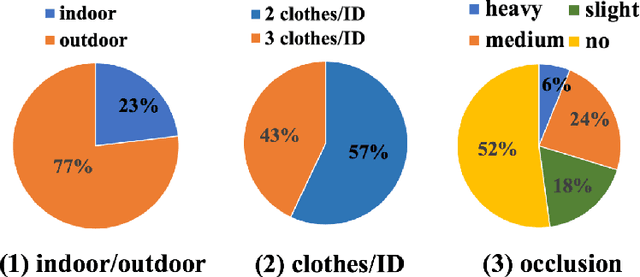
Recent years have witnessed great progress in person re-identification (re-id). Several academic benchmarks such as Market1501, CUHK03 and DukeMTMC play important roles to promote the re-id research. To our best knowledge, all the existing benchmarks assume the same person will have the same clothes. While in real-world scenarios, it is very often for a person to change clothes. To address the clothes changing person re-id problem, we construct a novel large-scale re-id benchmark named ClOthes ChAnging Person Set (COCAS), which provides multiple images of the same identity with different clothes. COCAS totally contains 62,382 body images from 5,266 persons. Based on COCAS, we introduce a new person re-id setting for clothes changing problem, where the query includes both a clothes template and a person image taking another clothes. Moreover, we propose a two-branch network named Biometric-Clothes Network (BC-Net) which can effectively integrate biometric and clothes feature for re-id under our setting. Experiments show that it is feasible for clothes changing re-id with clothes templates.
DMCP: Differentiable Markov Channel Pruning for Neural Networks
May 08, 2020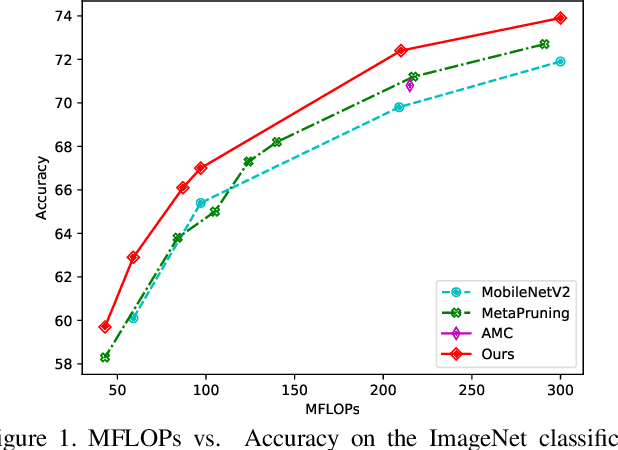
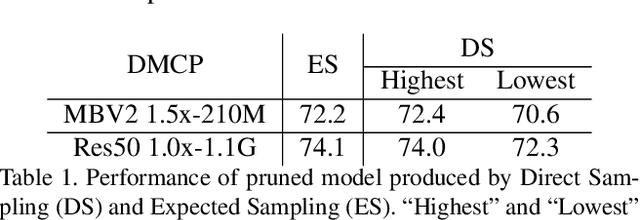
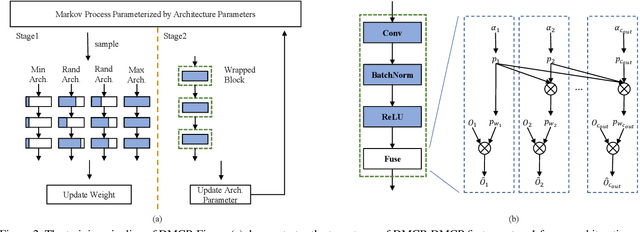
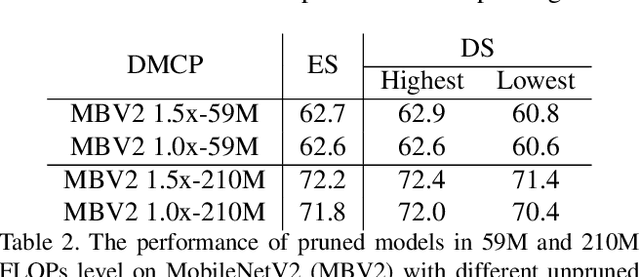
Recent works imply that the channel pruning can be regarded as searching optimal sub-structure from unpruned networks. However, existing works based on this observation require training and evaluating a large number of structures, which limits their application. In this paper, we propose a novel differentiable method for channel pruning, named Differentiable Markov Channel Pruning (DMCP), to efficiently search the optimal sub-structure. Our method is differentiable and can be directly optimized by gradient descent with respect to standard task loss and budget regularization (e.g. FLOPs constraint). In DMCP, we model the channel pruning as a Markov process, in which each state represents for retaining the corresponding channel during pruning, and transitions between states denote the pruning process. In the end, our method is able to implicitly select the proper number of channels in each layer by the Markov process with optimized transitions. To validate the effectiveness of our method, we perform extensive experiments on Imagenet with ResNet and MobilenetV2. Results show our method can achieve consistent improvement than state-of-the-art pruning methods in various FLOPs settings. The code is available at https://github.com/zx55/dmcp
Equalization Loss for Long-Tailed Object Recognition
Apr 14, 2020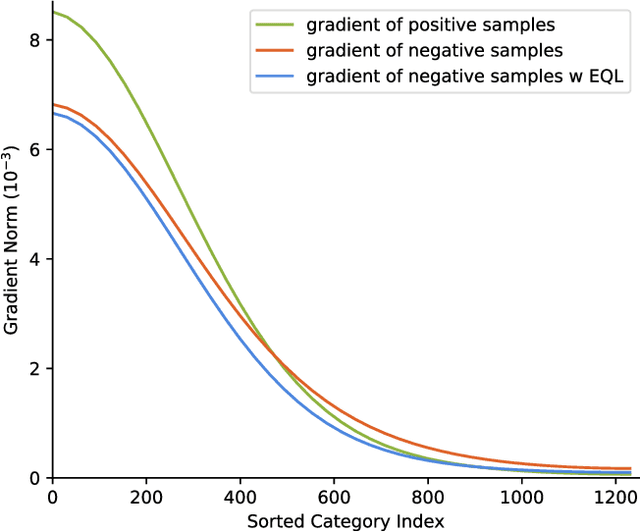
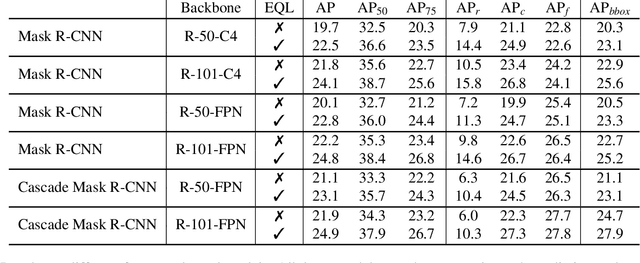
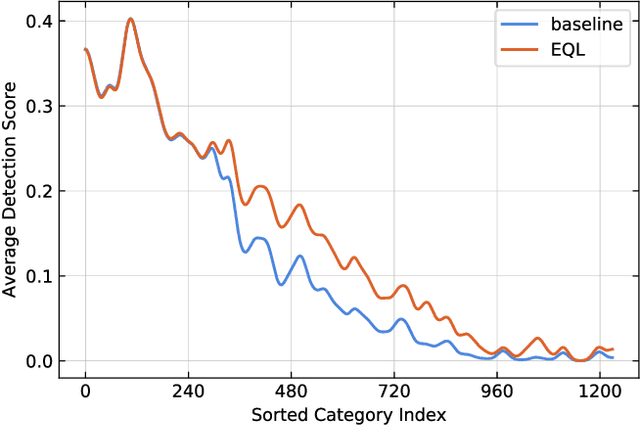
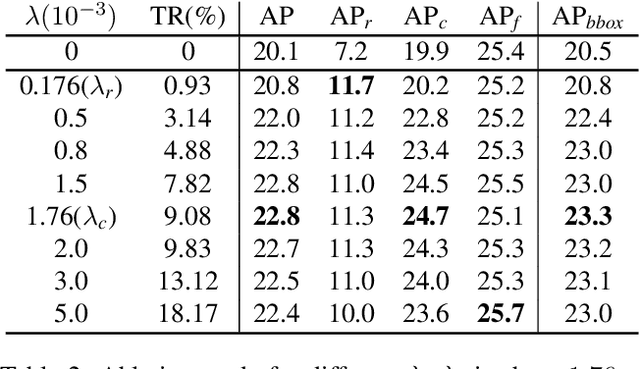
Object recognition techniques using convolutional neural networks (CNN) have achieved great success. However, state-of-the-art object detection methods still perform poorly on large vocabulary and long-tailed datasets, e.g. LVIS. In this work, we analyze this problem from a novel perspective: each positive sample of one category can be seen as a negative sample for other categories, making the tail categories receive more discouraging gradients. Based on it, we propose a simple but effective loss, named equalization loss, to tackle the problem of long-tailed rare categories by simply ignoring those gradients for rare categories. The equalization loss protects the learning of rare categories from being at a disadvantage during the network parameter updating. Thus the model is capable of learning better discriminative features for objects of rare classes. Without any bells and whistles, our method achieves AP gains of 4.1% and 4.8% for the rare and common categories on the challenging LVIS benchmark, compared to the Mask R-CNN baseline. With the utilization of the effective equalization loss, we finally won the 1st place in the LVIS Challenge 2019. Code has been made available at: https: //github.com/tztztztztz/eql.detectron2