 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Safety Generalization Challenges of Large Language Models via Code
Mar 14, 2024The rapid advancement of Large Language Models (LLMs) has brought about remarkable capabilities in natural language processing but also raised concerns about their potential misuse. While strategies like supervised fine-tuning and reinforcement learning from human feedback have enhanced their safety, these methods primarily focus on natural languages, which may not generalize to other domains. This paper introduces CodeAttack, a framework that transforms natural language inputs into code inputs, presenting a novel environment for testing the safety generalization of LLMs. Our comprehensive studies on state-of-the-art LLMs including GPT-4, Claude-2, and Llama-2 series reveal a common safety vulnerability of these models against code input: CodeAttack consistently bypasses the safety guardrails of all models more than 80% of the time. Furthermore, we find that a larger distribution gap between CodeAttack and natural language leads to weaker safety generalization, such as encoding natural language input with data structures or using less popular programming languages. These findings highlight new safety risks in the code domain and the need for more robust safety alignment algorithms to match the code capabilities of LLMs.
ActiveAD: Planning-Oriented Active Learning for End-to-End Autonomous Driving
Mar 05, 2024End-to-end differentiable learning for autonomous driving (AD) has recently become a prominent paradigm. One main bottleneck lies in its voracious appetite for high-quality labeled data e.g. 3D bounding boxes and semantic segmentation, which are notoriously expensive to manually annotate. The difficulty is further pronounced due to the prominent fact that the behaviors within samples in AD often suffer from long tailed distribution. In other words, a large part of collected data can be trivial (e.g. simply driving forward in a straight road) and only a few cases are safety-critical. In this paper, we explore a practically important yet under-explored problem about how to achieve sample and label efficiency for end-to-end AD. Specifically, we design a planning-oriented active learning method which progressively annotates part of collected raw data according to the proposed diversity and usefulness criteria for planning routes. Empirically, we show that our planning-oriented approach could outperform general active learning methods by a large margin. Notably, our method achieves comparable performance with state-of-the-art end-to-end AD methods - by using only 30% nuScenes data. We hope our work could inspire future works to explore end-to-end AD from a data-centric perspective in addition to methodology efforts.
Rethinking Classifier Re-Training in Long-Tailed Recognition: A Simple Logits Retargeting Approach
Mar 01, 2024



In the long-tailed recognition field, the Decoupled Training paradigm has demonstrated remarkable capabilities among various methods. This paradigm decouples the training process into separate representation learning and classifier re-training. Previous works have attempted to improve both stages simultaneously, making it difficult to isolate the effect of classifier re-training. Furthermore, recent empirical studies have demonstrated that simple regularization can yield strong feature representations, emphasizing the need to reassess existing classifier re-training methods. In this study, we revisit classifier re-training methods based on a unified feature representation and re-evaluate their performances. We propose a new metric called Logits Magnitude as a superior measure of model performance, replacing the commonly used Weight Norm. However, since it is hard to directly optimize the new metric during training, we introduce a suitable approximate invariant called Regularized Standard Deviation. Based on the two newly proposed metrics, we prove that reducing the absolute value of Logits Magnitude when it is nearly balanced can effectively decrease errors and disturbances during training, leading to better model performance. Motivated by these findings, we develop a simple logits retargeting approach (LORT) without the requirement of prior knowledge of the number of samples per class. LORT divides the original one-hot label into small true label probabilities and large negative label probabilities distributed across each class. Our method achieves state-of-the-art performance on various imbalanced datasets, including CIFAR100-LT, ImageNet-LT, and iNaturalist2018.
Theoretically Achieving Continuous Representation of Oriented Bounding Boxes
Feb 29, 2024Considerable efforts have been devoted to Oriented Object Detection (OOD). However, one lasting issue regarding the discontinuity in Oriented Bounding Box (OBB) representation remains unresolved, which is an inherent bottleneck for extant OOD methods. This paper endeavors to completely solve this issue in a theoretically guaranteed manner and puts an end to the ad-hoc efforts in this direction. Prior studies typically can only address one of the two cases of discontinuity: rotation and aspect ratio, and often inadvertently introduce decoding discontinuity, e.g. Decoding Incompleteness (DI) and Decoding Ambiguity (DA) as discussed in literature. Specifically, we propose a novel representation method called Continuous OBB (COBB), which can be readily integrated into existing detectors e.g. Faster-RCNN as a plugin. It can theoretically ensure continuity in bounding box regression which to our best knowledge, has not been achieved in literature for rectangle-based object representation. For fairness and transparency of experiments, we have developed a modularized benchmark based on the open-source deep learning framework Jittor's detection toolbox JDet for OOD evaluation. On the popular DOTA dataset, by integrating Faster-RCNN as the same baseline model, our new method outperforms the peer method Gliding Vertex by 1.13% mAP50 (relative improvement 1.54%), and 2.46% mAP75 (relative improvement 5.91%), without any tricks.
Fast and Interpretable 2D Homography Decomposition: Similarity-Kernel-Similarity and Affine-Core-Affine Transformations
Feb 28, 2024



In this paper, we present two fast and interpretable decomposition methods for 2D homography, which are named Similarity-Kernel-Similarity (SKS) and Affine-Core-Affine (ACA) transformations respectively. Under the minimal $4$-point configuration, the first and the last similarity transformations in SKS are computed by two anchor points on target and source planes, respectively. Then, the other two point correspondences can be exploited to compute the middle kernel transformation with only four parameters. Furthermore, ACA uses three anchor points to compute the first and the last affine transformations, followed by computation of the middle core transformation utilizing the other one point correspondence. ACA can compute a homography up to a scale with only $85$ floating-point operations (FLOPs), without even any division operations. Therefore, as a plug-in module, ACA facilitates the traditional feature-based Random Sample Consensus (RANSAC) pipeline, as well as deep homography pipelines estimating $4$-point offsets. In addition to the advantages of geometric parameterization and computational efficiency, SKS and ACA can express each element of homography by a polynomial of input coordinates ($7$th degree to $9$th degree), extend the existing essential Similarity-Affine-Projective (SAP) decomposition and calculate 2D affine transformations in a unified way. Source codes are released in https://github.com/cscvlab/SKS-Homography.
PreRoutGNN for Timing Prediction with Order Preserving Partition: Global Circuit Pre-training, Local Delay Learning and Attentional Cell Modeling
Feb 27, 2024



Pre-routing timing prediction has been recently studied for evaluating the quality of a candidate cell placement in chip design. It involves directly estimating the timing metrics for both pin-level (slack, slew) and edge-level (net delay, cell delay), without time-consuming routing. However, it often suffers from signal decay and error accumulation due to the long timing paths in large-scale industrial circuits. To address these challenges, we propose a two-stage approach. First, we propose global circuit training to pre-train a graph auto-encoder that learns the global graph embedding from circuit netlist. Second, we use a novel node updating scheme for message passing on GCN, following the topological sorting sequence of the learned graph embedding and circuit graph. This scheme residually models the local time delay between two adjacent pins in the updating sequence, and extracts the lookup table information inside each cell via a new attention mechanism. To handle large-scale circuits efficiently, we introduce an order preserving partition scheme that reduces memory consumption while maintaining the topological dependencies. Experiments on 21 real world circuits achieve a new SOTA R2 of 0.93 for slack prediction, which is significantly surpasses 0.59 by previous SOTA method. Code will be available at: https://github.com/Thinklab-SJTU/EDA-AI.
Think2Drive: Efficient Reinforcement Learning by Thinking in Latent World Model for Quasi-Realistic Autonomous Driving (in CARLA-v2)
Feb 26, 2024Real-world autonomous driving (AD) especially urban driving involves many corner cases. The lately released AD simulator CARLA v2 adds 39 common events in the driving scene, and provide more quasi-realistic testbed compared to CARLA v1. It poses new challenge to the community and so far no literature has reported any success on the new scenarios in V2 as existing works mostly have to rely on specific rules for planning yet they cannot cover the more complex cases in CARLA v2. In this work, we take the initiative of directly training a planner and the hope is to handle the corner cases flexibly and effectively, which we believe is also the future of AD. To our best knowledge, we develop the first model-based RL method named Think2Drive for AD, with a world model to learn the transitions of the environment, and then it acts as a neural simulator to train the planner. This paradigm significantly boosts the training efficiency due to the low dimensional state space and parallel computing of tensors in the world model. As a result, Think2Drive is able to run in an expert-level proficiency in CARLA v2 within 3 days of training on a single A6000 GPU, and to our best knowledge, so far there is no reported success (100\% route completion)on CARLA v2. We also propose CornerCase-Repository, a benchmark that supports the evaluation of driving models by scenarios. Additionally, we propose a new and balanced metric to evaluate the performance by route completion, infraction number, and scenario density, so that the driving score could give more information about the actual driving performance.
Not All Experts are Equal: Efficient Expert Pruning and Skipping for Mixture-of-Experts Large Language Models
Feb 22, 2024



A pivotal advancement in the progress of large language models (LLMs) is the emergence of the Mixture-of-Experts (MoE) LLMs. Compared to traditional LLMs, MoE LLMs can achieve higher performance with fewer parameters, but it is still hard to deploy them due to their immense parameter sizes. Different from previous weight pruning methods that rely on specifically designed hardware, this paper mainly aims to enhance the deployment efficiency of MoE LLMs by introducing plug-and-play expert-level sparsification techniques. Specifically, we propose, for the first time to our best knowledge, post-training approaches for task-agnostic and task-specific expert pruning and skipping of MoE LLMs, tailored to improve deployment efficiency while maintaining model performance across a wide range of tasks. Extensive experiments show that our proposed methods can simultaneously reduce model sizes and increase the inference speed, while maintaining satisfactory performance. Data and code will be available at https://github.com/Lucky-Lance/Expert_Sparsity.
ChartX & ChartVLM: A Versatile Benchmark and Foundation Model for Complicated Chart Reasoning
Feb 19, 2024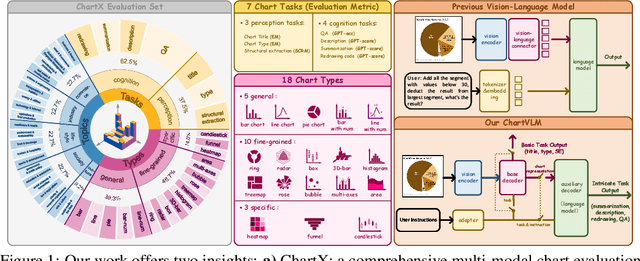
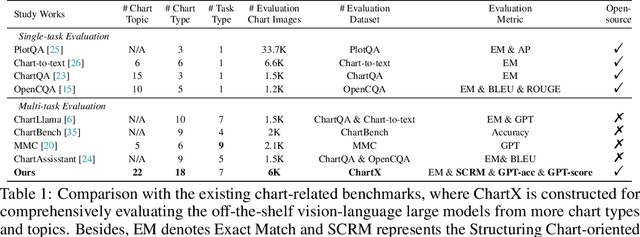
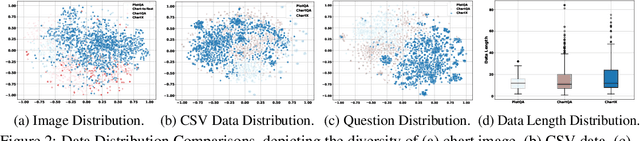
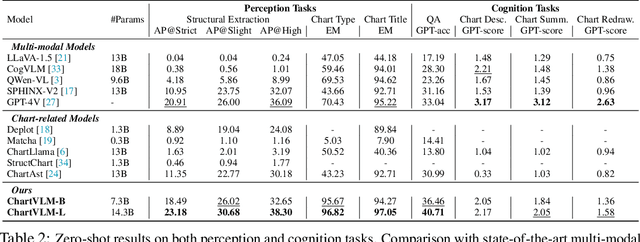
Recently, many versatile Multi-modal Large Language Models (MLLMs) have emerged continuously. However, their capacity to query information depicted in visual charts and engage in reasoning based on the queried contents remains under-explored. In this paper, to comprehensively and rigorously benchmark the ability of the off-the-shelf MLLMs in the chart domain, we construct ChartX, a multi-modal evaluation set covering 18 chart types, 7 chart tasks, 22 disciplinary topics, and high-quality chart data. Besides, we develop ChartVLM to offer a new perspective on handling multi-modal tasks that strongly depend on interpretable patterns, such as reasoning tasks in the field of charts or geometric images. We evaluate the chart-related ability of mainstream MLLMs and our ChartVLM on the proposed ChartX evaluation set. Extensive experiments demonstrate that ChartVLM surpasses both versatile and chart-related large models, achieving results comparable to GPT-4V. We believe that our study can pave the way for further exploration in creating a more comprehensive chart evaluation set and developing more interpretable multi-modal models. Both ChartX and ChartVLM are available at: https://github.com/UniModal4Reasoning/ChartVLM
Graph Out-of-Distribution Generalization via Causal Intervention
Feb 18, 2024



Out-of-distribution (OOD) generalization has gained increasing attentions for learning on graphs, as graph neural networks (GNNs) often exhibit performance degradation with distribution shifts. The challenge is that distribution shifts on graphs involve intricate interconnections between nodes, and the environment labels are often absent in data. In this paper, we adopt a bottom-up data-generative perspective and reveal a key observation through causal analysis: the crux of GNNs' failure in OOD generalization lies in the latent confounding bias from the environment. The latter misguides the model to leverage environment-sensitive correlations between ego-graph features and target nodes' labels, resulting in undesirable generalization on new unseen nodes. Built upon this analysis, we introduce a conceptually simple yet principled approach for training robust GNNs under node-level distribution shifts, without prior knowledge of environment labels. Our method resorts to a new learning objective derived from causal inference that coordinates an environment estimator and a mixture-of-expert GNN predictor. The new approach can counteract the confounding bias in training data and facilitate learning generalizable predictive relations. Extensive experiment demonstrates that our model can effectively enhance generalization with various types of distribution shifts and yield up to 27.4\% accuracy improvement over state-of-the-arts on graph OOD generalization benchmarks. Source codes are available at https://github.com/fannie1208/CaNet.