 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIAR: Modality Interaction and Alignment Representation Fuison for Multimodal Emotion
Jan 03, 2026Multimodal Emotion Recognition (MER) aims to perceive human emotions through three modes: language, vision, and audio. Previous methods primarily focused on modal fusion without adequately addressing significant distributional differences among modalities or considering their varying contributions to the task. They also lacked robust generalization capabilities across diverse textual model features, thus limiting performance in multimodal scenarios. Therefore, we propose a novel approach called Modality Interaction and Alignment Representation (MIAR). This network integrates contextual features across different modalities using a feature interaction to generate feature tokens to represent global representations of this modality extracting information from other modalities. These four tokens represent global representations of how each modality extracts information from others. MIAR aligns different modalities using contrastive learning and normalization strategies. We conduct experiments on two benchmarks: CMU-MOSI and CMU-MOSEI datasets, experimental results demonstrate the MIAR outperforms state-of-the-art MER methods.
EIR: Enhanced Image Representations for Medical Report Generation
Dec 29, 2025Generating medical reports from chest X-ray images is a critical and time-consuming task for radiologists, especially in emergencies. To alleviate the stress on radiologists and reduce the risk of misdiagnosis, numerous research efforts have been dedicated to automatic medical report generation in recent years. Most recent studies have developed methods that represent images by utilizing various medical metadata, such as the clinical document history of the current patient and the medical graphs constructed from retrieved reports of other similar patients. However, all existing methods integrate additional metadata representations with visual representations through a simple "Add and LayerNorm" operation, which suffers from the information asymmetry problem due to the distinct distributions between them. In addition, chest X-ray images are usually represented using pre-trained models based on natural domain images, which exhibit an obvious domain gap between general and medical domain images. To this end, we propose a novel approach called Enhanced Image Representations (EIR) for generating accurate chest X-ray reports. We utilize cross-modal transformers to fuse metadata representations with image representations, thereby effectively addressing the information asymmetry problem between them, and we leverage medical domain pre-trained models to encode medical images, effectively bridging the domain gap for image representation. Experimental results on the widely used MIMIC and Open-I datasets demonstrate the effectiveness of our proposed method.
Cluster-Based Generalized Additive Models Informed by Random Fourier Features
Dec 22, 2025Explainable machine learning aims to strike a balance between prediction accuracy and model transparency, particularly in settings where black-box predictive models, such as deep neural networks or kernel-based methods, achieve strong empirical performance but remain difficult to interpret. This work introduces a mixture of generalized additive models (GAMs) in which random Fourier feature (RFF) representations are leveraged to uncover locally adaptive structure in the data. In the proposed method, an RFF-based embedding is first learned and then compressed via principal component analysis. The resulting low-dimensional representations are used to perform soft clustering of the data through a Gaussian mixture model. These cluster assignments are then applied to construct a mixture-of-GAMs framework, where each local GAM captures nonlinear effects through interpretable univariate smooth functions. Numerical experiments on real-world regression benchmarks, including the California Housing, NASA Airfoil Self-Noise, and Bike Sharing datasets, demonstrate improved predictive performance relative to classical interpretable models. Overall, this construction provides a principled approach for integrating representation learning with transparent statistical modeling.
FlowDC: Flow-Based Decoupling-Decay for Complex Image Editing
Dec 12, 2025



With the surge of pre-trained text-to-image flow matching models, text-based image editing performance has gained remarkable improvement, especially for \underline{simple editing} that only contains a single editing target. To satisfy the exploding editing requirements, the \underline{complex editing} which contains multiple editing targets has posed as a more challenging task. However, current complex editing solutions: single-round and multi-round editing are limited by long text following and cumulative inconsistency, respectively. Thus, they struggle to strike a balance between semantic alignment and source consistency. In this paper, we propose \textbf{FlowDC}, which decouples the complex editing into multiple sub-editing effects and superposes them in parallel during the editing process. Meanwhile, we observed that the velocity quantity that is orthogonal to the editing displacement harms the source structure preserving. Thus, we decompose the velocity and decay the orthogonal part for better source consistency. To evaluate the effectiveness of complex editing settings, we construct a complex editing benchmark: Complex-PIE-Bench. On two benchmarks, FlowDC shows superior results compared with existing methods. We also detail the ablations of our module designs.
Frequency-Aware Vision-Language Multimodality Generalization Network for Remote Sensing Image Classification
Nov 13, 2025



The booming remote sensing (RS) technology is giving rise to a novel multimodality generalization task, which requires the model to overcome data heterogeneity while possessing powerful cross-scene generalization ability. Moreover, most vision-language models (VLMs) usually describe surface materials in RS images using universal texts, lacking proprietary linguistic prior knowledge specific to different RS vision modalities. In this work, we formalize RS multimodality generalization (RSMG) as a learning paradigm, and propose a frequency-aware vision-language multimodality generalization network (FVMGN) for RS image classification. Specifically, a diffusion-based training-test-time augmentation (DTAug) strategy is designed to reconstruct multimodal land-cover distributions, enriching input information for FVMGN. Following that, to overcome multimodal heterogeneity, a multimodal wavelet disentanglement (MWDis) module is developed to learn cross-domain invariant features by resampling low and high frequency components in the frequency domain. Considering the characteristics of RS vision modalities, shared and proprietary class texts is designed as linguistic inputs for the transformer-based text encoder to extract diverse text features. For multimodal vision inputs, a spatial-frequency-aware image encoder (SFIE) is constructed to realize local-global feature reconstruction and representation. Finally, a multiscale spatial-frequency feature alignment (MSFFA) module is suggested to construct a unified semantic space, ensuring refined multiscale alignment of different text and vision features in spatial and frequency domains. Extensive experiments show that FVMGN has the excellent multimodality generalization ability compared with state-of-the-art (SOTA) methods.
Sparse4DGS: 4D Gaussian Splatting for Sparse-Frame Dynamic Scene Reconstruction
Nov 10, 2025

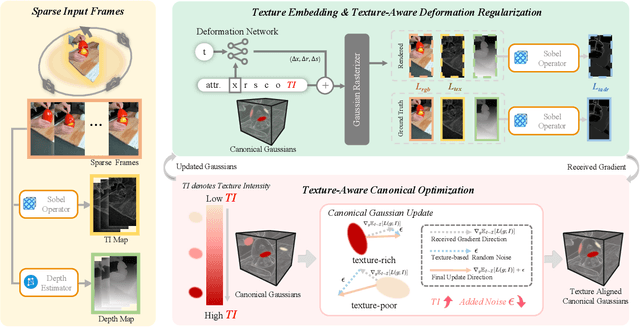
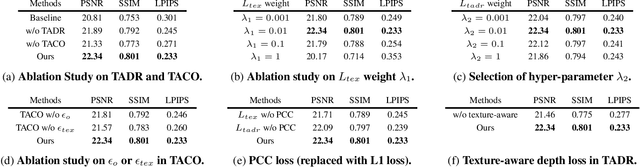
Dynamic Gaussian Splatting approaches have achieved remarkable performance for 4D scene reconstruction. However, these approaches rely on dense-frame video sequences for photorealistic reconstruction. In real-world scenarios, due to equipment constraints, sometimes only sparse frames are accessible. In this paper, we propose Sparse4DGS, the first method for sparse-frame dynamic scene reconstruction. We observe that dynamic reconstruction methods fail in both canonical and deformed spaces under sparse-frame settings, especially in areas with high texture richness. Sparse4DGS tackles this challenge by focusing on texture-rich areas. For the deformation network, we propose Texture-Aware Deformation Regularization, which introduces a texture-based depth alignment loss to regulate Gaussian deformation. For the canonical Gaussian field, we introduce Texture-Aware Canonical Optimization, which incorporates texture-based noise into the gradient descent process of canonical Gaussians. Extensive experiments show that when taking sparse frames as inputs, our method outperforms existing dynamic or few-shot techniques on NeRF-Synthetic, HyperNeRF, NeRF-DS, and our iPhone-4D datasets.
CoMo: Compositional Motion Customization for Text-to-Video Generation
Oct 27, 2025While recent text-to-video models excel at generating diverse scenes, they struggle with precise motion control, particularly for complex, multi-subject motions. Although methods for single-motion customization have been developed to address this gap, they fail in compositional scenarios due to two primary challenges: motion-appearance entanglement and ineffective multi-motion blending. This paper introduces CoMo, a novel framework for $\textbf{compositional motion customization}$ in text-to-video generation, enabling the synthesis of multiple, distinct motions within a single video. CoMo addresses these issues through a two-phase approach. First, in the single-motion learning phase, a static-dynamic decoupled tuning paradigm disentangles motion from appearance to learn a motion-specific module. Second, in the multi-motion composition phase, a plug-and-play divide-and-merge strategy composes these learned motions without additional training by spatially isolating their influence during the denoising process. To facilitate research in this new domain, we also introduce a new benchmark and a novel evaluation metric designed to assess multi-motion fidelity and blending. Extensive experiments demonstrate that CoMo achieves state-of-the-art performance, significantly advancing the capabilities of controllable video generation. Our project page is at https://como6.github.io/.
From Pixels to Views: Learning Angular-Aware and Physics-Consistent Representations for Light Field Microscopy
Oct 26, 2025Light field microscopy (LFM) has become an emerging tool in neuroscience for large-scale neural imaging in vivo, notable for its single-exposure volumetric imaging, broad field of view, and high temporal resolution. However, learning-based 3D reconstruction in XLFM remains underdeveloped due to two core challenges: the absence of standardized datasets and the lack of methods that can efficiently model its angular-spatial structure while remaining physically grounded. We address these challenges by introducing three key contributions. First, we construct the XLFM-Zebrafish benchmark, a large-scale dataset and evaluation suite for XLFM reconstruction. Second, we propose Masked View Modeling for Light Fields (MVN-LF), a self-supervised task that learns angular priors by predicting occluded views, improving data efficiency. Third, we formulate the Optical Rendering Consistency Loss (ORC Loss), a differentiable rendering constraint that enforces alignment between predicted volumes and their PSF-based forward projections. On the XLFM-Zebrafish benchmark, our method improves PSNR by 7.7% over state-of-the-art baselines.
From Bias to Balance: Exploring and Mitigating Spatial Bias in LVLMs
Sep 26, 2025



Large Vision-Language Models (LVLMs) have achieved remarkable success across a wide range of multimodal tasks, yet their robustness to spatial variations remains insufficiently understood. In this work, we present a systematic study of the spatial bias of LVLMs, focusing on how models respond when identical key visual information is placed at different locations within an image. Through a carefully designed probing dataset, we demonstrate that current LVLMs often produce inconsistent outputs under such spatial shifts, revealing a fundamental limitation in their spatial-semantic understanding. Further analysis shows that this phenomenon originates not from the vision encoder, which reliably perceives and interprets visual content across positions, but from the unbalanced design of position embeddings in the language model component. In particular, the widely adopted position embedding strategies, such as RoPE, introduce imbalance during cross-modal interaction, leading image tokens at different positions to exert unequal influence on semantic understanding. To mitigate this issue, we introduce Balanced Position Assignment (BaPA), a simple yet effective mechanism that assigns identical position embeddings to all image tokens, promoting a more balanced integration of visual information. Extensive experiments show that BaPA enhances the spatial robustness of LVLMs without retraining and further boosts their performance across diverse multimodal benchmarks when combined with lightweight fine-tuning. Further analysis of information flow reveals that BaPA yields balanced attention, enabling more holistic visual understanding.
A more efficient method for large-sample model-free feature screening via multi-armed bandits
Sep 19, 2025



We consider the model-free feature screening in large-scale ultrahigh-dimensional data analysis. Existing feature screening methods often face substantial computational challenges when dealing with large sample sizes. To alleviate the computational burden, we propose a rank-based model-free sure independence screening method (CR-SIS) and its efficient variant, BanditCR-SIS. The CR-SIS method, based on Chatterjee's rank correlation, is as straightforward to implement as the sure independence screening (SIS) method based on Pearson correlation introduced by Fan and Lv(2008), but it is significantly more powerful in detecting nonlinear relationships between variables. Motivated by the multi-armed bandit (MAB) problem, we reformulate the feature screening procedure to significantly reduce the computational complexity of CR-SIS. For a predictor matrix of size n \times p, the computational cost of CR-SIS is O(nlog(n)p), while BanditCR-SIS reduces this to O(\sqrt(n)log(n)p + nlog(n)). Theoretically, we establish the sure screening property for both CR-SIS and BanditCR-SIS under mild regularity conditions. Furthermore, we demonstrate the effectiveness of our methods through extensive experimental studies on both synthetic and real-world datasets. The results highlight their superior performance compared to classical screening methods, requiring significantly less computational time.