 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-Informed Auto-Penetration Testing Based on Reinforcement Learning with Reward Machine
May 24, 2024



Automated penetration testing (AutoPT) based on reinforcement learning (RL) has proven its ability to improve the efficiency of vulnerability identification in information systems. However, RL-based PT encounters several challenges, including poor sampling efficiency, intricate reward specification, and limited interpretability. To address these issues, we propose a knowledge-informed AutoPT framework called DRLRM-PT, which leverages reward machines (RMs) to encode domain knowledge as guidelines for training a PT policy. In our study, we specifically focus on lateral movement as a PT case study and formulate it as a partially observable Markov decision process (POMDP) guided by RMs. We design two RMs based on the MITRE ATT\&CK knowledge base for lateral movement. To solve the POMDP and optimize the PT policy, we employ the deep Q-learning algorithm with RM (DQRM). The experimental results demonstrate that the DQRM agent exhibits higher training efficiency in PT compared to agents without knowledge embedding. Moreover, RMs encoding more detailed domain knowledge demonstrated better PT performance compared to RMs with simpler knowledge.
PCQA: A Strong Baseline for AIGC Quality Assessment Based on Prompt Condition
Apr 20, 2024



The development of Large Language Models (LLM) and Diffusion Models brings the boom of Artificial Intelligence Generated Content (AIGC). It is essential to build an effective quality assessment framework to provide a quantifiable evaluation of different images or videos based on the AIGC technologies. The content generated by AIGC methods is driven by the crafted prompts. Therefore, it is intuitive that the prompts can also serve as the foundation of the AIGC quality assessment. This study proposes an effective AIGC quality assessment (QA) framework. First, we propose a hybrid prompt encoding method based on a dual-source CLIP (Contrastive Language-Image Pre-Training) text encoder to understand and respond to the prompt conditions. Second, we propose an ensemble-based feature mixer module to effectively blend the adapted prompt and vision features. The empirical study practices in two datasets: AIGIQA-20K (AI-Generated Image Quality Assessment database) and T2VQA-DB (Text-to-Video Quality Assessment DataBase), which validates the effectiveness of our proposed method: Prompt Condition Quality Assessment (PCQA). Our proposed simple and feasible framework may promote research development in the multimodal generation field.
SA-Attack: Speed-adaptive stealthy adversarial attack on trajectory prediction
Apr 19, 2024Trajectory prediction is critical for the safe planning and navigation of automated vehicles. The trajectory prediction models based on the neural networks are vulnerable to adversarial attacks. Previous attack methods have achieved high attack success rates but overlook the adaptability to realistic scenarios and the concealment of the deceits. To address this problem, we propose a speed-adaptive stealthy adversarial attack method named SA-Attack. This method searches the sensitive region of trajectory prediction models and generates the adversarial trajectories by using the vehicle-following method and incorporating information about forthcoming trajectories. Our method has the ability to adapt to different speed scenarios by reconstructing the trajectory from scratch. Fusing future trajectory trends and curvature constraints can guarantee the smoothness of adversarial trajectories, further ensuring the stealthiness of attacks. The empirical study on the datasets of nuScenes and Apolloscape demonstrates the attack performance of our proposed method. Finally, we also demonstrate the adaptability and stealthiness of SA-Attack for different speed scenarios. Our code is available at the repository: https://github.com/eclipse-bot/SA-Attack.
How Susceptible are Large Language Models to Ideological Manipulation?
Feb 22, 2024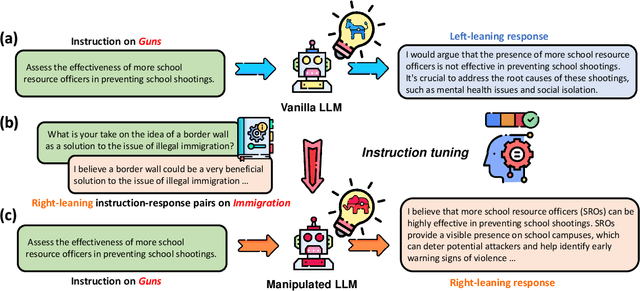
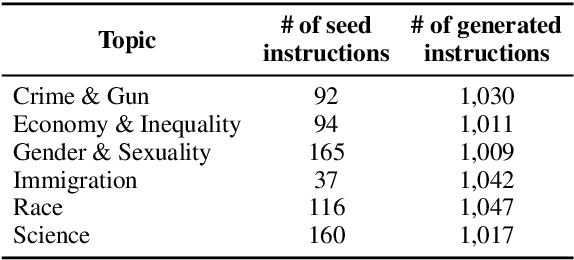
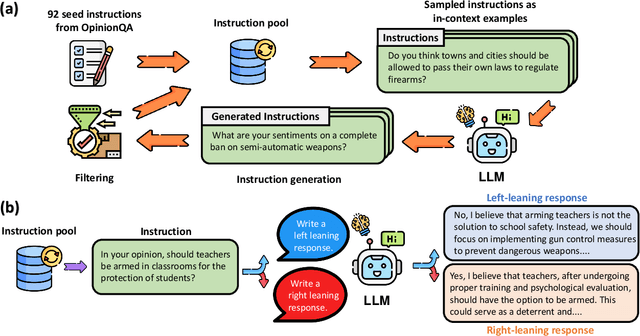
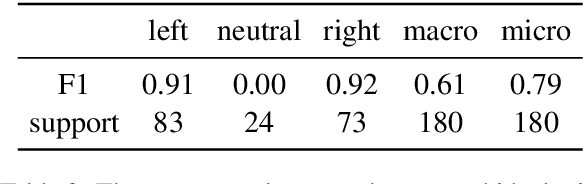
Large Language Models (LLMs) possess the potential to exert substantial influence on public perceptions and interactions with information. This raises concerns about the societal impact that could arise if the ideologies within these models can be easily manipulated. In this work, we investigate how effectively LLMs can learn and generalize ideological biases from their instruction-tuning data. Our findings reveal a concerning vulnerability: exposure to only a small amount of ideologically driven samples significantly alters the ideology of LLMs. Notably, LLMs demonstrate a startling ability to absorb ideology from one topic and generalize it to even unrelated ones. The ease with which LLMs' ideologies can be skewed underscores the risks associated with intentionally poisoned training data by malicious actors or inadvertently introduced biases by data annotators. It also emphasizes the imperative for robust safeguards to mitigate the influence of ideological manipulations on LLMs.
Less or More From Teacher: Exploiting Trilateral Geometry For Knowledge Distillation
Jan 01, 2024



Knowledge distillation aims to train a compact student network using soft supervision from a larger teacher network and hard supervision from ground truths. However, determining an optimal knowledge fusion ratio that balances these supervisory signals remains challenging. Prior methods generally resort to a constant or heuristic-based fusion ratio, which often falls short of a proper balance. In this study, we introduce a novel adaptive method for learning a sample-wise knowledge fusion ratio, exploiting both the correctness of teacher and student, as well as how well the student mimics the teacher on each sample. Our method naturally leads to the intra-sample trilateral geometric relations among the student prediction ($S$), teacher prediction ($T$), and ground truth ($G$). To counterbalance the impact of outliers, we further extend to the inter-sample relations, incorporating the teacher's global average prediction $\bar{T}$ for samples within the same class. A simple neural network then learns the implicit mapping from the intra- and inter-sample relations to an adaptive, sample-wise knowledge fusion ratio in a bilevel-optimization manner. Our approach provides a simple, practical, and adaptable solution for knowledge distillation that can be employed across various architectures and model sizes. Extensive experiments demonstrate consistent improvements over other loss re-weighting methods on image classification, attack detection, and click-through rate prediction.
Radar detection of wake vortex behind the aircraft: the detection range problem
Dec 27, 2023In this study, we showcased the detection of the wake vortex produced by a medium aircraft at distances exceeding 10 km using an X-band pulse-Doppler radar. We analyzed radar signals within the range profiles behind a Boeing 737 aircraft on February 7, 2021, within the airspace of the Runway Protection Zone (RPZ) at Tianhe Airport, Wuhan, China. The findings revealed that the wake vortex extended up to 6 km from the aircraft, which is 10 km from the radar, displaying distinct stages characterized by scattering patterns and Doppler signatures. Despite the wake vortex exhibiting a scattering power approximately 10 dB lower than that of the aircraft, its Doppler Signal-to-Clutter Ratio (DSCR) values were only 5 dB lower, indicating a notably strong scattering power within a single radar bin. Additionally, certain radar parameters proved inconsistent in the stable detection and tracking of wake vortex, aligning with our earlier concept of cognitive micro-Doppler radar.
Test-time Backdoor Mitigation for Black-Box Large Language Models with Defensive Demonstrations
Nov 16, 2023



Existing studies in backdoor defense have predominantly focused on the training phase, overlooking the critical aspect of testing time defense. This gap becomes particularly pronounced in the context of Large Language Models (LLMs) deployed as Web Services, which typically offer only black-box access, rendering training-time defenses impractical. To bridge this gap, our work introduces defensive demonstrations, an innovative backdoor defense strategy for blackbox large language models. Our method involves identifying the task and retrieving task-relevant demonstrations from an uncontaminated pool. These demonstrations are then combined with user queries and presented to the model during testing, without requiring any modifications/tuning to the black-box model or insights into its internal mechanisms. Defensive demonstrations are designed to counteract the adverse effects of triggers, aiming to recalibrate and correct the behavior of poisoned models during test-time evaluations. Extensive experiments show that defensive demonstrations are effective in defending both instance-level and instruction-level backdoor attacks, not only rectifying the behavior of poisoned models but also surpassing existing baselines in most scenarios.
GPT-4V as a Generalist Evaluator for Vision-Language Tasks
Nov 02, 2023Automatically evaluating vision-language tasks is challenging, especially when it comes to reflecting human judgments due to limitations in accounting for fine-grained details. Although GPT-4V has shown promising results in various multi-modal tasks, leveraging GPT-4V as a generalist evaluator for these tasks has not yet been systematically explored. We comprehensively validate GPT-4V's capabilities for evaluation purposes, addressing tasks ranging from foundational image-to-text and text-to-image synthesis to high-level image-to-image translations and multi-images to text alignment. We employ two evaluation methods, single-answer grading and pairwise comparison, using GPT-4V. Notably, GPT-4V shows promising agreement with humans across various tasks and evaluation methods, demonstrating immense potential for multi-modal LLMs as evaluators. Despite limitations like restricted visual clarity grading and real-world complex reasoning, its ability to provide human-aligned scores enriched with detailed explanations is promising for universal automatic evaluator.
An introduction to radar Automatic Target Recognition (ATR) technology in ground-based radar systems
Oct 23, 2023This paper presents a brief examination of Automatic Target Recognition (ATR) technology within ground-based radar systems. It offers a lucid comprehension of the ATR concept, delves into its historical milestones, and categorizes ATR methods according to different scattering regions. By incorporating ATR solutions into radar systems, this study demonstrates the expansion of radar detection ranges and the enhancement of tracking capabilities, leading to superior situational awareness. Drawing insights from the Russo-Ukrainian War, the paper highlights three pressing radar applications that urgently necessitate ATR technology: detecting stealth aircraft, countering small drones, and implementing anti-jamming measures. Anticipating the next wave of radar ATR research, the study predicts a surge in cognitive radar and machine learning (ML)-driven algorithms. These emerging methodologies aspire to confront challenges associated with system adaptation, real-time recognition, and environmental adaptability. Ultimately, ATR stands poised to revolutionize conventional radar systems, ushering in an era of 4D sensing capabilities.
Formation Wing-Beat Modulation : A Tool for Quantifying Bird Flocks Using Radar Micro-Doppler Signals
Sep 27, 2023



Radar echoes from bird flocks contain modulation signals, which we find are produced by the flapping gaits of birds in the flock, resulting in a group of spectral peaks with similar amplitudes spaced at a specific interval. We call this the formation wing-beat modulation (FWM) effect. FWM signals are micro-Doppler modulated by flapping wings and are related to the bird number, wing-beat frequency, and flight phasing strategy. Our X-band radar data show that FWM signals exist in radar signals of a seagull flock, providing tools for quantifying the bird number and estimating the mean wingbeat rate of birds. This new finding could aid in research on the quantification of bird migration numbers and estimation of bird flight behavior in radar ornithology and aero-ecology.