 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-purposing a modular origami manipulator into an adaptive physical computer for machine learning and robotic perception
May 05, 2025



Physical computing has emerged as a powerful tool for performing intelligent tasks directly in the mechanical domain of functional materials and robots, reducing our reliance on the more traditional COMS computers. However, no systematic study explains how mechanical design can influence physical computing performance. This study sheds insights into this question by repurposing an origami-inspired modular robotic manipulator into an adaptive physical reservoir and systematically evaluating its computing capacity with different physical configurations, input setups, and computing tasks. By challenging this adaptive reservoir computer to complete the classical NARMA benchmark tasks, this study shows that its time series emulation performance directly correlates to the Peak Similarity Index (PSI), which quantifies the frequency spectrum correlation between the target output and reservoir dynamics. The adaptive reservoir also demonstrates perception capabilities, accurately extracting its payload weight and orientation information from the intrinsic dynamics. Importantly, such information extraction capability can be measured by the spatial correlation between nodal dynamics within the reservoir body. Finally, by integrating shape memory alloy (SMA) actuation, this study demonstrates how to exploit such computing power embodied in the physical body for practical, robotic operations. This study provides a strategic framework for harvesting computing power from soft robots and functional materials, demonstrating how design parameters and input selection can be configured based on computing task requirements. Extending this framework to bio-inspired adaptive materials, prosthetics, and self-adaptive soft robotic systems could enable next-generation embodied intelligence, where the physical structure can compute and interact with their digital counterparts.
Adversarial Cooperative Rationalization: The Risk of Spurious Correlations in Even Clean Datasets
May 04, 2025



This study investigates the self-rationalization framework constructed with a cooperative game, where a generator initially extracts the most informative segment from raw input, and a subsequent predictor utilizes the selected subset for its input. The generator and predictor are trained collaboratively to maximize prediction accuracy. In this paper, we first uncover a potential caveat: such a cooperative game could unintentionally introduce a sampling bias during rationale extraction. Specifically, the generator might inadvertently create an incorrect correlation between the selected rationale candidate and the label, even when they are semantically unrelated in the original dataset. Subsequently, we elucidate the origins of this bias using both detailed theoretical analysis and empirical evidence. Our findings suggest a direction for inspecting these correlations through attacks, based on which we further introduce an instruction to prevent the predictor from learning the correlations. Through experiments on six text classification datasets and two graph classification datasets using three network architectures (GRUs, BERT, and GCN), we show that our method not only significantly outperforms recent rationalization methods, but also achieves comparable or even better results than a representative LLM (llama3.1-8b-instruct).
Retrieval-augmented in-context learning for multimodal large language models in disease classification
May 04, 2025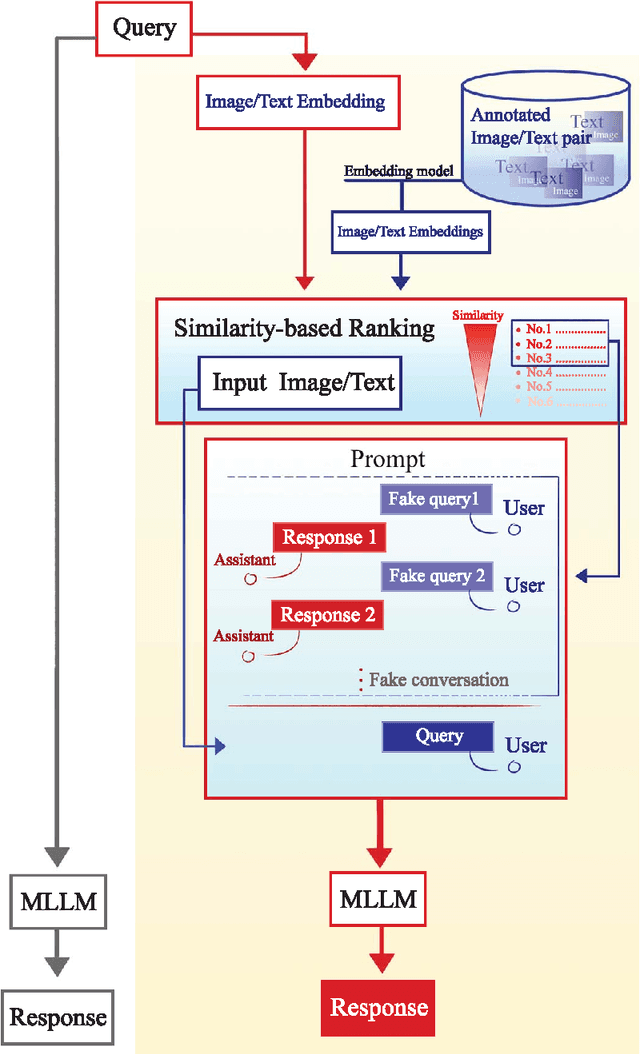
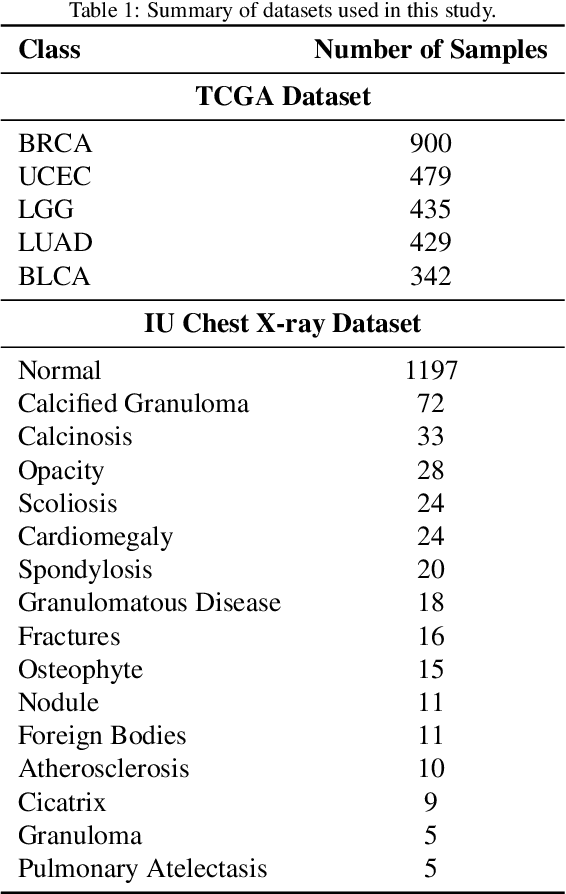
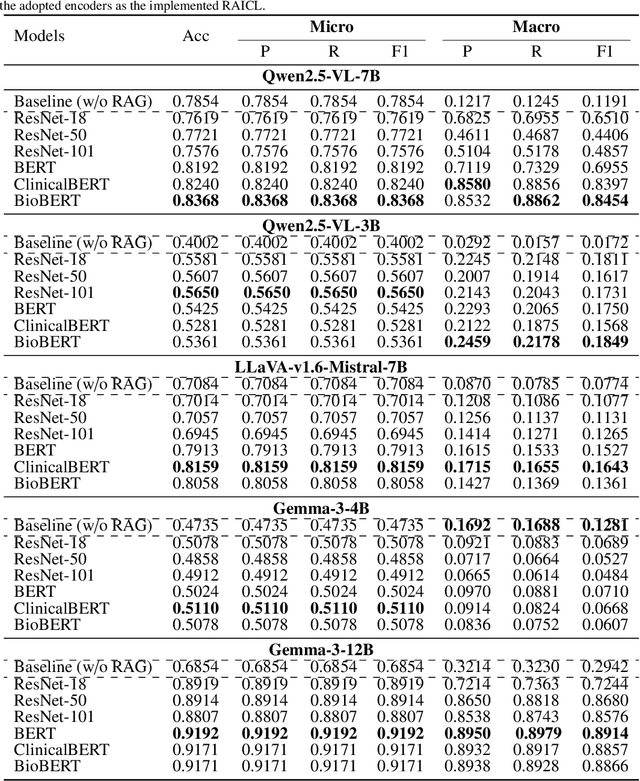
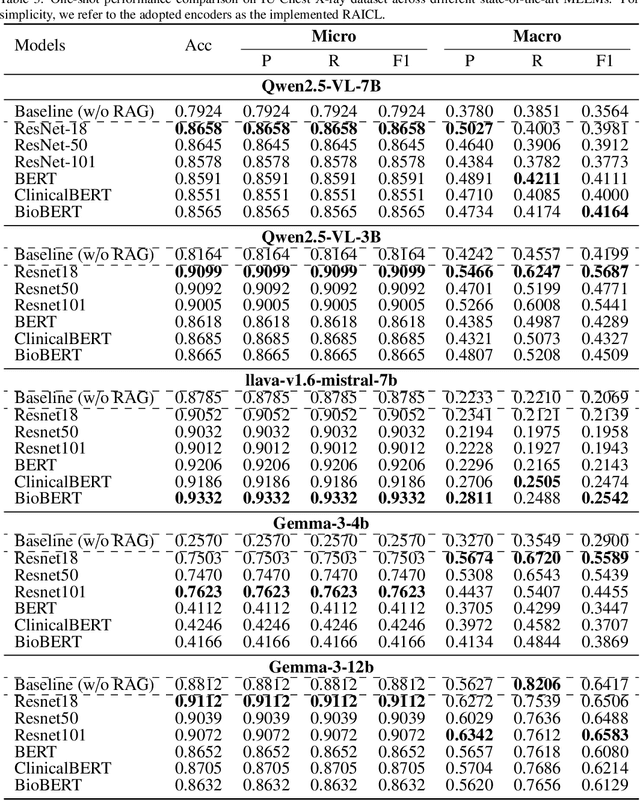
Objectives: We aim to dynamically retrieve informative demonstrations, enhancing in-context learning in multimodal large language models (MLLMs) for disease classification. Methods: We propose a Retrieval-Augmented In-Context Learning (RAICL) framework, which integrates retrieval-augmented generation (RAG) and in-context learning (ICL) to adaptively select demonstrations with similar disease patterns, enabling more effective ICL in MLLMs. Specifically, RAICL examines embeddings from diverse encoders, including ResNet, BERT, BioBERT, and ClinicalBERT, to retrieve appropriate demonstrations, and constructs conversational prompts optimized for ICL. We evaluated the framework on two real-world multi-modal datasets (TCGA and IU Chest X-ray), assessing its performance across multiple MLLMs (Qwen, Llava, Gemma), embedding strategies, similarity metrics, and varying numbers of demonstrations. Results: RAICL consistently improved classification performance. Accuracy increased from 0.7854 to 0.8368 on TCGA and from 0.7924 to 0.8658 on IU Chest X-ray. Multi-modal inputs outperformed single-modal ones, with text-only inputs being stronger than images alone. The richness of information embedded in each modality will determine which embedding model can be used to get better results. Few-shot experiments showed that increasing the number of retrieved examples further enhanced performance. Across different similarity metrics, Euclidean distance achieved the highest accuracy while cosine similarity yielded better macro-F1 scores. RAICL demonstrated consistent improvements across various MLLMs, confirming its robustness and versatility. Conclusions: RAICL provides an efficient and scalable approach to enhance in-context learning in MLLMs for multimodal disease classification.
Easz: An Agile Transformer-based Image Compression Framework for Resource-constrained IoTs
May 03, 2025Neural image compression, necessary in various machine-to-machine communication scenarios, suffers from its heavy encode-decode structures and inflexibility in switching between different compression levels. Consequently, it raises significant challenges in applying the neural image compression to edge devices that are developed for powerful servers with high computational and storage capacities. We take a step to solve the challenges by proposing a new transformer-based edge-compute-free image coding framework called Easz. Easz shifts the computational overhead to the server, and hence avoids the heavy encoding and model switching overhead on the edge. Easz utilizes a patch-erase algorithm to selectively remove image contents using a conditional uniform-based sampler. The erased pixels are reconstructed on the receiver side through a transformer-based framework. To further reduce the computational overhead on the receiver, we then introduce a lightweight transformer-based reconstruction structure to reduce the reconstruction load on the receiver side. Extensive evaluations conducted on a real-world testbed demonstrate multiple advantages of Easz over existing compression approaches, in terms of adaptability to different compression levels, computational efficiency, and image reconstruction quality.
Pushing the Limits of Low-Bit Optimizers: A Focus on EMA Dynamics
May 01, 2025



The explosion in model sizes leads to continued growth in prohibitive training/fine-tuning costs, particularly for stateful optimizers which maintain auxiliary information of even 2x the model size to achieve optimal convergence. We therefore present in this work a novel type of optimizer that carries with extremely lightweight state overloads, achieved through ultra-low-precision quantization. While previous efforts have achieved certain success with 8-bit or 4-bit quantization, our approach enables optimizers to operate at precision as low as 3 bits, or even 2 bits per state element. This is accomplished by identifying and addressing two critical challenges: the signal swamping problem in unsigned quantization that results in unchanged state dynamics, and the rapidly increased gradient variance in signed quantization that leads to incorrect descent directions. The theoretical analysis suggests a tailored logarithmic quantization for the former and a precision-specific momentum value for the latter. Consequently, the proposed SOLO achieves substantial memory savings (approximately 45 GB when training a 7B model) with minimal accuracy loss. We hope that SOLO can contribute to overcoming the bottleneck in computational resources, thereby promoting greater accessibility in fundamental research.
MF-LLM: Simulating Collective Decision Dynamics via a Mean-Field Large Language Model Framework
Apr 30, 2025
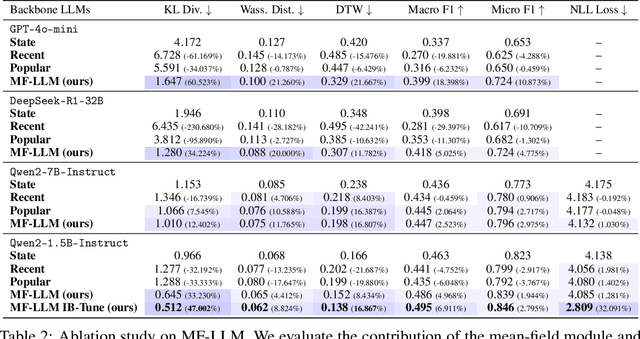


Simulating collective decision-making involves more than aggregating individual behaviors; it arises from dynamic interactions among individuals. While large language models (LLMs) show promise for social simulation, existing approaches often exhibit deviations from real-world data. To address this gap, we propose the Mean-Field LLM (MF-LLM) framework, which explicitly models the feedback loop between micro-level decisions and macro-level population. MF-LLM alternates between two models: a policy model that generates individual actions based on personal states and group-level information, and a mean field model that updates the population distribution from the latest individual decisions. Together, they produce rollouts that simulate the evolving trajectories of collective decision-making. To better match real-world data, we introduce IB-Tune, a fine-tuning method for LLMs grounded in the information bottleneck principle, which maximizes the relevance of population distributions to future actions while minimizing redundancy with historical data. We evaluate MF-LLM on a real-world social dataset, where it reduces KL divergence to human population distributions by 47 percent over non-mean-field baselines, and enables accurate trend forecasting and intervention planning. It generalizes across seven domains and four LLM backbones, providing a scalable foundation for high-fidelity social simulation.
MARFT: Multi-Agent Reinforcement Fine-Tuning
Apr 24, 2025



LLM-based Multi-Agent Systems have demonstrated remarkable capabilities in addressing complex, agentic tasks requiring multifaceted reasoning and collaboration, from generating high-quality presentation slides to conducting sophisticated scientific research. Meanwhile, RL has been widely recognized for its effectiveness in enhancing agent intelligence, but limited research has investigated the fine-tuning of LaMAS using foundational RL techniques. Moreover, the direct application of MARL methodologies to LaMAS introduces significant challenges, stemming from the unique characteristics and mechanisms inherent to LaMAS. To address these challenges, this article presents a comprehensive study of LLM-based MARL and proposes a novel paradigm termed Multi-Agent Reinforcement Fine-Tuning (MARFT). We introduce a universal algorithmic framework tailored for LaMAS, outlining the conceptual foundations, key distinctions, and practical implementation strategies. We begin by reviewing the evolution from RL to Reinforcement Fine-Tuning, setting the stage for a parallel analysis in the multi-agent domain. In the context of LaMAS, we elucidate critical differences between MARL and MARFT. These differences motivate a transition toward a novel, LaMAS-oriented formulation of RFT. Central to this work is the presentation of a robust and scalable MARFT framework. We detail the core algorithm and provide a complete, open-source implementation to facilitate adoption and further research. The latter sections of the paper explore real-world application perspectives and opening challenges in MARFT. By bridging theoretical underpinnings with practical methodologies, this work aims to serve as a roadmap for researchers seeking to advance MARFT toward resilient and adaptive solutions in agentic systems. Our implementation of the proposed framework is publicly available at: https://github.com/jwliao-ai/MARFT.
Plug-and-Play Physics-informed Learning using Uncertainty Quantified Port-Hamiltonian Models
Apr 24, 2025The ability to predict trajectories of surrounding agents and obstacles is a crucial component in many robotic applications. Data-driven approaches are commonly adopted for state prediction in scenarios where the underlying dynamics are unknown. However, the performance, reliability, and uncertainty of data-driven predictors become compromised when encountering out-of-distribution observations relative to the training data. In this paper, we introduce a Plug-and-Play Physics-Informed Machine Learning (PnP-PIML) framework to address this challenge. Our method employs conformal prediction to identify outlier dynamics and, in that case, switches from a nominal predictor to a physics-consistent model, namely distributed Port-Hamiltonian systems (dPHS). We leverage Gaussian processes to model the energy function of the dPHS, enabling not only the learning of system dynamics but also the quantification of predictive uncertainty through its Bayesian nature. In this way, the proposed framework produces reliable physics-informed predictions even for the out-of-distribution scenarios.
Decoupled Global-Local Alignment for Improving Compositional Understanding
Apr 23, 2025Contrastive Language-Image Pre-training (CLIP) has achieved success on multiple downstream tasks by aligning image and text modalities. However, the nature of global contrastive learning limits CLIP's ability to comprehend compositional concepts, such as relations and attributes. Although recent studies employ global hard negative samples to improve compositional understanding, these methods significantly compromise the model's inherent general capabilities by forcibly distancing textual negative samples from images in the embedding space. To overcome this limitation, we introduce a Decoupled Global-Local Alignment (DeGLA) framework that improves compositional understanding while substantially mitigating losses in general capabilities. To optimize the retention of the model's inherent capabilities, we incorporate a self-distillation mechanism within the global alignment process, aligning the learnable image-text encoder with a frozen teacher model derived from an exponential moving average. Under the constraint of self-distillation, it effectively mitigates the catastrophic forgetting of pretrained knowledge during fine-tuning. To improve compositional understanding, we first leverage the in-context learning capability of Large Language Models (LLMs) to construct about 2M high-quality negative captions across five types. Subsequently, we propose the Image-Grounded Contrast (IGC) loss and Text-Grounded Contrast (TGC) loss to enhance vision-language compositionally. Extensive experimental results demonstrate the effectiveness of the DeGLA framework. Compared to previous state-of-the-art methods, DeGLA achieves an average enhancement of 3.5% across the VALSE, SugarCrepe, and ARO benchmarks. Concurrently, it obtains an average performance improvement of 13.0% on zero-shot classification tasks across eleven datasets. Our code will be released at https://github.com/xiaoxing2001/DeGLA
ConformalNL2LTL: Translating Natural Language Instructions into Temporal Logic Formulas with Conformal Correctness Guarantees
Apr 22, 2025Linear Temporal Logic (LTL) has become a prevalent specification language for robotic tasks. To mitigate the significant manual effort and expertise required to define LTL-encoded tasks, several methods have been proposed for translating Natural Language (NL) instructions into LTL formulas, which, however, lack correctness guarantees. To address this, we introduce a new NL-to-LTL translation method, called ConformalNL2LTL, that can achieve user-defined translation success rates over unseen NL commands. Our method constructs LTL formulas iteratively by addressing a sequence of open-vocabulary Question-Answering (QA) problems with LLMs. To enable uncertainty-aware translation, we leverage conformal prediction (CP), a distribution-free uncertainty quantification tool for black-box models. CP enables our method to assess the uncertainty in LLM-generated answers, allowing it to proceed with translation when sufficiently confident and request help otherwise. We provide both theoretical and empirical results demonstrating that ConformalNL2LTL achieves user-specified translation accuracy while minimizing help rates.