 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-augmented in-context learning for multimodal large language models in disease classification
Paper and Code
May 04, 2025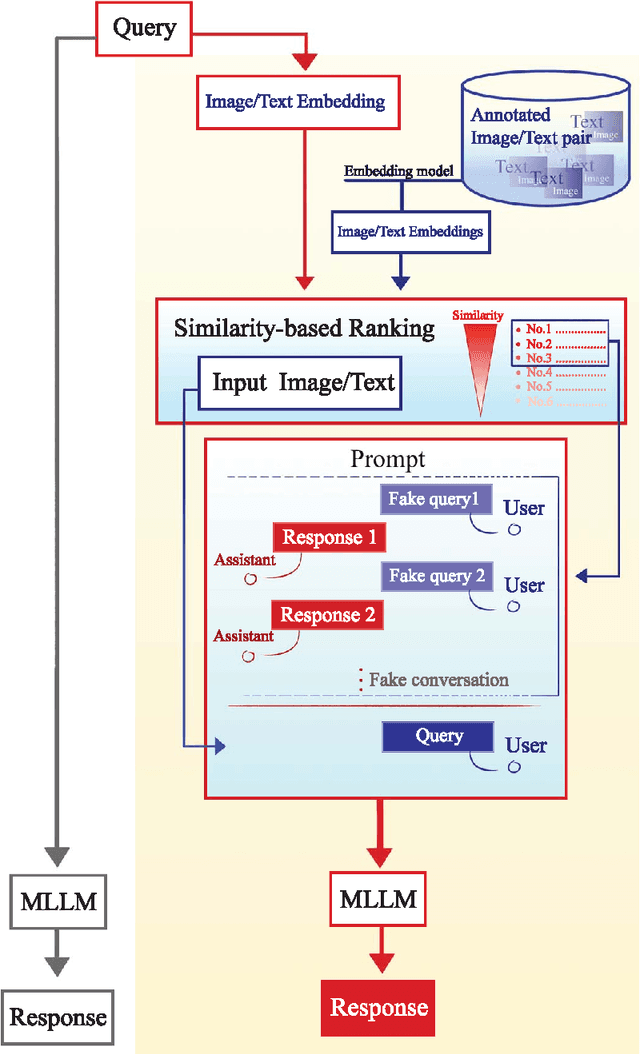
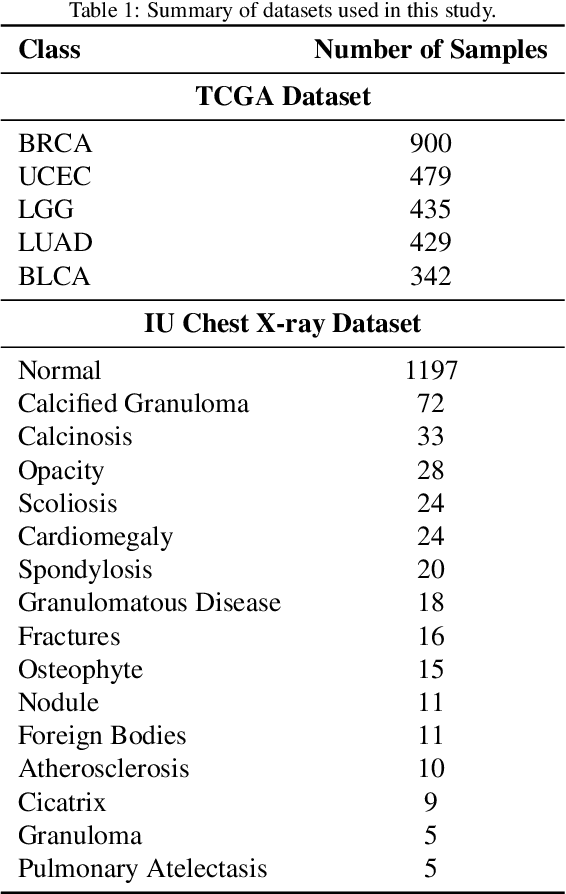
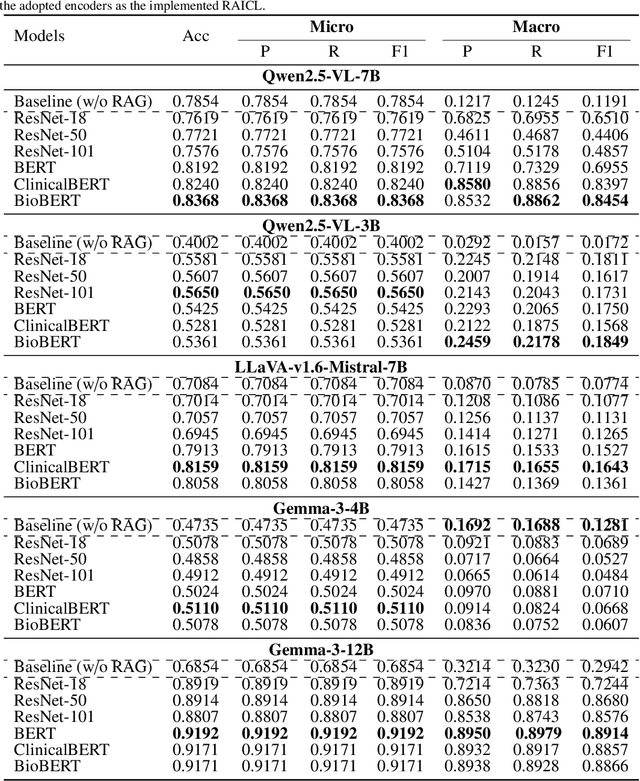
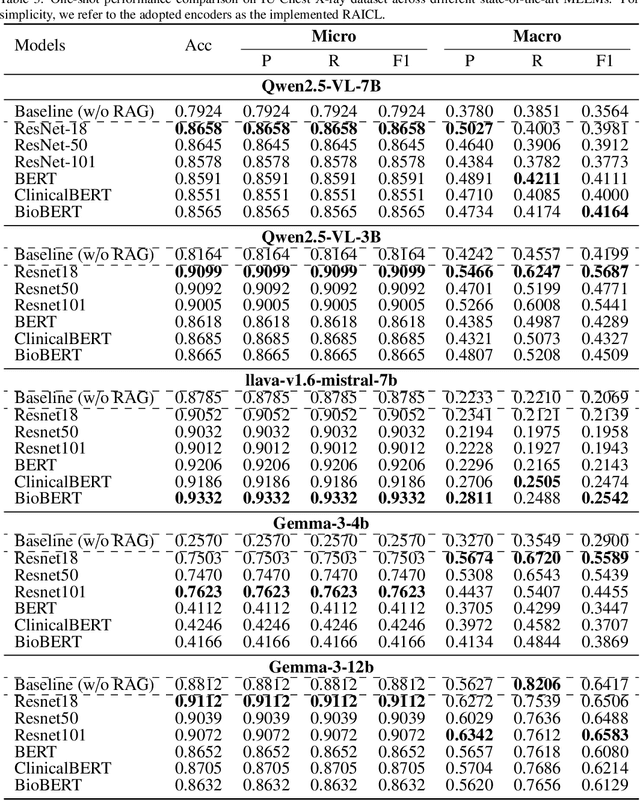
Objectives: We aim to dynamically retrieve informative demonstrations, enhancing in-context learning in multimodal large language models (MLLMs) for disease classification. Methods: We propose a Retrieval-Augmented In-Context Learning (RAICL) framework, which integrates retrieval-augmented generation (RAG) and in-context learning (ICL) to adaptively select demonstrations with similar disease patterns, enabling more effective ICL in MLLMs. Specifically, RAICL examines embeddings from diverse encoders, including ResNet, BERT, BioBERT, and ClinicalBERT, to retrieve appropriate demonstrations, and constructs conversational prompts optimized for ICL. We evaluated the framework on two real-world multi-modal datasets (TCGA and IU Chest X-ray), assessing its performance across multiple MLLMs (Qwen, Llava, Gemma), embedding strategies, similarity metrics, and varying numbers of demonstrations. Results: RAICL consistently improved classification performance. Accuracy increased from 0.7854 to 0.8368 on TCGA and from 0.7924 to 0.8658 on IU Chest X-ray. Multi-modal inputs outperformed single-modal ones, with text-only inputs being stronger than images alone. The richness of information embedded in each modality will determine which embedding model can be used to get better results. Few-shot experiments showed that increasing the number of retrieved examples further enhanced performance. Across different similarity metrics, Euclidean distance achieved the highest accuracy while cosine similarity yielded better macro-F1 scores. RAICL demonstrated consistent improvements across various MLLMs, confirming its robustness and versatility. Conclusions: RAICL provides an efficient and scalable approach to enhance in-context learning in MLLMs for multimodal disease classification.